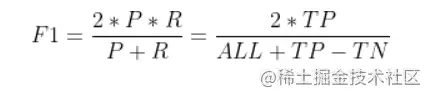This article has participated in 「 New people's creation ceremony 」 Activities , Start the road of nuggets creation together .
The purpose of performance measurement is to evaluate the pan China capability during the learning period , Performance metrics reflect task requirements , When comparing the pan China capabilities of different algorithms , Using different performance measures often leads to different evaluation results . Common measures have mean square error , Error rate and accuracy , Precision and recall, etc .
These two measures are applicable to binary tasks , It is also applicable to multi classification tasks . The error rate is the ratio of the number of samples with wrong classification to the total number of samples , Accuracy is the proportion of the number of samples correctly classified to the total number of samples .
Precision rate (precision) And recall (recall) Is for demand in Information Retrieval 、Web Search and other applications to evaluate the detection value with high fitness of performance measurement . For dichotomies , The combination of real category and algorithm prediction category can be divided into real examples (ture positive)、 False cases (false positive)、 True counter example (true negative)、 False counter example (false negative) Four situations . obviously TP+FP+TN+FN= Total number of samples . The classification result is confusion matrix :
 Precision rate P Defined as :
Precision rate P Defined as :
 Recall rate R Defined as :
Recall rate R Defined as :
 Generally speaking . When the accuracy is high , The recall rate is often low ; When the recall rate is high , Precision is often low . There are usually only a few simple tasks , Only then can the recall rate and precision rate be very high .
Generally speaking . When the accuracy is high , The recall rate is often low ; When the recall rate is high , Precision is often low . There are usually only a few simple tasks , Only then can the recall rate and precision rate be very high .
import matplotlib
from matplotlib import pyplot as plt
# true = [ Real group 1, Real group 2... Real group N],predict = [ Forecast group 1, Forecast group 2... Forecast group N]
def evaluation(true, predict):
num = len(true) # Make sure there are several groups
(TP, FP, FN, TN) = ([0] * num for i in range(4)) # Assign initial value to
for m in range(0, len(true)):
if (len(true[m]) != len(predict[m])): # The number of samples varies , There is obviously something wrong
print(" The sample number of the real results is inconsistent with the predicted results .")
else:
for i in range(0, len(true[m])): # Count each group of data separately
if (predict[m][i] == 1) and ((true[m][i] == 1)):
TP[m] += 1.0
elif (predict[m][i] == 1) and ((true[m][i] == 0)):
FP[m] += 1.0
elif (predict[m][i] == 0) and ((true[m][i] == 1)):
FN[m] += 1.0
elif (predict[m][i] == 0) and ((true[m][i] == 0)):
TN[m] += 1.0
(P, R) = ([0] * num for i in range(2))
for m in range(0, num):
if (TP[m] + FP[m] == 0):
P[m] = 0 # Prevent some denominators from being 0 The situation of
else:
P[m] = TP[m] / (TP[m] + FP[m])
if (TP[m] + FN[m] == 0):
R[m] = 0 # Prevent some denominators from being 0 The situation of
else:
R[m] = TP[m] / (TP[m] + FN[m])
plt.title("P-R")
plt.xlabel("P")
plt.ylabel("R")
#plt.plot(P, R)
#plt.show()
if __name__ == "__main__":
# A simple example
myarray_ture = numpy.random.randint(0, 2, (3, 100))
myarray_predict = numpy.random.randint(0, 2, (3, 100))
evaluation(myarray_ture,myarray_predict)
Here's how to use Iris Data set drawing P-R Curve code ( It mainly reflects its micro mutual exclusion )
from sklearn.model_selection import train_test_split
import numpy as np
iris = datasets.load_iris()
# Iris data import
x = iris.data
# Each column represents the length and width of sepals or petals , altogether 4 Column , Each column represents a measured iris plant ,iris.shape=(150,4)
y = iris.target
#target Is an array , Store data What kind of iris does each record belong to , So the length of the array is 150, There are only three different values
random_state = np.random.RandomState(0)
# Given status is 0 Is a set of random Numbers
n_samples, n_features = x.shape
x = np.c_[x, random_state.randn(n_samples, 200 * n_features)]
# Add merge generated feature test dataset
x_train, x_test, y_train, y_test = train_test_split(x[y < 2], y[y < 2],
test_size=0.25,
random_state=0)
# According to this model, a simple data classifier is trained
classifier = svm.LinearSVC(random_state=0)# Linear classification support vector machine
classifier.fit(x_train, y_train)
y_score = classifier.decision_function(x_test)
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
precision, recall, _ =precision_recall_curve(y_test, y_score)
plt.fill_between(recall, precision,color='b')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.0])
plt.xlim([0.0, 1.0])
plt.plot(recall, precision)
plt.title("Precision-Recall")
plt.show()
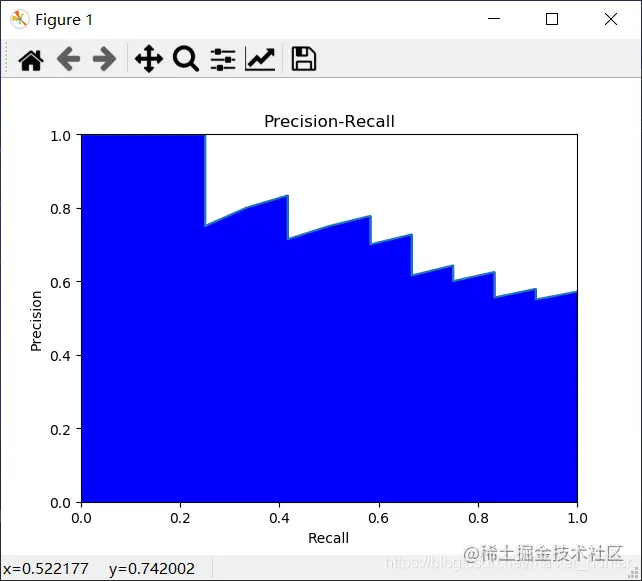 P-R The figure directly shows the recall rate of the learner on the sample 、 Precision rate . When comparing , If a rest area P-R The curve is completely changed by the curve of another learner “ encase ”, It can be asserted that the performance of the latter is better than the former . In order to obtain a more reasonable basis for judgment , Will adopt “ Balance point ”(Break-Even Point,BEP) Measure and compare the pan China performance of the algorithm . It is “ Precision rate = Recall rate ” The value of time . but BEP Or too simplistic , More commonly used F1 Measure (all Is the total number of samples ):
P-R The figure directly shows the recall rate of the learner on the sample 、 Precision rate . When comparing , If a rest area P-R The curve is completely changed by the curve of another learner “ encase ”, It can be asserted that the performance of the latter is better than the former . In order to obtain a more reasonable basis for judgment , Will adopt “ Balance point ”(Break-Even Point,BEP) Measure and compare the pan China performance of the algorithm . It is “ Precision rate = Recall rate ” The value of time . but BEP Or too simplistic , More commonly used F1 Measure (all Is the total number of samples ):