To know what it is, we must know what it is ,python There are really not many container objects in , Usually, we will use the corresponding containers according to our needs with great peace of mind , For variable length data list, Want to reuse set, Want to match quickly dict, For character processing str, But why can this effect be achieved ? For example, we use list When , Know that this thing can store various formats at will , Save integer type 、 floating-point 、 character string 、 You can even nest list Other containers , The underlying principle is implemented by arrays , Or a chain list ? Like our dictionary , Is the bottom layer an array or something else ? If it's something else like a hash table , Then how to realize the sequence arrangement of input data ? This time, we might as well analyze it layer by layer , Make a deduction . You can't chew too much , This time, let's start with list Analyze
The name is easily associated with other languages (C++、Java etc. ) The linked list in the standard library is confused , But in fact CPython The list of is not a list at all ( That's a little windy , It may be easier to understand in English :python Medium list Not what we learn list), stay CPython in , The list is implemented as A variable length array .
Look at the details ,Python The list in is made up of A contiguous array of references to other objects , The pointer to this array and its length are stored in a list header structure . It means , Every time you add or delete an element , An array made up of references requires this size ( Redistribution ). In the process of implementation ,Python When creating these arrays, the exponential allocation method is adopted , As a result, it is not necessary to change the size of the array every time , But because of this, the average complexity of adding or removing elements is low .
The result of this method is on the common linked list “ The price is very small ” Some of the other operations in Python The computational complexity is relatively high .
list.insert(i,item) Method to insert an element anywhere —— Complexity O(N)list.pop(i) or list.remove(value) Delete an element —— Complexity O(N) Let's take a look at list Source code of implementation , Source juice source flavor , Make a detailed evaluation . Let's find out first list Multiple inheritance from MutableSequence and Generic. Then we can read ,list Implementation of related embedded functions of , Such as append、pop、extend、insert And so on are actually realized through inheritance , Then we have to look for it MutableSequence and Generic The underlying implementation of these two classes , Only after solving these two classes , We can answer why list You can dynamically add data , And the complexity of deletion and insertion is not so good .
class list(MutableSequence[_T], Generic[_T]): @overload def __init__(self) -> None: ... @overload def __init__(self, iterable: Iterable[_T]) -> None: ... if sys.version_info >= (3,): def clear(self) -> None: ... def copy(self) -> List[_T]: ... def append(self, object: _T) -> None: ... def extend(self, iterable: Iterable[_T]) -> None: ... def pop(self, index: int = ...) -> _T: ... def index(self, object: _T, start: int = ..., stop: int = ...) -> int: ... def count(self, object: _T) -> int: ... def insert(self, index: int, object: _T) -> None: ... def remove(self, object: _T) -> None: ... def reverse(self) -> None: ... if sys.version_info >= (3,): def sort(self, *, key: Optional[Callable[[_T], Any]] = ..., reverse: bool = ...) -> None: ... else: def sort(self, cmp: Callable[[_T, _T], Any] = ..., key: Callable[[_T], Any] = ..., reverse: bool = ...) -> None: ... def __len__(self) -> int: ... def __iter__(self) -> Iterator[_T]: ... def __str__(self) -> str: ... __hash__: None # type: ignore @overload def __getitem__(self, i: int) -> _T: ... @overload def __getitem__(self, s: slice) -> List[_T]: ... @overload def __setitem__(self, i: int, o: _T) -> None: ... @overload def __setitem__(self, s: slice, o: Iterable[_T]) -> None: ... def __delitem__(self, i: Union[int, slice]) -> None: ... if sys.version_info < (3,): def __getslice__(self, start: int, stop: int) -> List[_T]: ... def __setslice__(self, start: int, stop: int, o: Sequence[_T]) -> None: ... def __delslice__(self, start: int, stop: int) -> None: ... def __add__(self, x: List[_T]) -> List[_T]: ... def __iadd__(self: _S, x: Iterable[_T]) -> _S: ... def __mul__(self, n: int) -> List[_T]: ... def __rmul__(self, n: int) -> List[_T]: ... if sys.version_info >= (3,): def __imul__(self: _S, n: int) -> _S: ... def __contains__(self, o: object) -> bool: ... def __reversed__(self) -> Iterator[_T]: ... def __gt__(self, x: List[_T]) -> bool: ... def __ge__(self, x: List[_T]) -> bool: ... def __lt__(self, x: List[_T]) -> bool: ... def __le__(self, x: List[_T]) -> bool: ...
This class actually comes from collections.abc.MutableSequence, In fact, it is the method of variable sequence in the so-called Abstract basic class .
Python There are two kinds of sequences of , Variable sequence and immutable sequence and provide two base classes for them Sequence and MutableSequence, These two base classes exist in built-in modules collections.abc in , And other common classes such as int、list And so on , These two base classes are Abstract base class . This involves a new concept of abstract base classes , What is an abstract base class ?
For abstract base classes , There is no need to pay too much attention at present , Just know that the abstract base class refers to Cannot instantiate a class that produces an instance object , We will discuss abstract base classes later .
Sequence and MutableSequence Are two abstract base classes , Therefore, these two classes cannot instantiate to generate instance objects , Then Sequence and MutableSequence What else do the two abstract base classes do ?
In fact, the role of an abstract base class is not to instantiate an instance object , Its function is more like defining a rule , Or the official saying is agreement , So when we want to create this type of object in the future , Require compliance with such rules or agreements . Now we need to understand the protocols of sequence types , It takes learning abc Module Sequence and MutableSequence Two classes .
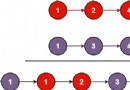
Sequence and MutableSequence The inheritance relationship between the two classes is as follows :
Bold in the figure indicates the abstract base class , Italics indicate abstract methods , It can be understood as There is no specific implementation method , The rest are the methods implemented in the abstract base class .
You can see , The inheritance relationship is not complicated , But there's a lot of information , This diagram should be kept in mind , Because this is very important for understanding sequence types . We see , Variable sequence MutableSequence Class inherits from immutable sequence Sequence class ,Sequence Class inherits two more classes Reversible and Collection,Collection And inherit from Container、 Iterable、Sized Three abstract base classes . Through this inheritance diagram , We should at least know , For standard immutable sequence types Sequence, At least the following methods should be implemented ( Follow these agreements ):
__contains__,__iter__,__len__,__reversed__,__getitem__,index,count
What exactly do these methods mean ? In front of list We can peek into the implementation source code of :
__contains__ Method , Means list Member operations can be performed , That is to use in and not in The effect of __iter__ Method , signify list Is an iterative object , Can be done for loop 、 unpacking 、 Generator expression and other operations __len__ Method , This means that you can use built-in functions len(). meanwhile , When judging a list When the Boolean value of , If list It didn't come true __bool__ Method , Will also try to call __len__ Method __reversed__ Method , It means that the reverse operation can be realized __getitem__ Method , This means that you can index and slice index and count Method , Then it means that the index and statistical frequency can be obtained according to conditions . The standard Sequence Type declares the above method , This means inheriting from Sequence Subclasses of , The object generated by its instantiation will be an iteratable object 、 have access to for loop 、 unpacking 、 Generator Expressions 、in、not in、 Indexes 、 section 、 Flip and many other operations . It also shows that , If we say that an object is an immutable sequence , Implies that the object is an iteratable object 、 have access to for loop 、.......
For standard variable sequences MutableSequence, We found that , In addition to implementing several methods in immutable sequences , At least the following methods need to be implemented ( Follow these agreements ):
__setitem__,__delitem__,insert,append,extend,pop,remove,__iadd__
What do these methods mean ? The same to Python Built in type list Take an example to illustrate :
__setitem__ Method , You can modify the elements in the list , Such as a = [1,2], Code a[0]=2 Is calling this method __delitem__,pop,remove Method , You can delete the elements in the list , Such as a = [1,2], Code del a[0] That's calling __delitem__ Method insert,append,extend Method , You can insert elements into the sequence __iadd__ Method , List can be assigned incrementally That is to say , For standard variable sequence types , In addition to performing immutable type query operations , The instance objects of its subclasses can execute Additions and deletions The operation of .
Abstract base class Sequence and MutableSequence It declares which methods should be implemented for a sequence type , Obviously , If a class inherits directly from Sequence class , The interior is also overloaded Sequence Seven methods in , So obviously this class must be a sequence type ,MutableSequence The same is true for subclasses of . Such is the case , But when we look at the list list、 Character sequence str、 Tuples tuple When the inheritance chain of , Found in its mro There is no Sequence and MutableSequence class , in other words , These built-in types do not directly inherit from these two abstract base classes , So why should we say at the beginning of the article that they are all sequence types ?
>>> list.__mro__ (<class 'list'>, <class 'object'>) >>> tuple.__mro__ (<class 'tuple'>, <class 'object'>) >>> str.__mro__ (<class 'str'>, <class 'object'>) >>> dict.__mro__ (<class 'dict'>, <class 'object'>)
Actually ,Python One of them is called The duck type Programming style . In this style , We don't pay much attention to the type of an object , It inherits from that type , It's about what it can do , Those methods are defined . If a thing looks like a duck , Walk like a duck , It sounds like a duck , So he's a duck .
Under this thought , If a class does not inherit directly from Sequence, But the internal implementation __contains__、__iter__、__len__、__reversed__、__getitem__、index,count Several ways , We can call it an immutable sequence . You don't even have to be so strict , Maybe you just need to implement __len__,__getitem__ Two methods can be called immutable sequence types . The same is true for variable sequences .
The idea of duck type runs through Python Object oriented programming is always .
This class is actually the implementation of generics , From the comments you can see , This is also an abstract base class , It is essentially used to implement multi type parameter input . For example list We can both deposit int, It can be str, It can also be list, It can also be dict Many different types of elements , This is essentially dependent on the inheritance of this class .
class Generic:
"""Abstract base class for generic types.
A generic type is typically declared by inheriting from
this class parameterized with one or more type variables.
For example, a generic mapping type might be defined as::
class Mapping(Generic[KT, VT]):
def __getitem__(self, key: KT) -> VT:
...
# Etc.
This class can then be used as follows::
def lookup_name(mapping: Mapping[KT, VT], key: KT, default: VT) -> VT:
try:
return mapping[key]
except KeyError:
return default
"""
__slots__ = ()
_is_protocol = False
@_tp_cache
def __class_getitem__(cls, params):
if not isinstance(params, tuple):
params = (params,)
if not params and cls is not Tuple:
raise TypeError(
f"Parameter list to {cls.__qualname__}[...] cannot be empty")
msg = "Parameters to generic types must be types."
params = tuple(_type_check(p, msg) for p in params)
if cls in (Generic, Protocol):
# Generic and Protocol can only be subscripted with unique type variables.
if not all(isinstance(p, TypeVar) for p in params):
raise TypeError(
f"Parameters to {cls.__name__}[...] must all be type variables")
if len(set(params)) != len(params):
raise TypeError(
f"Parameters to {cls.__name__}[...] must all be unique")
else:
# Subscripting a regular Generic subclass.
_check_generic(cls, params, len(cls.__parameters__))
return _GenericAlias(cls, params)
def __init_subclass__(cls, *args, **kwargs):
super().__init_subclass__(*args, **kwargs)
tvars = []
if '__orig_bases__' in cls.__dict__:
error = Generic in cls.__orig_bases__
else:
error = Generic in cls.__bases__ and cls.__name__ != 'Protocol'
if error:
raise TypeError("Cannot inherit from plain Generic")
if '__orig_bases__' in cls.__dict__:
tvars = _collect_type_vars(cls.__orig_bases__)
# Look for Generic[T1, ..., Tn].
# If found, tvars must be a subset of it.
# If not found, tvars is it.
# Also check for and reject plain Generic,
# and reject multiple Generic[...].
gvars = None
for base in cls.__orig_bases__:
if (isinstance(base, _GenericAlias) and
base.__origin__ is Generic):
if gvars is not None:
raise TypeError(
"Cannot inherit from Generic[...] multiple types.")
gvars = base.__parameters__
if gvars is not None:
tvarset = set(tvars)
gvarset = set(gvars)
if not tvarset <= gvarset:
s_vars = ', '.join(str(t) for t in tvars if t not in gvarset)
s_args = ', '.join(str(g) for g in gvars)
raise TypeError(f"Some type variables ({s_vars}) are"
f" not listed in Generic[{s_args}]")
tvars = gvars
cls.__parameters__ = tuple(tvars) As a common data structure , It is used as an array in many scenarios , I may feel that list It is nothing more than a dynamic array , It's like C++ Medium vector perhaps Go Medium slice equally . From the implementation of the source code , We can also see that list Inherit MutableSequence And it has the effect of generics , But it can be asserted that list Is it a dynamic array ?
Let's consider a simple question ,Python Medium list Allows us to store different types of data , Since the types are different , The memory footprint is different , How are data objects of different sizes " Deposit in " In the array ?
We can store a string in the array respectively , A plastic surgery , And a dictionary object , If it is an array implementation , You need to store the data in the adjacent memory space , And index access becomes a very difficult thing , After all, we can't guess the size of each element , Thus, the desired element position cannot be located .
Is it realized through the linked list structure ? After all, linked lists support dynamic adjustment , With the help of pointers, different types of data can be referenced , For example, the linked list structure in the following figure . But in this case, when using subscript index data , You need to rely on traversal to find ,O(n) The time complexity of access efficiency is too low .
But for the use of linked lists , The system overhead is also large , After all, in addition to maintaining local data pointers for each data item , And maintain a next The pointer , Therefore, additional allocation is required 8 Bytes of data , At the same time, the dispersity of the linked list makes it impossible to use it like an array CPU Cache to efficiently execute data reading and writing .
Let's discuss it again at this time list The internal implementation of this structure , My next deduction is based on CPython To the , The implementation syntax of different languages should be different , But the ideas are similar .
Python Medium list The implementation of data structure is simpler and purer than expected , The array memory continuity access mode is reserved , Only each node does not store actual data , But the corresponding data The pointer , Store and access data items in the form of an array of pointers , The corresponding structure is shown in the following figure :
The details of the implementation can be seen from its Python Source code found in , The definition is as follows :
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject; Inside list The implementation of is a C Structure , In this structure ob_item It's an array of Pointers , Stored pointer data of all objects ,allocated Is the amount of memory allocated , PyObject_VAR_HEAD Is a macro extension that contains more extended properties for managing arrays , Such as reference count and array size .
Since it is a dynamic array , There is bound to be a problem , That is, how to manage capacity , Most programming languages use dynamic adjustment strategies for such structures , That is, when the storage capacity reaches a certain threshold , Expand capacity , When the storage capacity is below a certain threshold , Reduce capacity . It's simple , But it's not that easy to implement , When is the expansion , How much , When to perform recycling , How much free capacity must be reclaimed each time , These are all issues that need to be clarified in the implementation process .
about Python in list The dynamic adjustment rule procedure is defined as follows : When the additional data capacity is full , Calculate the reallocated space size in the following way , Create a new array , And copy all the data into the new array . This is a strategy with relatively slow data growth , When reclaiming, the policy is executed when the capacity is half idle , Get the new reduced capacity size . In fact, this method is very similar to TCP Sliding window mechanism
new_allocated = (newsize >> 3) + (newsize < 9 ? 3 : 6); new_allocated += newsize // 0, 4, 8, 16, 25, 35, 46, 58, 72, 88, …
Suppose we use one of the simplest strategies : Double the excess capacity , Less than half the capacity is reduced by times . What's wrong with this strategy ? Imagine an insert when the capacity is full , The element is deleted , Alternate multiple times , The array data will be copied and recycled as a whole , There is no performance to speak of .
Next , Let's see list Several common operations of data structure . The first is list On the implementation append The operation of , This function adds elements to list Tail of . Notice that this is Pointer data is appended to the tail , Not the actual element .
test = list()
test.append("hello yerik")Add a string to the list :test.append("hello yerik") What happened ? In fact, the underlying C function app1().
arguments: list object, new element returns: 0 if OK, -1 if not app1: n = size of list call list_resize() to resize the list to size n+1 = 0 + 1 = 1 list[n] = list[0] = new element return 0
For an empty list, The size of the array is 0, To be able to insert elements , We need to expand the capacity of the array , Adjust the size according to the above calculation formula . For example, there is only one element , that newsize = 1, Calculated new_allocated = 3 + 1 = 4 , After successfully inserting the element , We don't need to reallocate new space until we insert the fifth element , To avoid frequent calls list_resize() function , Improve program performance .
We try to continue adding more elements to the list , When we insert elements "abc" When , Its internal array size is not large enough to hold the element , Execute a new round of dynamic capacity expansion , here newsize = 5 , new_allocated = 3 + 5 = 8
>>> test.append(520)
>>> test.append(dict())
>>> test.append(list())
>>> test.append("abc")
>>> test
['hello yerik', 520, {}, [], 'abc']The data storage space distribution after inserting is shown in the following figure :
In the list offset 2 Insert the new element in the position of , Integers 5:test.insert(1,2.33333333), Internal calls ins1() function .
arguments: list object, where, new element returns: 0 if OK, -1 if not ins1: resize list to size n+1 = 5 -> 4 more slots will be allocated starting at the last element up to the offset where, right shift each element set new element at offset where return 0
python Realized insert Function takes two parameters , The first is to specify the insertion location , The second is the element object . The middle insertion will cause the element after the position to be shifted , Since it is a stored pointer, the actual element does not need to be shifted , Just move the pointer .
>>> test.insert(2,2.33333333)
>>> test
['hello yerik', 520, 2.33333333, {}, [], 'abc']Insert the element as a string object , Create the string and get its pointer (ptr5), Store it in the index as 2 In the array position of , And move the other subsequent elements to a position respectively ,insert Function call completed . It is precisely because of the need to “ Check the expansion ” Why , As a result, the complexity of the operation reaches O(n), Instead of the linked list O(1)
Take out the last element of the list namely l.pop(), Called listpop() function . stay listpop() The function is called list_resize function , If the element usage is less than half , The idle capacity is recycled .
arguments: list object returns: element popped listpop: if list empty: return null resize list with size 5 - 1 = 4. 4 is not less than 8/2 so no shrinkage set list object size to 4 return last element
In the list pop The average complexity of the operation is O(1). However, the storage space size may need to be modified , This leads to increased complexity
>>> test.pop()
'abc'
>>> test.pop()
[]
>>> test.pop()
{}
>>> test
['hello yerik', 520, 2.33333333]The element at the end is recycled , Pointer clear , At this time, the length is 5, Capacity of 8, Therefore, there is no need to implement any recycling strategy . When we continue to execute three times pop Make its length become 3 after , At this time, the usage is less than half of the capacity , A recycling policy needs to be implemented . The recycling method is also to use the above formula for processing , For example, the new size here is 3, Then the returned capacity is 3+3 = 6 , Not all free space is reclaimed .
pop The operation of also needs to be checked and reduced , Therefore, the complexity is O(n)
remove The function specifies the element to be deleted , This element can be anywhere in the list . So every time remove Must be First, traverse the data items in turn , Match , Until the corresponding element position is found . Deleting may result in the migration of some elements .Remove The overall time complexity of the operation is O(n).
>>> test ['hello yerik', 520, 2.33333333] >>> test.remove(520) >>> test ['hello yerik', 2.33333333]
In fact, for Python Dynamic adjustment of data structure like list , It also exists in other languages , But you may not realize it in your daily use , Understand the dynamic adjustment rules , We can allocate enough space by, for example, manually , To reduce the migration cost caused by its dynamic allocation , Make the program run more efficiently .
In addition, if you know in advance that the data types stored in the list are the same , For example, they are all integer or character types , Consider using arrays library , perhaps numpy library , Both provide a more direct array memory storage model , Instead of the above pointer reference model , Therefore, it will be more efficient in terms of access and storage efficiency .