Recently I met a bug, In old code , It's OK to use it for many years , However, new business requirements have encountered problems . After exclusion , The discovery is due to itertools.groupby The usage of is different from that in imagination , At least I know pandas.groupby Not quite the same. . I haven't seen any relevant comparisons on the Internet , So I wrote a comparison of similarities and differences .
# itertools.groupby
from itertools import groupby
a = groupby([1,1,2,3])
for i,j in a:
print(i,' ',len(list(j)))
# pandas.groupby
import pandas
b = pandas.Series([0,1,2,3],index=[1,1,2,3],name='b').groupby(level=0,)
b.apply(lambda x:len(x))
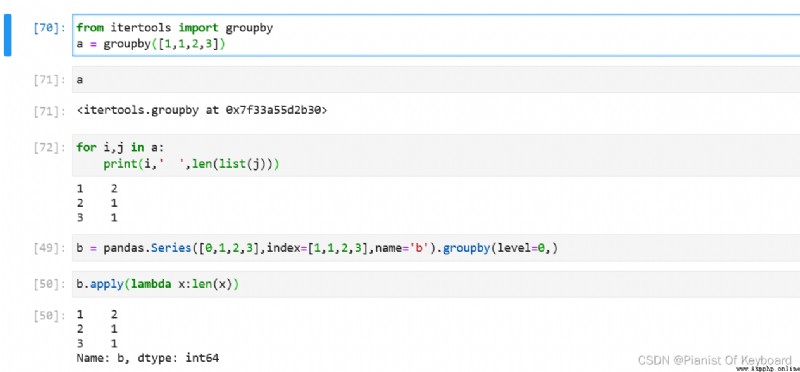
It can be seen that both groups are based on certain rules , But when Data order when , The results of the two groups are similar .
# itertools.groupby
from itertools import groupby
a = groupby([1,2,3,1])
for i,j in a:
print(i,' ',len(list(j)))
# pandas.groupby
import pandas
b = pandas.Series([0,1,2,3],index=[1,2,3,1],name='b').groupby(level=0,)
b.apply(lambda x:len(x))
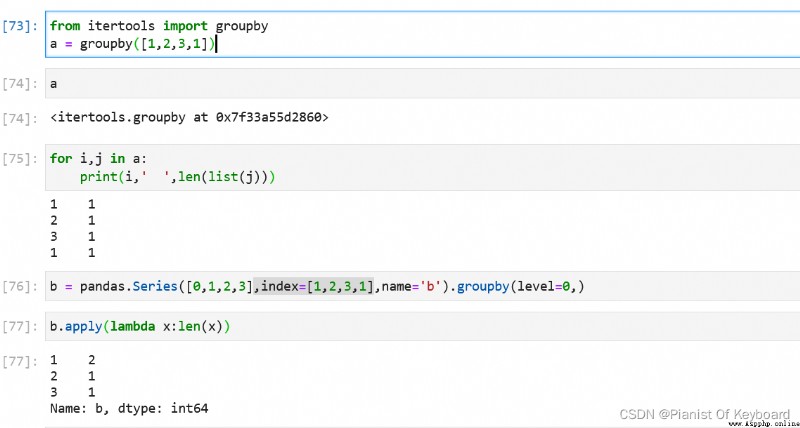
Can see , When Data is out of order when , The results of the two groups are different .
pandas.groupby There is no difference between the results of . but itertools.groupby The grouping result of is more like the grouping result of adjacent data after de duplication , The same value , If divided by other values , The grouping results are completely different .
When Data is out of order when , To be exact, data of the same value are not adjacent ,itertools.groupby It can have unexpected results ,