我們知道,一般程序的執行順序是從上往下依次執行的。如果有兩個任務,一個任務執行時間需要5秒,另一個任務執行時間需要4秒,那麼按往常的做法需要9秒才能完成以上兩個任務。那能不能讓這兩個任務同時進行並在5秒內完成呢?當然可以,這裡引入我們今天的主角:線程——threading模塊。
多線程的出現是為了能夠幫助我們解決資源被霸占的問題,下面看看它的基本使用。
import time, datetime
import threading
def func():
"""這裡寫明線程需要執行的任務"""
# 獲取線程名稱並記錄任務啟動時間, thread實例對象可直接對象名.name獲取線程名
print(threading.current_thread().getName(), datetime.datetime.now())
# ------任務部分------
# 比如輸出一句hello,假設完成該任務需要兩秒的時間
print('hello~')
time.sleep(2)
# -------------------
# 記錄任務結束時間
print(threading.current_thread().getName(), datetime.datetime.now())
def func2():
"""這裡寫上第二個任務"""
print(threading.current_thread().getName(), datetime.datetime.now())
print('hi~')
# 假設輸出需要3秒時間
time.sleep(3)
print(threading.current_thread().getName(), datetime.datetime.now())
# 創建兩個線程,並綁定各自的任務,用target接收函數名注意沒有括號
thread1 = threading.Thread(target=func)
thread2 = threading.Thread(target=func2)
# 綁定完後就能有start啟動了
thread1.start()
thread2.start()
pycharm下的運行結果
C:\Users\17591\.virtualenvs\test\Scripts\python.exe C:/Users/17591/PycharmProjects/test/books.py
Thread-1 2022-06-20 18:00:54.397643
hello~
Thread-2 2022-06-20 18:00:54.397643
hi~
Thread-1 2022-06-20 18:00:56.403895
Thread-2 2022-06-20 18:00:57.405731
Process finished with exit code 0
可以看到,一個2秒一個3秒的任務只需3秒就完成了,說明這兩個任務確實是同時進行的。
命名
每個線程名默認是以 thread-xx 命名的,如果想自己定義的話,可以在創建實例對象時用name進行指明。
thread = threading.Thread(target=func,name="這是我的第一個線程")
傳遞參數
當我們調用函數需要傳遞參數時,在創建實例對象時用 args 或 kwargs 指明。
def func(name, age):
print(name, age)
thread = threading.Thread(target=func, name="這是我的第一個線程", kwargs={
"name": "lishuaige", 'age': 21})
thread.start() # 輸出 lishuaige 21
亦可寫成
thread = threading.Thread(target=func, name="這是我的第一個線程", args=('lishuaige',21))
Daemon線程
Daemon線程也叫守護線程。什麼是守護線程?看看別人怎麼說:守護線程–也稱“服務線程”,在 沒有用戶線程可服務時會自動離開。優先級:守護線程的優先級比較低,用於為系統中的其它對象和線程提供服務。
一般情況下,一段程序會等所有線程執行完畢後,才會關閉。就拿 pycharm 來說,執行完程序後,控制台會返回 Process finished with exit code 0 的字樣,這就標志著該程序已經執行完畢了。不同的是,如果Daemon線程存在的話,程序運行完後就算Daemon線程還有任務,也不會等它,直接關閉掉,返回 Process finished with exit code 0,隨之Daemon本身的任務也會關閉。
打個比方,幾個同學約好出去玩,大家都到齊了,唯獨daemon還在來的路上,等了好久好久,大伙們都等的不耐煩了,還是沒有來,於是一個朋友打了電話給daemon,哼,等了這麼久還沒來我們走了!隨後生氣的掛斷了電話,就出發了。daemon傷心的歎了口氣,哎,我去給你們買零食了…
簡單的說,如果有守護線程,那麼除守護線程外的所有線程執行完畢後,就會終止程序,守護線程的任務也會隨之關閉。
在python中均可將每個線程設置為守護線程。
import time, datetime
import threading
def func():
time.sleep(2)
print('這是守護線程')
thread = threading.Thread(target=lambda :print("這是線程"))
dae = threading.Thread(target=func)
dae.setDaemon(True) # True 為開啟守護線程,默認為False
dae.start()
thread.start()
pycharm輸出結果是
C:\Users\17591\.virtualenvs\test\Scripts\python.exe C:/Users/17591/PycharmProjects/test/books.py
這是線程
Process finished with exit code 0
通過 dae.setDaemon(True) 的命令將dae設置為了守護線程,因為執行完出守護線程外的線程後就會終止程序,所以“這是守護線程” 這條輸出語句並未成功執行。
join()
線程中的join()方法是用來保證該線程順利執行以及堵塞主線程用的。什麼是主線程?回顧一下我們之前寫的代碼,即使沒有導入threading模塊也能運行,其實這就是因為主線程在工作。主線程,相當於是執行總程序的線程。
join(timeout),timeout可以不寫,那樣的話就等該線程執行完後再執行主線程的代碼。如果寫的話,以秒為單位,表示堵塞多少秒,期間會運行除主線程外的所有已經(用start命令)啟動了的線程,當堵塞時間過去後繼續執行主線程的代碼。
import time, datetime
import threading
def func():
print("啟動", datetime.datetime.now())
time.sleep(2)
print("結束", datetime.datetime.now())
thread = threading.Thread(target=func)
the = threading.Thread(target=func)
the.start()
the.join(1)
thread.start()
thread.join(0.5)
pycharm運行結果是
C:\Users\17591\.virtualenvs\test\Scripts\python.exe C:/Users/17591/PycharmProjects/test/books.py
啟動 2022-06-20 21:04:47.814156
啟動 2022-06-20 21:04:48.826980
結束 2022-06-20 21:04:49.826345
結束 2022-06-20 21:04:50.834772
Process finished with exit code 0
因為thread線程沒有啟動,所以the線程發起的阻塞只有它自身一個線程在工作,阻塞完後thread線程啟動了,並發起0.5秒的阻塞,因為兩個線程都啟動了,所以該阻塞不會影響到他們,只影響到了主線程。最後三秒完成兩個兩秒的任務,期間因為阻塞,一個線程晚了一秒執行。
isAlive()
用於判斷線程是否在工作。
thread = threading.Thread(target=func)
thread.start()
thread.join()
threading.active_count()
目前工作的線程數,含主線程。注意threading為線程的模塊名。
thread = threading.Thread(target=func)
the = threading.Thread(target=func)
thread.start()
the.start()
print(threading.active_count()) # 3
threading.enumerate()
迭代出目前所有工作的線程。
print(threading.enumerate())
threading.current_thread()
獲取當前工作的線程。
自定義線程
如果你想自定義線程,那麼這裡同樣能夠滿足你。只需要繼承threading.Thread,調用它的__init__方法,最後在run函數中定義你的任務即可。
import time, datetime
import threading
class MyThread(threading.Thread):
def __init__(self, *args, **kwargs): # 最好帶上兩個萬能參數
super().__init__(*args, **kwargs)
def run(self):
print('hello')
time.sleep(2)
thread = MyThread()
thread.start()
# 或者thread.run()
其實,線程對象既能用start執行任務,也能用run執行任務。不同的是,run具有類似join的特性,需等待run任務執行完畢後再其進行後面的操作。另外,重寫的線程類中可以多次調用run方法,而原始的threading.thread類,僅能有一次run。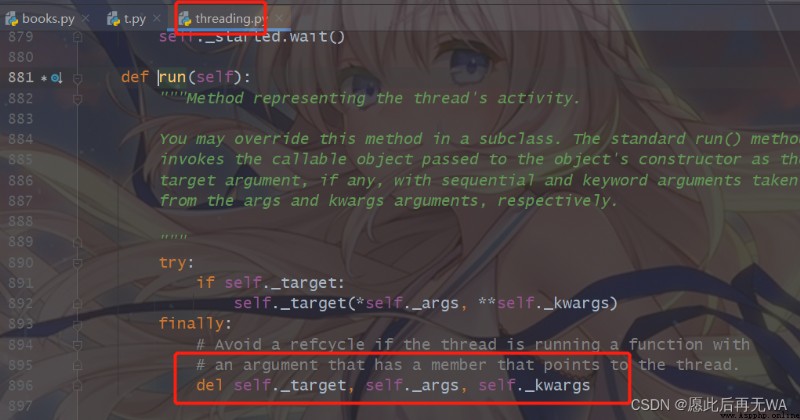
在原類中,當線程執行完畢後就會銷毀對象,回收資源。而我們重寫後如果沒有銷毀而且不重復利用的話,會造成資源不必要的浪費。
提到鎖,我們先聊一聊:不知大家有沒有留意前面“pycharm運行結果”這個詞出現過很多次,那麼你們知道我為什麼強調pycharm?因為,在pycharm或許輸出能夠工整一點,如果換原生的編譯器呢?
import time, datetime
import threading
def func():
"""這裡寫明線程需要執行的任務"""
# 獲取線程名稱並記錄任務啟動時間, thread實例對象可直接對象名.name獲取線程名
print(threading.current_thread().getName(), datetime.datetime.now())
# ------任務部分------
# 比如輸出一句hello,假設完成該任務需要兩秒的時間
print('hello~')
time.sleep(2)
# -------------------
# 記錄任務結束時間
print(threading.current_thread().getName(), datetime.datetime.now())
# 創建兩個線程,並綁定各自的任務,用target接收函數名注意沒有括號
thread1 = threading.Thread(target=func)
thread2 = threading.Thread(target=func)
# 綁定完後就能有start啟動了
thread1.start()
thread2.start()
以上方代碼為例,我們一起看看結果吧! 是不是覺得很不可思議?甚至python 的經典標志 >>> 先跑出來了,執行print(2)命令是可以正常輸出的;兩次輸出的時候有時候他們名字合並了甚至連換行符都沒有,而有時候又沒有合並,每次執行顯示的結果都會有不一樣的。實際上,各線程無法預期誰會先取得資源然後進行數據處理,所以會出現爭先恐後輸出的情況,這種現象稱為競速。為避免這種現象發生,鎖的概念也隨之到來,它的出現並非真要解決簡單的輸出問題,或許是因為線程相關的安全問題。我再舉個例子:
是不是覺得很不可思議?甚至python 的經典標志 >>> 先跑出來了,執行print(2)命令是可以正常輸出的;兩次輸出的時候有時候他們名字合並了甚至連換行符都沒有,而有時候又沒有合並,每次執行顯示的結果都會有不一樣的。實際上,各線程無法預期誰會先取得資源然後進行數據處理,所以會出現爭先恐後輸出的情況,這種現象稱為競速。為避免這種現象發生,鎖的概念也隨之到來,它的出現並非真要解決簡單的輸出問題,或許是因為線程相關的安全問題。我再舉個例子:
import time, datetime
import threading
MONEY = 100
def withdrawMoney(amount):
global MONEY
if MONEY >= amount:
# 假設服務器出現延遲,需要等待10毫秒才能繼續運行
time.sleep(0.01)
MONEY -= amount
print(f"已取 {
amount} 元,剩余 {
MONEY} 元")
else:
print("余額不足!")
# 創建兩個線程,並綁定各自的任務,用target接收函數名注意沒有括號
thread1 = threading.Thread(target=withdrawMoney,args=[100])
thread2 = threading.Thread(target=withdrawMoney,args=[50])
thread1.start()
thread2.start()
假設你微信有100塊錢,想看看能不能鑽個漏洞。在手機和電腦上同時登錄,並且同一時刻同時提現,這時候如果沒有使用鎖的話就會出現如下情況。 同一份代碼,我運行了三次,會出現多次不一樣的結果。
同一份代碼,我運行了三次,會出現多次不一樣的結果。
現在我們分析一下出現這些情況的原因。在上面的例子中,有兩個線程, 一個任務是取50元,另一個任務是取100元。當前一個線程進入判斷語句後,因為服務器出現延遲,所以等待了10毫秒,沒有執行體現的操作,那麼這時候的MONEY還是100元,幾乎同一時刻發生了線程調度切換,另外一個線程也走到了判斷語句,因為MONEY還是100元,所以,他也進去了,並沒有走余額不足的分支。問題來了,當短暫的服務器延遲過去後,因為兩個線程都進入到了提現的步驟上,所以都會進行減的操作,隨之也就出現了負數的情況。
那解決以上問題有什麼辦法呢?有同學說,想辦法把服務器的延遲問題解決!但偶爾出現服務器延遲是沒有辦法避免的。也有同學說看能不能把延遲問題放到判斷語句外面?這似乎可以,因為出現延遲一般是網絡問題。而像上面的邏輯計算,中間不會因為網絡問題而卡頓的。但就算延遲問題在外面,也有可能出現幾乎同一時刻兩個線程同時進入判斷語句內的情況。我將time.sleep()寫在判斷語句內層只是方便演示,確保兩個線程能夠百分百進入判斷語句內而已。所以,以上出現問題,需要用鎖來解決。
首先需要獲取lock對象
lock = threading.Lock()
獲得鎖
lock.acquire()
釋放鎖
lock.release()
在兩者之間寫入邏輯不可分割的代碼塊。
也能使用 with 方法。
import time, datetime
import threading
# 定義鎖
lock = threading.Lock()
MONEY = 100
def withdrawMoney(amount):
global MONEY
lock.acquire()
if MONEY >= amount:
# 假設服務器出現延遲,需要等待10毫秒才能繼續運行
time.sleep(0.01)
MONEY -= amount
print(f"已取 {
amount} 元,剩余 {
MONEY} 元")
else:
print("余額不足!")
lock.release()
# 創建兩個線程,並綁定各自的任務,用target接收函數名注意沒有括號
thread1 = threading.Thread(target=withdrawMoney,args=[100])
thread2 = threading.Thread(target=withdrawMoney,args=[50])
thread1.start()
thread2.start()
新建與終止線程都會在時間與性能上造成一定開銷,如果可以減少新建與終止線程的操作的話,可以在一定程度上提高代碼執行效率,而線程池,就是一套優化方案,其包含兩個概念,任務隊列和線程池。當有新任務出現時,會將任務放在任務隊列裡面,線程池中已經包含多個預先建立好的線程,這些線程會處理隊列中的任務,並將其彈出任務隊列。
我們結合代碼講解:
from concurrent.futures import ThreadPoolExecutor
def add(num):
num += 100
return num
lst = list(range(20))
with ThreadPoolExecutor() as pool:
res = (pool.map(add,lst))
for i in res:
print(i)
首先導入 ThreadPoolExecutor 線程池。定義一個加法函數,使用map方法,讓列表中的元素分別加上100,最後打印結果。ThreadPoolExecutor 模塊下的map方法與普通map方法的用法基本一致,都是讓一個函數分別作用在可迭代對象中的每個元素上。(若想繼續了解map用法可查看我的這篇文章https://blog.csdn.net/lishuaigell/article/details/124168814)

觀察結果可以發現,經過處理後的元素都是按順序輸出的。是偶然的嗎?不是,map方法處理的結果就是按順序輸出的。這意味著什麼?意味著有些先處理完後面任務的線程,因為順序的緣故,導致無法提交結果,需等待前面的任務完成,提交結果後才能繼續,所以被阻塞了!
為解決上述問題又有了新的方法, submit – as_completed。as_completed 需要搭配submit一起使用。
from concurrent.futures import ThreadPoolExecutor,as_completed
def add(num):
num += 100
return num
lst = list(range(20))
with ThreadPoolExecutor() as pool:
futures = (pool.submit(add,l) for l in lst)
for future in as_completed(futures):
print(future.result())
使用方法與前面類似,不同的是,submit 每次只能讓函數作用在一個元素上,而 map 每次能讓函數作用在每個元素上,另外,如果要獲取結果,要用result方法。
注意,線程池本質還是線程,多線程並不適合應對CPU密集型計算,只適合處理IO密集型計算。像上面的加法函數,因為數量級比較小看不出效果,如果式子稍微復雜點,數更大點的話處理時間會比單線程慢得多,因為它屬於cpu密集型計算。由於python有GIL(全局解釋器鎖,據說python3每個線程15毫秒就會檢查並釋放GIL)的存在,無論你有多少個cpu,同一時刻只會有一個cpu,一個線程在工作。如果計算量大,又出現多線程頻繁調度的話,只會提高cpu負荷和等待時間,造成反作用。就好比在家裡頻繁開關燈一樣,如果狂開狂關燈,不出三十個來回,那盞燈恐怕就頂不住了。
為充分利用cpu,python 也出台了相關的應對措施,多進程—— multiprocessing 模塊。
在下一篇《python 多進程》中,我會詳細講解 python multiprocessing 模塊的基本用法,歡迎關注。
 django. db. utils. OperationalError: (1049, “Unknown database ‘django‘“)
django. db. utils. OperationalError: (1049, “Unknown database ‘django‘“)
List of articles 1、 Problem de
 Python graduation design works are based on the django framework enterprise company website. The finished product (1) Development overview
Python graduation design works are based on the django framework enterprise company website. The finished product (1) Development overview
The whole project includes: op