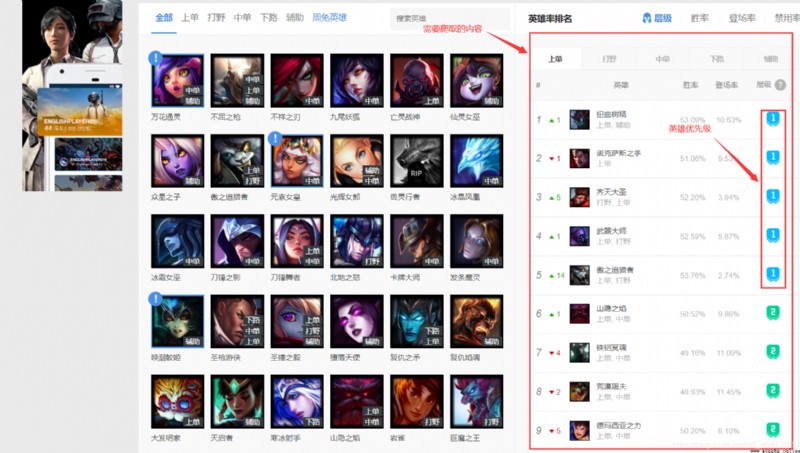
進入op.gg後點擊左上角的英雄數據,然後我們可以查看該頁面的源碼,發現我們需要的數據都在源碼中,這就可以使我們的爬取工作輕松許多。該頁面還支持多國語言,因此我們要傳入相應參數,顯示簡體中文。我們進入浏覽器的開發者模式,可以看到需要在請求頭中傳入User-Agent和Accept-Language兩個參數。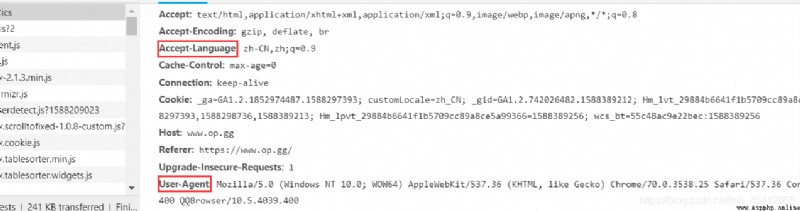
因此構造好請求頭。
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400",
"Accept-Language":"zh-CN,zh;q=0.9"
}
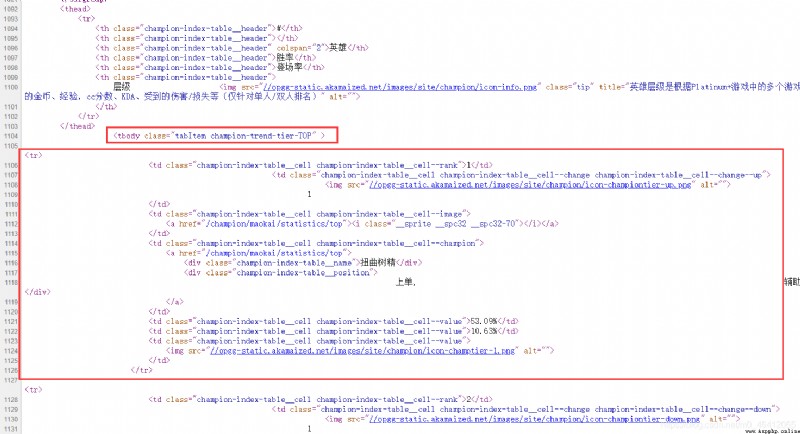
可以看到在tbody標簽有所有上單的英雄數據,在tbody內的每一個tr節點對應每一個英雄的數據。相應的打野的所有英雄數據應該在JUNGLE的tbody標簽內。然後我們可以看到tr節點內有個img節點,它有個src屬性,是一個url,點開看是文章第一張圖片中的優先級。
“//opgg-static.akamaized.net/images/site/champion/icon-champtier-1.png”
這個url中末尾的數字1代表相應的優先級。我們需要把他提取出來。然後勝率這些都在節點的文本中,都可以提取出來。
有了前面的分析,我們就可以開始提取數據了,這裡用pyquery來解析,當然用xpath這些都可以。我們首先來提取上單英雄數據。
import requests
from pyquery import PyQuery as pq
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400",
"Accept-Language":"zh-CN,zh;q=0.9"
}
html=requests.get("http://www.op.gg/champion/statistics",headers=headers).text
doc=pq(html)
top_mes=doc("tbody.tabItem.champion-trend-tier-TOP tr").items()
#這裡遍歷tbody的每一個tr節點
for items in top_mes:
name=items.find("div.champion-index-table__name").text()
#獲取英雄名稱
win_chance=items.find("td.champion-index-table__cell--value").text()[:6]
#獲取勝率
choice=items.find("td.champion-index-table__cell--value").text()[6:]
#獲取登場率
img=items.find("td.champion-index-table__cell--value img").attr("src")
fisrt_chance="T"+re.match(".*r-(.*?)\.png",img).group(1)
#獲取src屬性並提取出優先級
如果我們需要獲取五個位置的數據,只需添加遍歷所有tbody節點即可。
對於上述的數據我們可以生成一個生成器,在上述代碼中加入以下代碼
yield{
"name":name,
"win_chance":win_chance,
"choice":choice,
"fisrt_chance":fisrt_chance
}
我們將數據寫入excel,這裡要用到csv標准庫。這裡在寫入是要注意添加encoding和newline兩個參數,不然會出現亂碼。
import csv
def write_csv(data):
with open("top.csv", "a", encoding="utf-8-sig", newline='') as file:
fieldnames = ["name", "win_chance",
"choice", "fisrt_chance"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writerow(data)
import requests
from pyquery import PyQuery as pq
import csv
def get_message(five_mes):
for items in five_mes:
name=items.find("div.champion-index-table__name").text()
#獲取英雄名稱
win_chance=items.find("td.champion-index-table__cell--value").text()[:6]
#獲取勝率
choice=items.find("td.champion-index-table__cell--value").text()[6:]
#獲取登場率
img=items.find("td.champion-index-table__cell--value img").attr("src")
fisrt_chance="T"+re.match(".*r-(.*?)\.png",img).group(1)
#獲取src屬性並提取出優先級
yield{
"name":name,
"win_chance":win_chance,
"choice":choice,
"fisrt_chance":fisrt_chance
}
def write_csv(data,names):
#參數names為文件名
with open(names+".csv", "a", encoding="utf-8-sig", newline='') as file:
fieldnames = ["name", "win_chance",
"choice", "fisrt_chance"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writerow(data)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400",
"Accept-Language":"zh-CN,zh;q=0.9"
}
html=requests.get("http://www.op.gg/champion/statistics",headers=headers).text
doc=pq(html)
for position in doc("tbody").items():
#這裡遍歷五個tbody節點,分別代表五個位置
names=re.match("tabItem champion-trend-tier-(.*)",position.attr("class")).group(1)
#這裡用正則表達式提取出tbody的calss屬性的top,mid,adc等作為文件名
for items in get_message(position.find("tr").items()):
#這裡遍歷每一個tbody節點的tr節點並利用get_message函數
write_csv(items,names)
if items.get("fisrt_chance")=="T1":
#輸出T1英雄
print("當前版本T1層級的"+names+"有"+items.get("name"))
結果會創建五個csv文件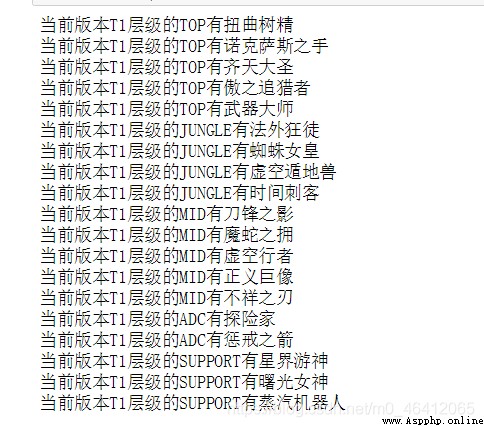

**
**