1. Compter le nombre de lettres dans la chaîne:Quatre méthodes
string = "Hann Yang's id: boysoft2002"
print( sum(map(lambda x:x.isalpha(),string)) )
print( len([*filter(lambda x:x.isalpha(),string)]) )
print( sum(['a'<=s.lower()<='z' for s in string]) )
import re
print( len(re.findall(r'[a-z]', string, re.IGNORECASE)) )2. Nombre de jonquilles par ligne de code
[*filter(lambda x:x==sum(map(lambda n:int(n)**3,str(x))),range(100,1000))]Jonquille améliorée:La somme de ces nombres entiers est égale à l'entier lui - même..Par exemple::
1634 == 1^4 + 6^4 + 3^4 + 4^4
92727 == 9^5 + 2^5 + 7^5 + 2^5+7^5
548834 == 5^6 + 4^6 + 8^6+ 8^6+ 3^6 + 4^6
S'il te plaît.3~7Nombre de jonquilles,Ça marche.81Secondes:
[*filter(lambda x:x==sum(map(lambda n:int(n)**len(str(x)),str(x))),range(100,10_000_000))]
# [153, 370, 371, 407, 1634, 8208, 9474, 54748, 92727, 93084, 548834, 1741725, 4210818, 9800817, 9926315]N'essayez pas de calculer 7 Au - dessus de , C'est trop long .J'ai dépensé presque15 Une minute 3- Oui.8Nombre de jonquilles:
>>> t=time.time();[*filter(lambda x:x==sum(map(lambda n:int(n)**len(str(x)),str(x))),range(10_000_000,100_000_000))];print(time.time()-t)
[24678050, 24678051, 88593477]
858.79821443557743. Génération rapide de dictionnaires 、Échange de clés、Fusionner:
>>> dict.fromkeys('abcd',0) # Une seule valeur par défaut peut être définie
{'a': 0, 'b': 0, 'c': 0, 'd': 0}
>>> d = {}
>>> d.update(zip('abcd',range(4)))
>>> d
{'a': 0, 'b': 1, 'c': 2, 'd': 3}
>>> d = dict(enumerate('abcd'))
>>> d
{0: 'a', 1: 'b', 2: 'c', 3: 'd'}
>>> dict(zip(d.values(), d.keys()))
{'a': 0, 'b': 1, 'c': 2, 'd': 3}
>>> dict([v,k] for k,v in d.items())
{'a': 0, 'b': 1, 'c': 2, 'd': 3}
>>> d1 = dict(zip(d.values(), d.keys()))
>>>
>>> d = dict(enumerate('cdef'))
>>> d2 = dict(zip(d.values(), d.keys()))
>>> d2
{'c': 0, 'd': 1, 'e': 2, 'f': 3}
>>>
>>> {**d1, **d2}
{'a': 0, 'b': 1, 'c': 0, 'd': 1, 'e': 2, 'f': 3}
>>> {**d2, **d1}
{'c': 2, 'd': 3, 'e': 2, 'f': 3, 'a': 0, 'b': 1}
# La fusion est effectuée selon le dictionnaire précédent , Ces derniers ont aussi des clés qui sont écrasées , Rien n'a été ajouté 4. Fusion non superposée du Dictionnaire : Les valeurs dupliquées par la clé sont ajoutées ou en tuples 、Stockage collectif
dicta = {"a":3,"b":20,"c":2,"e":"E","f":"hello"}
dictb = {"b":3,"c":4,"d":13,"f":"world","G":"gg"}
dct1 = dicta.copy()
for k,v in dictb.items():
dct1[k] = dct1.get(k,0 if isinstance(v,int) else '')+v
dct2 = dicta.copy()
for k,v in dictb.items():
dct2[k] = (dct2[k],v) if dct2.get(k) else v
dct3 = {k:{v} for k,v in dicta.items()}
for k,v in dictb.items():
dct3[k] = set(dct3.get(k))|{v} if dct3.get(k) else {v} # Opérations d'union|
print(dicta, dictb, sep='\n')
print(dct1, dct2, dct3, sep='\n')
'''
{'a': 3, 'b': 20, 'c': 2, 'e': 'E', 'f': 'hello'}
{'b': 3, 'c': 4, 'd': 13, 'f': 'world', 'G': 'gg'}
{'a': 3, 'b': 23, 'c': 6, 'e': 'E', 'f': 'helloworld', 'd': 13, 'G': 'gg'}
{'a': 3, 'b': (20, 3), 'c': (2, 4), 'e': 'E', 'f': ('hello', 'world'), 'd': 13, 'G': 'gg'}
{'a': {3}, 'b': {3, 20}, 'c': {2, 4}, 'e': {'E'}, 'f': {'world', 'hello'}, 'd': {13}, 'G': {'gg'}}
'''5. La question de savoir si les trois côtés forment un triangle :
# Le jugement traditionnel : if a+b>c and b+c>a and c+a>b:
a,b,c = map(eval,input().split())
p = (a+b+c)/2
if p > max([a,b,c]):
s = (p*(p-a)*(p-b)*(p-c))**0.5
print('{:.2f}'.format(s))
else:
print('Ne peut pas former un triangle')
#Ou écrire:
p = a,b,c = [*map(eval,input().split())]
if sum(p) > 2*max(p):
p = sum(p)/2
s = (p*(p-a)*(p-b)*(p-c))**0.5
print('%.2f' % s)
else:
print('Ne peut pas former un triangle')6. Zen of PythonParmi les mots de, Top word Frequency 6 Pour dessiner des statistiques
import matplotlib.pyplot as plt
from this import s,d
import re
plt.rcParams['font.sans-serif'] = ['SimHei'] #Pour l'affichage normal des étiquettes chinoises
plt.rcParams['axes.unicode_minus'] = False #Utilisé pour afficher le signe négatif normalement
dat = ''
for t in s: dat += d.get(t,t)
dat = re.sub(r'[,|.|!|*|\-|\n]',' ',dat) # Remplacer toutes les ponctuations , Les abréviations comptent comme un mot it's、aren't...
lst = [word.lower() for word in dat.split()]
dct = {word:lst.count(word) for word in lst}
dct = sorted(dct.items(), key=lambda x:-x[1])
X,Y = [k[0] for k in dct[:6]],[v[1] for v in dct[:6]]
plt.figure('Statistiques de fréquence des mots',figsize=(12,5))
plt.subplot(1,3,1) # Lignes et numéros de séquence des sous - figures , Deux lignes et deux colonnes (2,2,1)
plt.title("Diagramme linéaire")
plt.ylim(0,12)
plt.plot(X, Y, marker='o', color="red", label="Légende 1")
plt.legend()
plt.subplot(1,3,2)
plt.title("Histogramme")
plt.ylim(0,12)
plt.bar(X, Y, label="Légende 2")
plt.legend()
plt.subplot(1,3,3)
plt.title("Diagramme circulaire")
exp = [0.3] + [0.2]*5 # Hors du Centre du cercle
plt.xlim(-4,4)
plt.ylim(-4,8)
plt.pie(Y, radius=3, labels=X, explode=exp,startangle=120, autopct="%3.1f%%", shadow=True, counterclock=True, frame=True)
plt.legend(loc="upper right") # Emplacement de la légende en haut à droite
plt.show()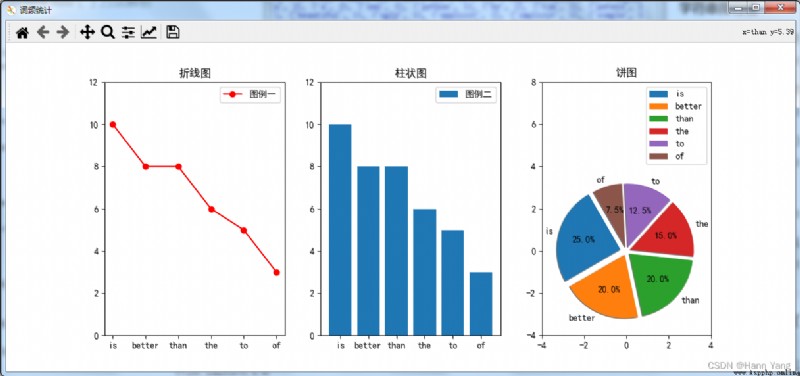
matplotlib.pyplot.pie Tableau des paramètres
Python Un petit tour de pinceau dans une chaîne de questions et réponses (Un.)
https://hannyang.blog.csdn.net/article/details/124935045
Python Un petit tour de pinceau dans une chaîne de questions et réponses (2.)
https://hannyang.blog.csdn.net/article/details/125026881
Python Un petit tour de pinceau dans une chaîne de questions et réponses (Trois)
https://hannyang.blog.csdn.net/article/details/125058178
Python Un petit tour de pinceau dans une chaîne de questions et réponses (Quatre)
https://hannyang.blog.csdn.net/article/details/125211774
Python Un petit tour de pinceau dans une chaîne de questions et réponses (Cinq)
https://hannyang.blog.csdn.net/article/details/125270812