I believe I learned python Reptiles , Many people want to crawl some websites with a large amount of data , Taobao is a good target , It has a large amount of data , And there are so many kinds , And it's not very difficult , It is very suitable for junior scholars to crawl . Here is the whole crawling process :
First step : Build access url
# Build access url
goods = " Fishtail skirt "
page = 10
infoList = []
url = 'https://s.taobao.com/search'
for i in range(page):
s_num = str(44*i+1)
num = 44*i
data = {'q':goods,'s':s_num}The second step : Get web information
def getHTMLText(url,data):
try:
rsq = requests.get(url,params=data,timeout=30)
rsq.raise_for_status()
return rsq.text
except:
return " No page found "The third step : Use regular to get the required data
def parasePage(ilt, html,goods_id):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
slt = re.findall(r'\"view_sales\"\:\".*?\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
ult = re.findall(r'\"pic_url\"\:\".*?\"', html)
dlt = re.findall(r'\"detail_url\"\:\".*?\"', html)
for i in range(len(plt)):
goods_id += 1
price = eval(plt[i].split(':')[1])
sales = eval(slt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
pic_url = "https:" + eval(ult[i].split(':')[1])
detail_url = "https:" + eval(dlt[i].split(':')[1])
ilt.append([goods_id,price,sales,title,pic_url,detail_url])
return ilt
except:
print(" The product you need is not found !")Step four : Save data to csv file
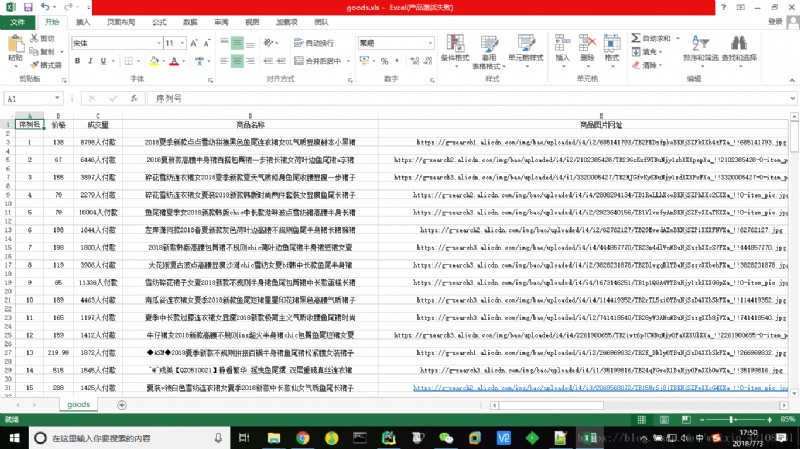
def saveGoodsList(ilt):
with open('goods.csv','w') as f:
writer = csv.writer(f)
writer.writerow([" Serial number ", " Price ", " volume ", " Name of commodity "," Product picture website "," Product details website "])
for info in ilt:
writer.writerow(info)
The results are as follows :
That's what I share , If there are any deficiencies, please point out , More communication , thank you !
If you want to get more data or customize the crawler, please send me a private message .