J'ai récemment rencontré unbug,C'est dans l'ancien Code,Tout va bien après des années d'utilisation,Mais il y a un problème avec les nouvelles exigences commerciales.Exclu,La découverte est due àitertools.groupbyL'utilisation de la,Au moins ce que je connais bienpandas.groupbyC'est différent..Je n'ai pas vu de comparaison pertinente en ligne,Alors écrivez vous - même une comparaison des similitudes et des différences.
# itertools.groupby
from itertools import groupby
a = groupby([1,1,2,3])
for i,j in a:
print(i,' ',len(list(j)))
# pandas.groupby
import pandas
b = pandas.Series([0,1,2,3],index=[1,1,2,3],name='b').groupby(level=0,)
b.apply(lambda x:len(x))
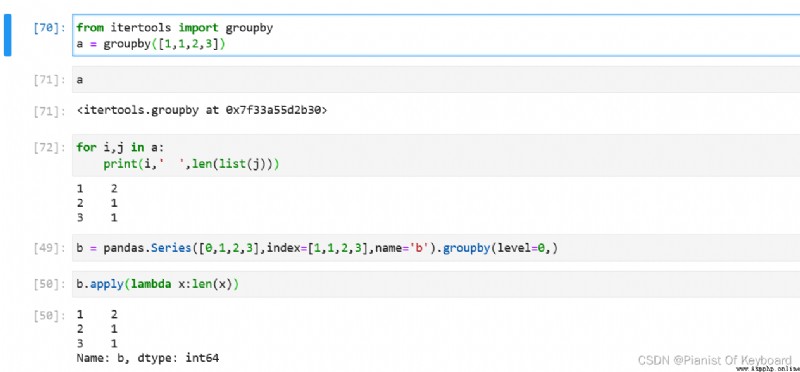
Vous pouvez voir que les deux sont des regroupements basés sur certaines règles,Mais quandOrdre des donnéesHeure, Les résultats du regroupement des deux groupes sont similaires .
# itertools.groupby
from itertools import groupby
a = groupby([1,2,3,1])
for i,j in a:
print(i,' ',len(list(j)))
# pandas.groupby
import pandas
b = pandas.Series([0,1,2,3],index=[1,2,3,1],name='b').groupby(level=0,)
b.apply(lambda x:len(x))
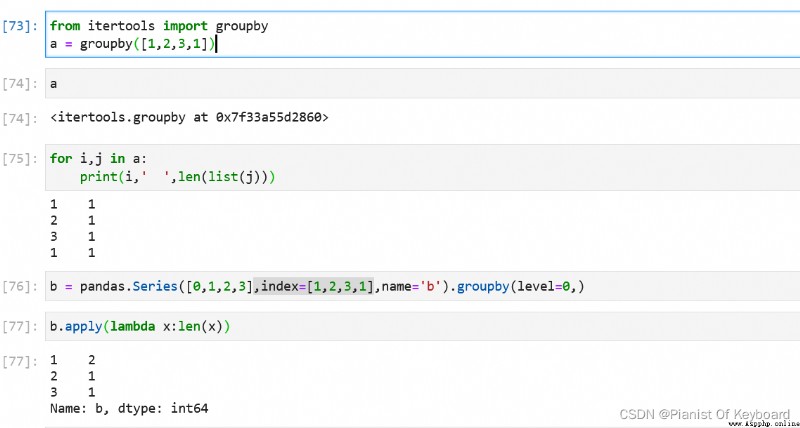
Je vois.,QuandDonnées désordonnéesHeure, Les résultats de regroupement sont différents pour les deux .
pandas.groupby Il n'y a pas de différence entre les résultats de .Mais...itertools.groupby Le résultat du regroupement est plus comme le résultat du regroupement des données adjacentes après le dédoublement ,Même valeur, Si elle est divisée par d'autres valeurs , Les résultats du regroupement sont complètement différents .
QuandDonnées désordonnéesHeure, Lorsque les données exactement de la même valeur ne sont pas adjacentes ,itertools.groupby Peut produire des résultats inattendus ,
 Python creates a visual GUI interface to automatically classify and manage files with one click!
Python creates a visual GUI interface to automatically classify and manage files with one click!
Often messy folders will make