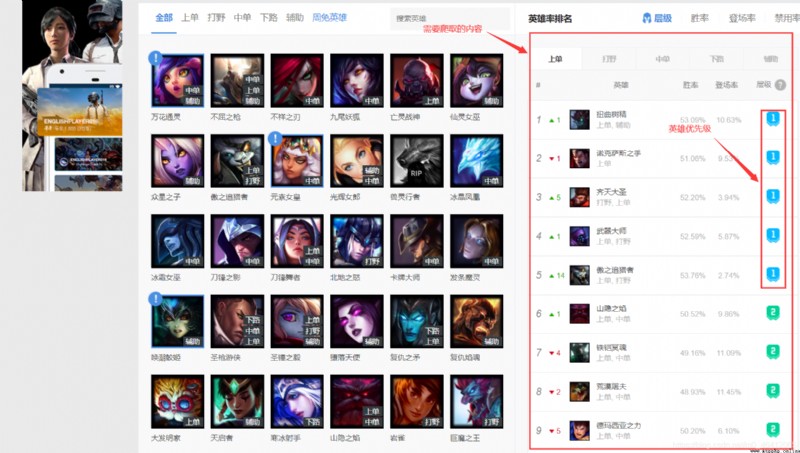
Get into op.gg Then click the hero data in the upper left corner , Then we can view the source code of the page , It is found that all the data we need are in the source code , This will make our crawling work much easier . The page also supports multiple languages , So we need to pass in the corresponding parameters , Show simplified Chinese . We enter the developer mode of the browser , You can see that you need to pass in the request header User-Agent and Accept-Language Two parameters .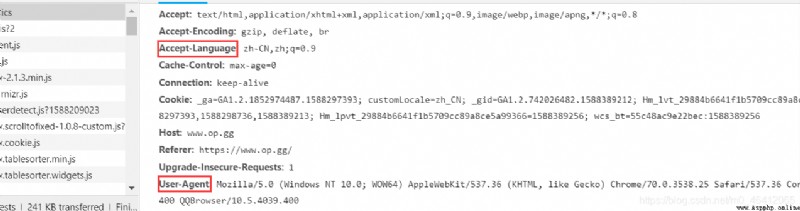
So construct the request header .
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400",
"Accept-Language":"zh-CN,zh;q=0.9"
}
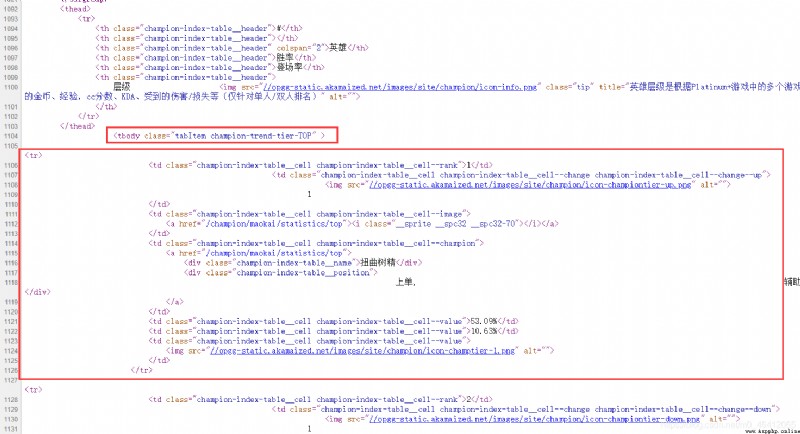
You can see in the tbody The tag has all the hero data on the list , stay tbody Every one of them tr The node corresponds to the data of each hero . All hero data of the corresponding wild fighting should be in JUNGLE Of tbody tag . And then we can see tr There is a in the node img node , It has a src attribute , It's a url, Click to see the priority in the first picture of the article .
“//opgg-static.akamaized.net/images/site/champion/icon-champtier-1.png”
This url The number at the end of the middle 1 Represents the corresponding priority . We need to extract it . Then the winning rate is in the text of the node , Can be extracted .
With the previous analysis , We can start to extract the data , Here we use pyquery Parsing , Of course with xpath These are all fine . Let's first extract the data of the previous hero .
import requests
from pyquery import PyQuery as pq
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400",
"Accept-Language":"zh-CN,zh;q=0.9"
}
html=requests.get("http://www.op.gg/champion/statistics",headers=headers).text
doc=pq(html)
top_mes=doc("tbody.tabItem.champion-trend-tier-TOP tr").items()
# I'm going through it here tbody Every one of tr node
for items in top_mes:
name=items.find("div.champion-index-table__name").text()
# Get hero name
win_chance=items.find("td.champion-index-table__cell--value").text()[:6]
# Win rate
choice=items.find("td.champion-index-table__cell--value").text()[6:]
# Get your presence
img=items.find("td.champion-index-table__cell--value img").attr("src")
fisrt_chance="T"+re.match(".*r-(.*?)\.png",img).group(1)
# obtain src Property and extract the priority
If we need to get data from five locations , Just add and traverse all tbody The node can be .
For the above data, we can generate a generator , Add the following code to the above code
yield{
"name":name,
"win_chance":win_chance,
"choice":choice,
"fisrt_chance":fisrt_chance
}
We write data to excel, We need to use csv Standard library . Here, you should pay attention to adding encoding and newline Two parameters , Otherwise, there will be chaos .
import csv
def write_csv(data):
with open("top.csv", "a", encoding="utf-8-sig", newline='') as file:
fieldnames = ["name", "win_chance",
"choice", "fisrt_chance"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writerow(data)
import requests
from pyquery import PyQuery as pq
import csv
def get_message(five_mes):
for items in five_mes:
name=items.find("div.champion-index-table__name").text()
# Get hero name
win_chance=items.find("td.champion-index-table__cell--value").text()[:6]
# Win rate
choice=items.find("td.champion-index-table__cell--value").text()[6:]
# Get your presence
img=items.find("td.champion-index-table__cell--value img").attr("src")
fisrt_chance="T"+re.match(".*r-(.*?)\.png",img).group(1)
# obtain src Property and extract the priority
yield{
"name":name,
"win_chance":win_chance,
"choice":choice,
"fisrt_chance":fisrt_chance
}
def write_csv(data,names):
# Parameters names For the file name
with open(names+".csv", "a", encoding="utf-8-sig", newline='') as file:
fieldnames = ["name", "win_chance",
"choice", "fisrt_chance"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writerow(data)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400",
"Accept-Language":"zh-CN,zh;q=0.9"
}
html=requests.get("http://www.op.gg/champion/statistics",headers=headers).text
doc=pq(html)
for position in doc("tbody").items():
# Here we traverse five tbody node , Each represents five positions
names=re.match("tabItem champion-trend-tier-(.*)",position.attr("class")).group(1)
# Here we use regular expressions to extract tbody Of calss Attribute top,mid,adc Etc. as the file name
for items in get_message(position.find("tr").items()):
# Here we go through each tbody Node tr Node and use get_message function
write_csv(items,names)
if items.get("fisrt_chance")=="T1":
# Output T1 hero
print(" current version T1 Hierarchical "+names+" Yes "+items.get("name"))
The result is five csv file 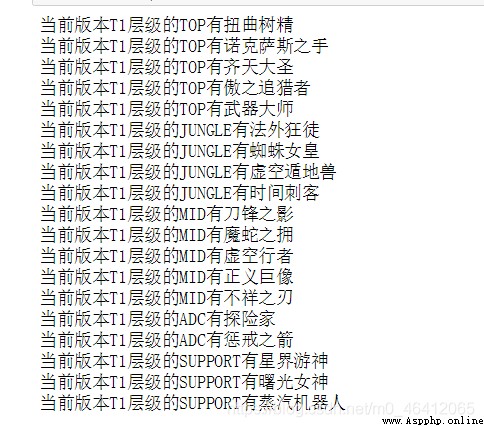

**
**