前言
代碼部分
開發環境
先導入本次所需的模塊
請求數據
獲取請求的數據
解析數據
保存數據
前言Steam是由美國電子游戲商Valve於2003年9月12日推出的數字發行平台,被認為是計算機游戲界最大的數碼發行平台之一,Steam平台是全球最大的綜合性數字發行平台之一。玩家可以在該平台購買、下載、討論、上傳和分享游戲和軟件。

而每周的steam會開啟了一輪特惠,可以讓游戲打折,而玩家就會購買心儀的游戲
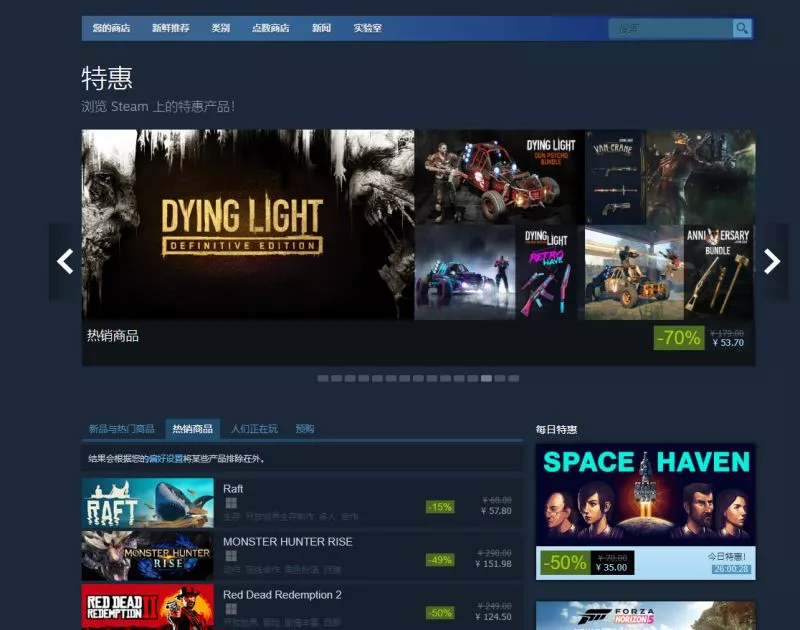
傳說每次有大折扣,無數的玩家會去購買游戲,可以讓G胖虧死

不過,由於種種原因,我總會錯過一些想玩的游戲的特惠價!!!
所以,我就在想,可不可以用Python收集steam所有每周特惠游戲的數據
代碼部分開發環境Python 3.8
Pycharm
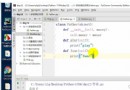
先導入本次所需的模塊import randomimport timeimport requestsimport parselimport csv模塊可以pycharm裡直接安裝,輸入pip install XXX(模塊名)就行
url = f'https://store.steampowered.com/contenthub/querypaginated/specials/TopSellers/render/?query=&start=1&count=15&cc=TW&l=schinese&v=4&tag='headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}response = requests.get(url=url, headers=headers)獲取請求的數據html_data = response.json()['results_html']print(html_data)這樣網頁源代碼就獲取到了
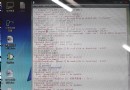
selector = parsel.Selector(html_data)lis = selector.css('a.tab_item')for li in lis: href = li.css('::attr(href)').get() title = li.css('.tab_item_name::text').get() tag_list = li.css('.tab_item_top_tags .top_tag::text').getall() tag = ''.join(tag_list) price = li.css('.discount_original_price::text').get() price_1 = li.css('.tab_item_discount .discount_final_price::text').get() discount = li.css('.tab_item_discount .discount_pct::text').get() print(title, tag, price, price_1, discount, href)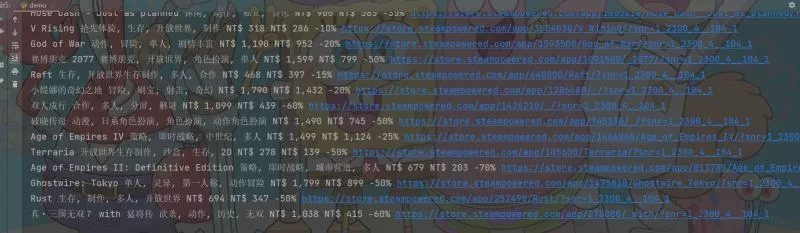
先把數據保存進字典裡面
dit = { '游戲': title, '標簽': tag, '原價': price, '售價': price_1, '折扣': discount, '詳情頁': href,}csv_writer.writerow(dit)最後保存到csv裡
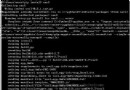
f = open('游戲_1.csv', mode='a', encoding='utf-8', newline='')csv_writer = csv.DictWriter(f, fieldnames=[ '游戲', '標簽', '原價', '售價', '折扣', '詳情頁',])csv_writer.writeheader()最後結果
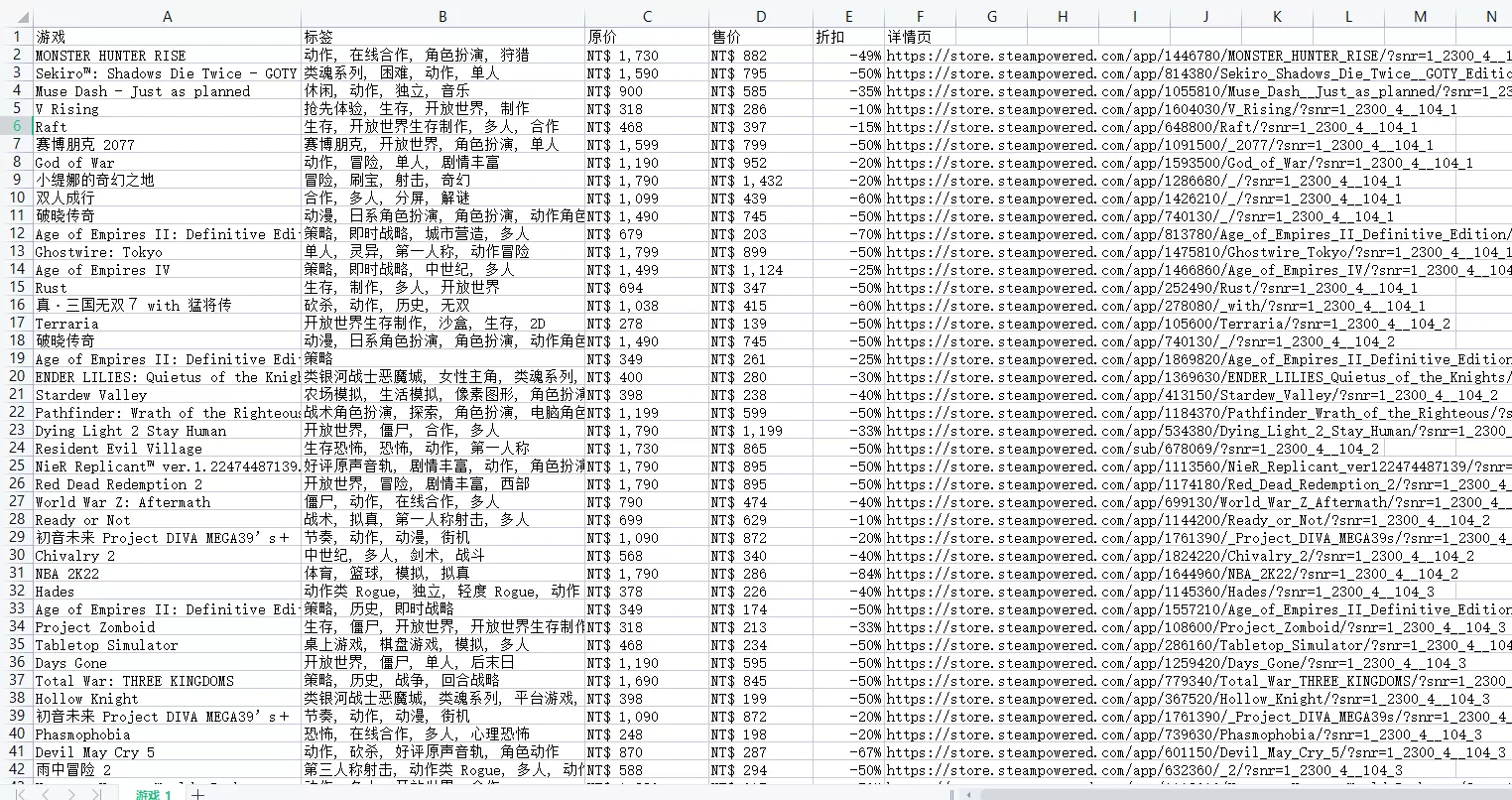
到此這篇關於利用Python實時獲取steam特惠游戲數據的文章就介紹到這了,更多相關Python獲取steam游戲數據內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!