最近在學習《利用python進行數據分析》,在案例實戰過程和使用pandas庫中還存在著許多問題沒有解決,這裡進行總結。

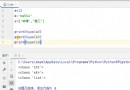
如上圖所示,出現如上所示的警告,這裡推薦一篇文章:https://www.jianshu.com/p/72274ccb647a
這篇文章很詳細的解釋了出現的原因及解決方案,這是一個鏈式索引的問題。

這個警告的大概意思就是告訴你:因為“c”引擎不支持正則表達式分隔符(分隔符>1個字符且不同於“\s+”的分隔符被解釋為正則表達式),可以通過指定engine=”python“這個參數來避免此警告。具體的可以復制到翻譯軟件。因為Python語言底層是采用C語言實現的,可以簡單理解為Python是用C寫出來的。這需要大佬進行相關解釋,我也不是很理解這個意思。這裡將代碼改為:
df1=pd.read_csv("movies.dat",sep='::',header=None,engine="python",names=mnames)
就行了,這也是《利用python進行數據分析》書中的一個實例。
將dataframe寫入excel可以用pandas的to_excel(path,sheet1)path為路徑,sheet1為表格名稱。但如果要將多個dataframe寫入同一個excel文件,需要用到ExcelWriter()方法
import pandas as pd
#首先創建兩個dataframe
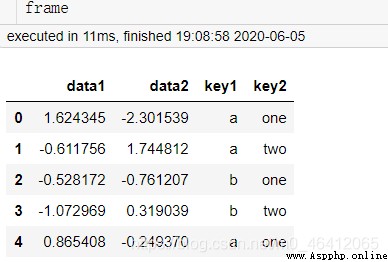
frame=pd.DataFrame({
"data1":random.randn(5),
"data2":random.randn(5),
"key1":["a","a","b","b","a"],
"key2":["one","two","one","two","one"]})
frame2=frame.copy()
writer=pd.ExcelWriter("test.xls")
frame.to_excel(writer,"frame")
frame2.to_excel(writer,"frame2")
writer.save()
這裡創建了兩個dataframe,將其寫入text文件,並將兩個表格的名稱分別命名為frame和frame2。注意最後要執行 writer.save()代碼,不然不會創建文件,只是在緩存中。
如果要將多個dataframe寫入同一張表格,可以利用startcol和startrow這兩個參數來實現
writer=pd.ExcelWriter("test.xls")
frame.to_excel(writer,startrow=2)
frame2.to_excel(writer,startrow=18,startcol=18)
writer.save()
#startrow代表寫入的起始行,startcol代表寫入的起始列
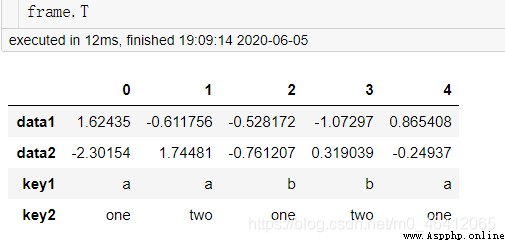
dataframe也有類似於numpy數組類似的轉置操作。