This time with Douban film TOP250 Web as an example to write a crawler program , And crawl the data ( ranking 、 Movie title and movie poster website ) Deposit in MySQL In the database . Here is the complete code :
Ps: Before executing the program , First in MySQL Create a database "pachong".
import pymysql
import requests
import re
# Get resources and download
def resp(listURL):
# Connect to database
conn = pymysql.connect(
host = '127.0.0.1',
port = 3306,
user = 'root',
password = '******', # Please input the database password according to your actual password
database = 'pachong',
charset = 'utf8'
)
# Create database cursor
cursor = conn.cursor()
# Create a list of t_movieTOP250( perform sql sentence )
cursor.execute('create table t_movieTOP250(id INT PRIMARY KEY auto_increment NOT NULL ,movieName VARCHAR(20) NOT NULL ,pictrue_address VARCHAR(100))')
try:
# Crawl data
for urlPath in listURL:
# Get web source code
response = requests.get(urlPath)
html = response.text
# Regular expressions
namePat = r'alt="(.*?)" src='
imgPat = r'src="(.*?)" class='
# Matches a regular ( ranking 【 In the database id Instead of , Automatic generation and sorting 】、 The movie name 、 Movie Poster ( Picture address ))
res2 = re.compile(namePat)
res3 = re.compile(imgPat)
textList2 = res2.findall(html)
textList3 = res3.findall(html)
# Traverse the elements in the list , And store the data in the database
for i in range(len(textList3)):
cursor.execute('insert into t_movieTOP250(movieName,pictrue_address) VALUES("%s","%s")' % (textList2[i],textList3[i]))
# Get the result from the cursor
cursor.fetchall()
# Submit results
conn.commit()
print(" Results submitted ")
except Exception as e:
# Data rollback
conn.rollback()
print(" Data rolled back ")
# Close the database
conn.close()
#top250 All web addresses
def page(url):
urlList = []
for i in range(10):
num = str(25*i)
pagePat = r'?start=' + num + '&filter='
urL = url+pagePat
urlList.append(urL)
return urlList
if __name__ == '__main__':
url = r"https://movie.douban.com/top250"
listURL = page(url)
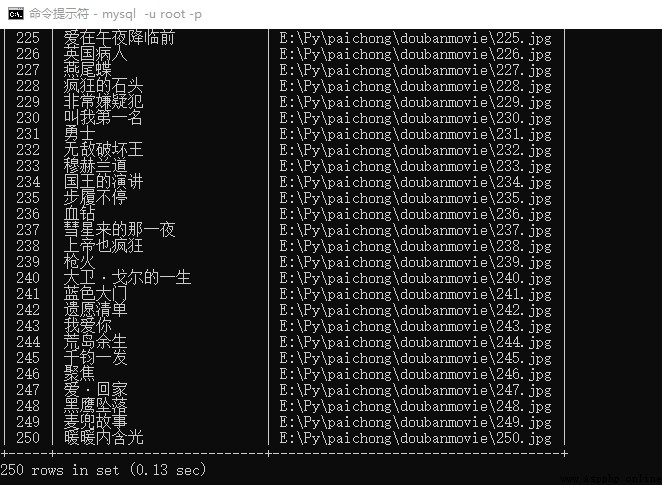
resp(listURL)The results are as follows :

That's what I share , If there are any deficiencies, please point out , More communication , thank you !
If you want to get more data or customize the crawler, please send me a private message .