最近遇到一個bug,是在老代碼中,多年用下來都沒事,但是新增業務需求就遇到問題了。經過排除,發現是由於itertools.groupby的用法與想象中不一樣,至少與我熟知的pandas.groupby不太一樣。在網上沒看到相關的比較,於是自己寫一個異同對比。
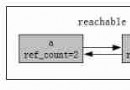
# itertools.groupby
from itertools import groupby
a = groupby([1,1,2,3])
for i,j in a:
print(i,' ',len(list(j)))
# pandas.groupby
import pandas
b = pandas.Series([0,1,2,3],index=[1,1,2,3],name='b').groupby(level=0,)
b.apply(lambda x:len(x))
能看出兩者都是基於一定規則的分組,但是當數據有序時,兩者的分組結果是相近的。
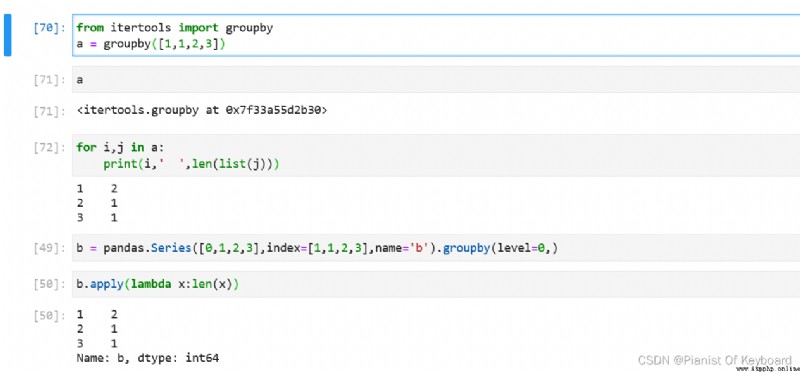
# itertools.groupby
from itertools import groupby
a = groupby([1,2,3,1])
for i,j in a:
print(i,' ',len(list(j)))
# pandas.groupby
import pandas
b = pandas.Series([0,1,2,3],index=[1,2,3,1],name='b').groupby(level=0,)
b.apply(lambda x:len(x))
能看出,當數據無序時,兩者的分組結果不同。
pandas.groupby的結果與之前並無差異。但itertools.groupby的分組結果更像是相鄰數據去重後再分組的結果,同樣的值,如果被其他值分割的話,分組結果完全不一樣。
當數據無序時,准確來說是相同值的數據不相鄰時,itertools.groupby可能會產生意料之外的結果,
 Python data visualization tutorial drawing a beautiful double Y-axis line chart
Python data visualization tutorial drawing a beautiful double Y-axis line chart
When visualizing the drawing ,
 Complete your hacker dream, I used Python to brutally crack the WiFi password
Complete your hacker dream, I used Python to brutally crack the WiFi password
WiFi Cracking should be a hack