The previous web pages used “GET” Method , This time “ Pull hook net ” Yes “POST” Methods . among ,"GET" and “POST” The biggest difference between them is :"GET" When asked , The data will be displayed directly in the address bar ;“POST” When asked , The data is in the packet ( Encapsulated in the request body , Usually js in ), Climbing is relatively difficult .“ Pull hook net ” Exactly “POST” Request to get information . therefore , I wrote this program :
First , Or start with grabbing , Enter... In the pull grid python, Then select Shenzhen , stay network Find position.Ajax The file of , It contains the position details of the current page 、 Total number of posts, etc .
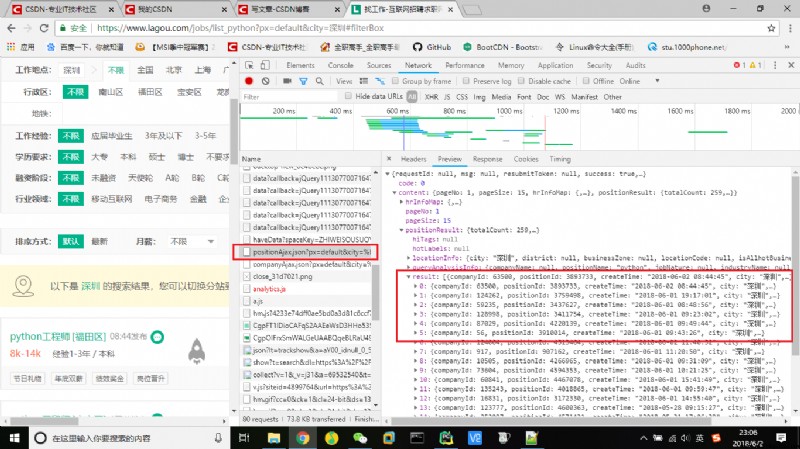
therefore , Take this as the request URL (URL), Again from headers Find the relevant request header parameters and data data , Then you can initiate the request , use requests Of post Method .
# Request content ( Request URL 、 Request header and request data )
url = r'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3423.2 Safari/537.36",
"Accept":"application/json, text/javascript, */*; q=0.01",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Host":"www.lagou.com",
"Origin":"https://www.lagou.com",
"Referer":"https://www.lagou.com/jobs/list_python?px=default&city=%E5%B9%BF%E5%B7%9E",
"Cookie":"JSESSIONID=ABAAABAABEEAAJAED90BA4E80FADBE9F613E7A3EC91067E; _ga=GA1.2.1013282376.1527477899; user_trace_token=20180528112458-b2b32f84-6226-11e8-ad57-525400f775ce; LGUID=20180528112458-b2b3338b-6226-11e8-ad57-525400f775ce; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1527346927,1527406449,1527423846,1527477899; _gid=GA1.2.1184022975.1527477899; index_location_city=%E5%85%A8%E5%9B%BD; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1527487349; LGSID=20180528140228-b38fe5f2-623c-11e8-ad79-525400f775ce; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2Fzhaopin%2FPython%2F%3FlabelWords%3Dlabel; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_Python%3Fpx%3Ddefault%26city%3D%25E5%25B9%25BF%25E5%25B7%259E; TG-TRACK-CODE=index_search; _gat=1; LGRID=20180528141611-9e278316-623e-11e8-ad7c-525400f775ce; SEARCH_ID=42c704951afa48b5944a3dd0f820373d"
}
data = {
"first":True,
"pn":1,
"kd":"python"
}#json Data crawling
def dataJson(url,headers,data):
# Initiate request (POST)
req = requests.post(url, data = data, headers = headers)
# Return and parse the request result ( String format )
response = req.text
# convert to json Format
htmlJson = json.loads(response)
# return json Format data
return htmlJsonThe returned data is converted to json Format , Facilitate the later data filtering , Through analysis, we found that , The job details are in json The data shows , After filtering, the total number of positions and position pages are returned
# Post number and page number screening
def positonCount(htmlJson):
# Select the number of Posts and pages
totalCount = htmlJson["content"]["positionResult"]["totalCount"]
# Each page shows 15 Post ( Rounding up )
page = math.ceil((totalCount)/15)
# Maximum display of hook screen 30 Page results
if page > 30:
return 30
else:
return (totalCount,page)# Position details screening
def selectData(htmlJson):
# Filter out position details
jobList = htmlJson["content"]["positionResult"]["result"]
# Create a work information list ( appearance )
jobinfoList = []
# Traverse , Find the data
for jobDict in jobList:
# Create a work information list ( Internal table )
jobinfo = []
# Job title
jobinfo.append(jobDict['positionName'])
# Corporate name
jobinfo.append(jobDict['companyFullName'])
# The nature of the company
jobinfo.append(jobDict['financeStage'])
# The company size
jobinfo.append(jobDict['companySize'])
# Industry sector
jobinfo.append(jobDict['industryField'])
# Office location ( Location )
jobinfo.append(jobDict['district'])
# Job label
positionLables = jobDict['positionLables']
ret1 = ""
for positionLable in positionLables:
ret1 += positionLable + ";"
jobinfo.append(ret1)
# Degree required
jobinfo.append(jobDict['education'])
# Work experience
jobinfo.append(jobDict['workYear'])
# Wages
jobinfo.append(jobDict['salary'])
# treatment
jobinfo.append(jobDict['positionAdvantage'])
# Company benefits
companyLabelList = jobDict['companyLabelList']
ret2 = ""
for companyLabel in companyLabelList:
ret2 += companyLabel + ";"
jobinfo.append(ret2)
# Job type
jobinfo.append(jobDict['firstType'])
# Release time
jobinfo.append(jobDict['createTime'])
# Add the position information list
jobinfoList.append(jobinfo)
# The interval is 30s, Prevent too frequent access
time.sleep(30)
return jobinfoList
give the result as follows :
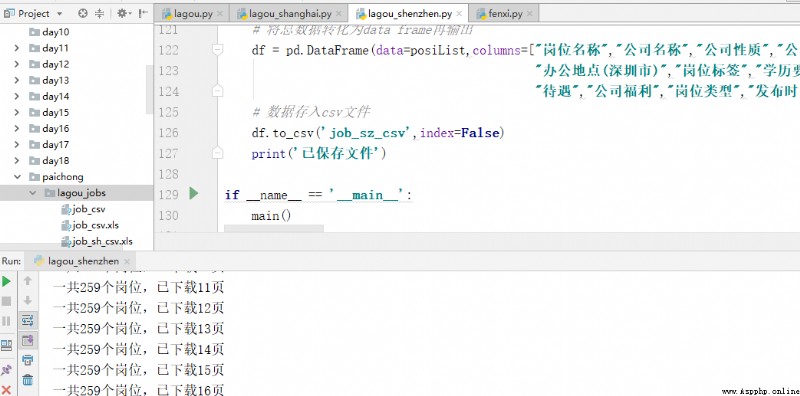
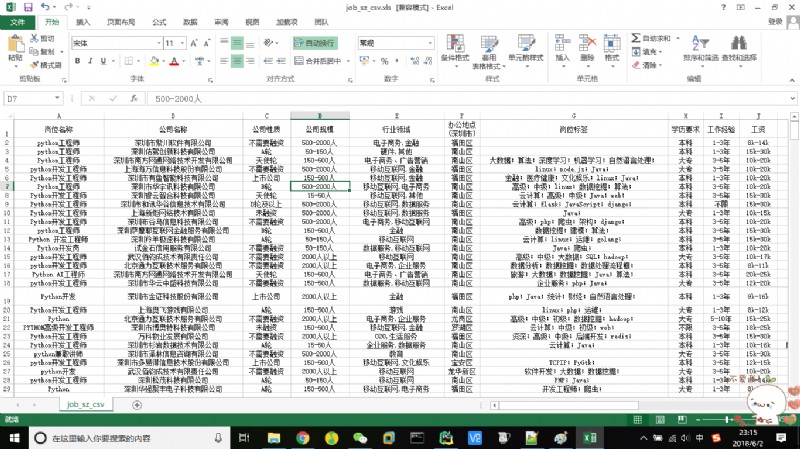
That's what I share , If there are any deficiencies, please point out , More communication , thank you !
If you want to get more data or customize the crawler, please send me a private message