I believe everyone will look for information on the Internet before buying a house , Look at the market , Ask a friend , Let's have a steak today 《 HOME LINK second-hand house 》 The data of :
Open the chain home official website , Enter the second-hand house page , Select a city , You can see the total number of houses in the city and the list data of houses .
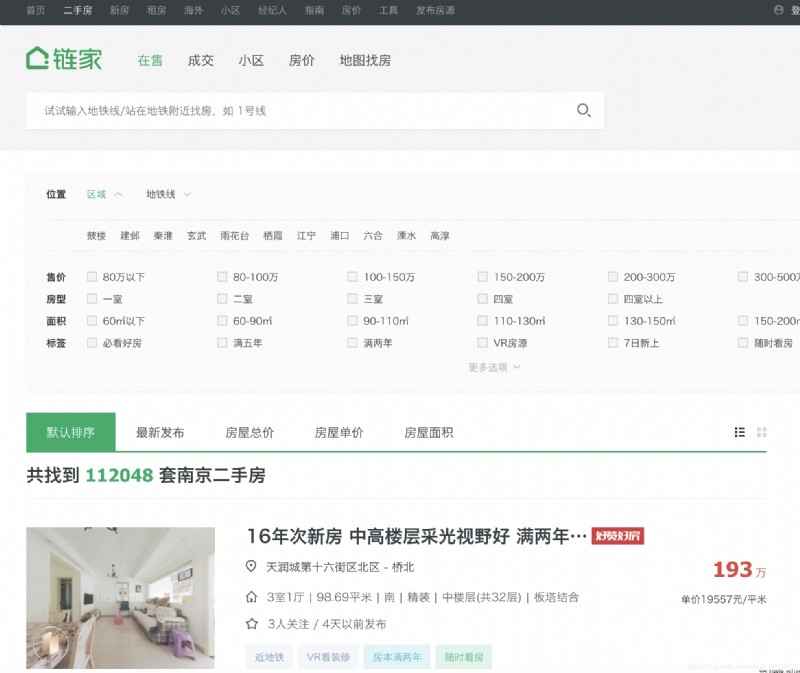
The data of some websites is stored in html in , And some are api Interface , Even some encryption in js in , Fortunately, the housing data of the chain family is stored in html in :

adopt requests Request page , Get every page of html data
# The crawl url, The default crawled chain home real estate information in Nanjing
url = 'https://nj.lianjia.com/ershoufang/pg{}/'.format(page)
# request url
resp = requests.get(url, headers=headers, timeout=10)adopt BeautifulSoup analysis html, And extract the corresponding useful data
soup = BeautifulSoup(resp.content, 'lxml')
# Filter all li label
sellListContent = soup.select('.sellListContent li.LOGCLICKDATA')
# Loop traversal
for sell in sellListContent:
# title
title = sell.select('div.title a')[0].string
# Grab all the div Information , Then extract each one
houseInfo = list(sell.select('div.houseInfo')[0].stripped_strings)
# The name of the property
loupan = houseInfo[0]
# Segment the information of the real estate
info = houseInfo[0].split('|')
# House type
house_type = info[1].strip()
# Size of area
area = info[2].strip()
# The room faces
toward = info[3].strip()
# Decoration type
renovation = info[4].strip()
# House address
positionInfo = ''.join(list(sell.select('div.positionInfo')[0].stripped_strings))
# The total price of the house
totalPrice = ''.join(list(sell.select('div.totalPrice')[0].stripped_strings))
# The unit price of the house
unitPrice = list(sell.select('div.unitPrice')[0].stripped_strings)[0]That's what I share , If there are any deficiencies, please point out , More communication , thank you !
If you want to get more data or customize the crawler, please send me a private message