首先進入百度圖片,這裡以卡莎為關鍵詞搜索。F12進入開發者模式,可以看到在我們不滾動的情況下只顯示了30張圖片,而我們向下滾動拉條時,出現了新的節點,也就是Ajax渲染的。
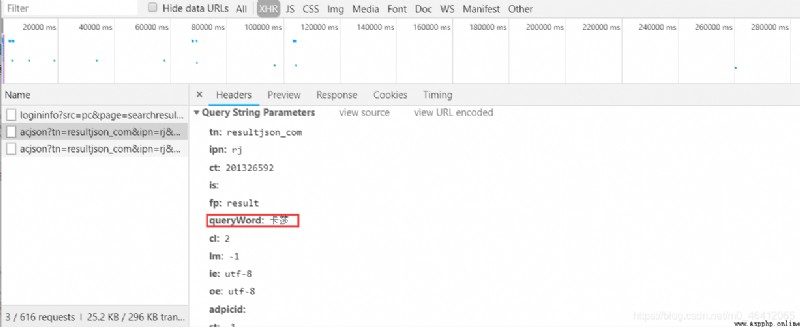
這時分析節點的url的構造參數,可以看到參數 “queryWord: 卡莎”
正是我們的關鍵詞,tn參數說明是這個網址的一個json文件。rn
是頁面顯示的圖片數。只有一個變化的參數pn,pn為0就是第一次加載的30張圖片,pn為30則為第二次加載的30張圖片以此類推。pn的變化規律為30*i。因此構造出網址的主要部分:
“https://image.baidu.com/search/acjson?”
參數部分可以利用params參數傳入。
def get_page():
url="https://image.baidu.com/search/acjson?"
headers = {
"User-Agent": ''}
params={
"tn":"resultjson_com",
"word":"卡莎",
"ipn":"rj" ,
"pn":0
}
r = requests.get(url,headers=headers,params=params)
return r.text
獲取到源代碼後可以利用re表達式獲取圖片網址。json文件中有多個圖片的url,我們需要匹配的也就是高清的是"objurl": 所對應的值,因此利用正則表達式,當然也可以用json直接獲取。這裡有用re
def get_img(html):
url_ls=re.findall('.*?"objURL":"(.*?)"',html,re.S)
for items in range(len(url_ls)):
image=requests.get(url_ls[items])
with open("圖片"+str(items+1)+".png","wb") as file:
file.write(image.content)
最後整合一下代碼,可以定義一個類,這樣可以搜索任何你要所搜的圖片。
import requests
import re
import os
import time
import json
class Baidupicture(object):
def __init__(self,keyword):
self.keyword=keyword
def get_dir(self):
os.mkdir(self.keyword)
#這裡是在你的工作路徑下創建一個文件夾用於存儲圖片
os.chdir(r"文件夾工作路徑")
#這裡要將文件夾設置為你的工作路徑
def get_page(self,offset):
url="https://image.baidu.com/search/acjson?"
headers = {
"User-Agent": ''}
params={
"tn":"resultjson_com",
"word":self.keyword,
"ipn":"rj" ,
"pn":offset
}
r = requests.get(url,headers=headers,params=params)
return r.text
def get_img(self,html,offset):
#html即為獲取的json文件,offset為
url_ls=re.findall('.*?"objURL":"(.*?)"',html,re.S)
for items in range(len(url_ls)):
image=requests.get(url_ls[items])
with open("圖片"+str(offset+items+1)+".png","wb") as file:
file.write(image.content)
a=Baidupicture("卡莎")
a.get_dir()
for offset in [x for x in range(61) if x%30==0]:
html=a.get_page(offset)
a.get_img(html,offset)