First enter Baidu pictures , Here you can search with the keyword of kasha .F12 Enter developer mode , You can see that without scrolling, only 30 A picture , And when we roll the brace down , New nodes appear , That is to say Ajax Rendered .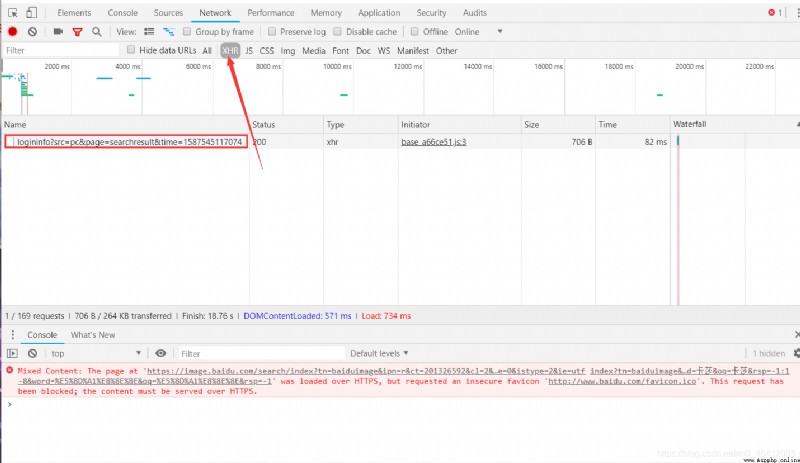
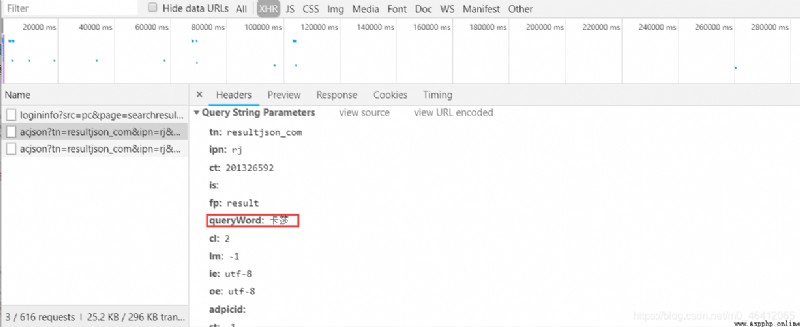
At this time, the url Construction parameters of , You can see the parameters “queryWord: Card is a kind of insect ”
It is our key word ,tn The parameter description is an example of this URL json file .rn
Is the number of pictures displayed on the page . There's only one variable parameter pn,pn by 0 This is the first load 30 A picture ,pn by 30 Is loaded for the second time 30 Picture and so on .pn The change law of is 30*i. So the main part of the website is constructed :
“https://image.baidu.com/search/acjson?”
The parameter section can use params Parameters of the incoming .
def get_page():
url="https://image.baidu.com/search/acjson?"
headers = {
"User-Agent": ''}
params={
"tn":"resultjson_com",
"word":" Card is a kind of insect ",
"ipn":"rj" ,
"pn":0
}
r = requests.get(url,headers=headers,params=params)
return r.text
After obtaining the source code, you can use re Expression to get the picture URL .json There are multiple pictures in the file url, What we need to match is HD "objurl": The corresponding value , So use regular expressions , You can also use it json Direct access to . Useful here re
def get_img(html):
url_ls=re.findall('.*?"objURL":"(.*?)"',html,re.S)
for items in range(len(url_ls)):
image=requests.get(url_ls[items])
with open(" picture "+str(items+1)+".png","wb") as file:
file.write(image.content)
Finally, integrate the code , You can define a class , This allows you to search for any image you want .
import requests
import re
import os
import time
import json
class Baidupicture(object):
def __init__(self,keyword):
self.keyword=keyword
def get_dir(self):
os.mkdir(self.keyword)
# Here is to create a folder under your working path for storing pictures
os.chdir(r" Folder working path ")
# Here, set the folder as your working path
def get_page(self,offset):
url="https://image.baidu.com/search/acjson?"
headers = {
"User-Agent": ''}
params={
"tn":"resultjson_com",
"word":self.keyword,
"ipn":"rj" ,
"pn":offset
}
r = requests.get(url,headers=headers,params=params)
return r.text
def get_img(self,html,offset):
#html That is, acquired json file ,offset by
url_ls=re.findall('.*?"objURL":"(.*?)"',html,re.S)
for items in range(len(url_ls)):
image=requests.get(url_ls[items])
with open(" picture "+str(offset+items+1)+".png","wb") as file:
file.write(image.content)
a=Baidupicture(" Card is a kind of insect ")
a.get_dir()
for offset in [x for x in range(61) if x%30==0]:
html=a.get_page(offset)
a.get_img(html,offset)