說明:這是一個機器學習實戰項目(附帶數據+代碼+文檔+視頻講解),如需數據+代碼+文檔+視頻講解可以直接到文章最後獲取。
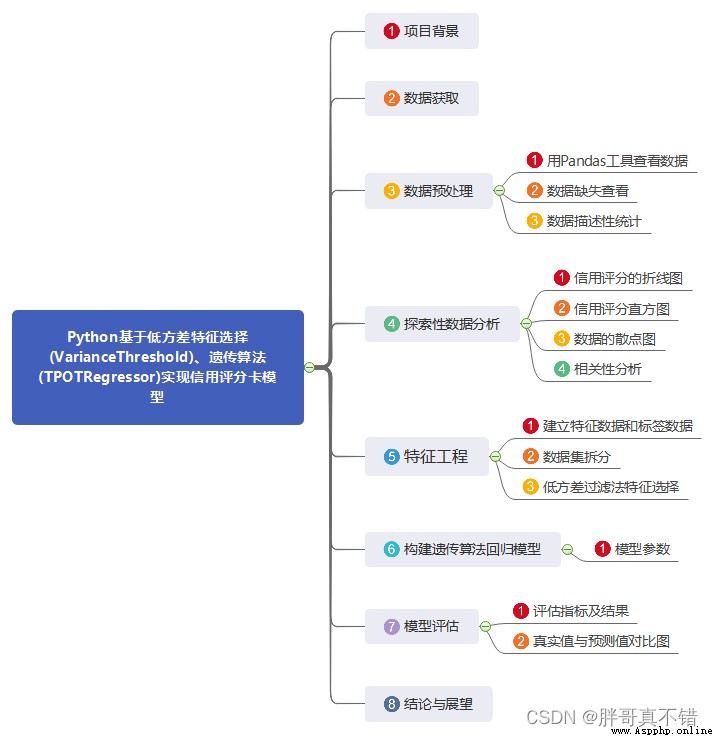
1.項目背景
如今,越來越多的80,90後貸款買房買車,一時之間,銀行提供的貸款業務成了時代的“新寵”。銀行貸款是指個人或企業向銀行根據該銀行所在國家政策以一定的利率將資金貸放給資金需求的個人或企業,並約定期限歸還的一種經濟行為。
為了降低不良貸款率,保障自身資金安全,提高風險控制水平,銀行等金融機構會根據客戶的信用歷史資料構建信用評分卡模型給客戶評分。根據客戶的信用得分,可以預估客戶按時還款的可能性,並據此決定是否發放貸款及貸款的額度和利率。
本項目應用低方差方法進行特征選擇,應用遺傳算法進行構建信用評分卡模型。
2.數據獲取
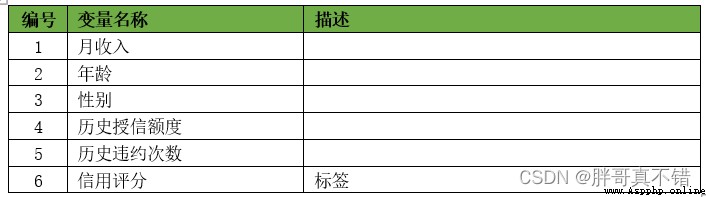
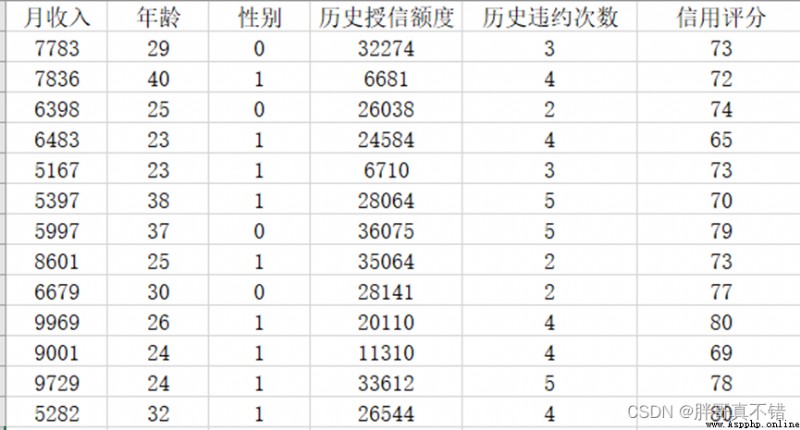
本次建模數據來源於網絡(本項目撰寫人整理而成),數據項統計如下:
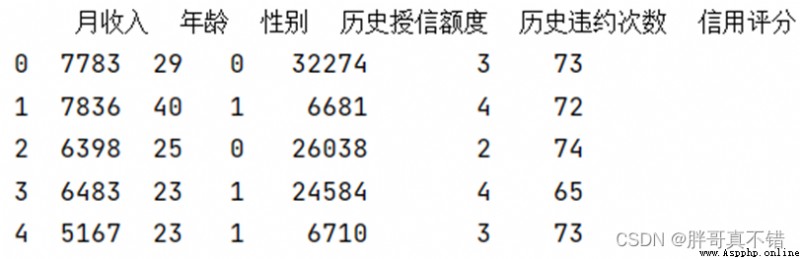
數據詳情如下(部分展示):
3.數據預處理
3.1 用Pandas工具查看數據
使用Pandas工具的head()方法查看前五行數據:
關鍵代碼:
3.2數據缺失查看
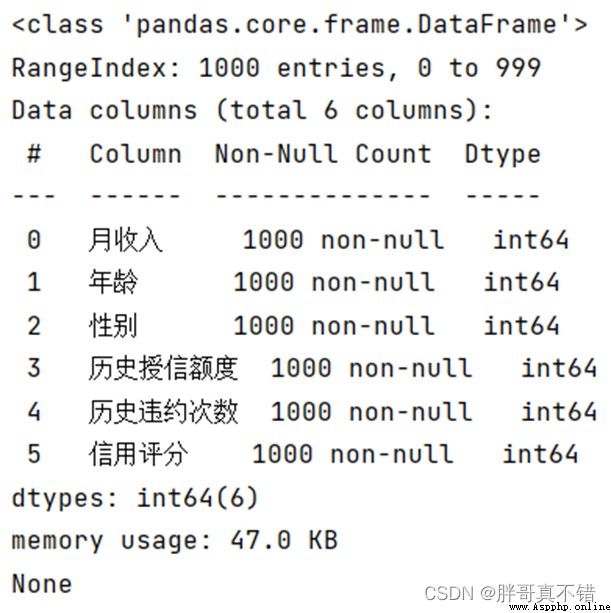
使用Pandas工具的info()方法查看數據信息:
從上圖可以看到,總共有6個變量,數據中無缺失值,共1000條數據。
關鍵代碼:
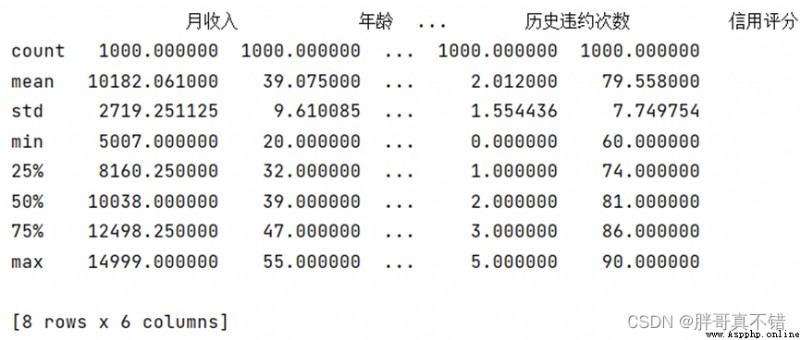
3.3數據描述性統計
通過Pandas工具的describe()方法來查看數據的平均值、標准差、最小值、分位數、最大值。
關鍵代碼如下:
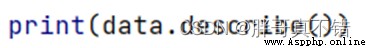
4.探索性數據分析
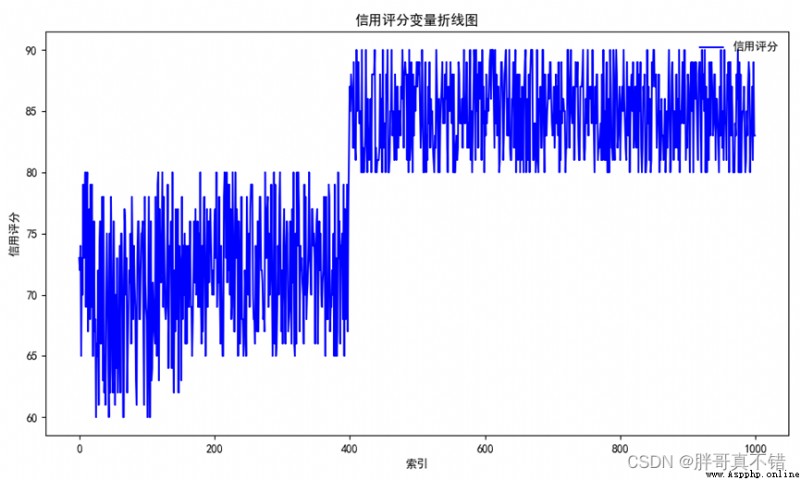
4.1 信用評分的折線圖
用Matplotlib工具的plot()方法繪制折線圖:
從上圖可以看出,大部分人的信用評分在65~75和80~90。
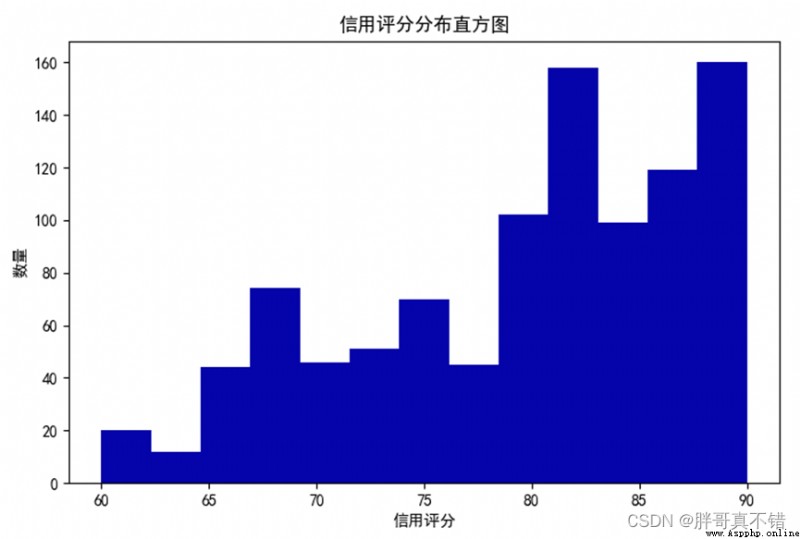
4.2 信用評分直方圖
用Matplotlib工具的hist()方法繪制直方圖:
通過上圖可以看到,信用評分在80~90分的人居多,說明大部分人信用都是良好的。
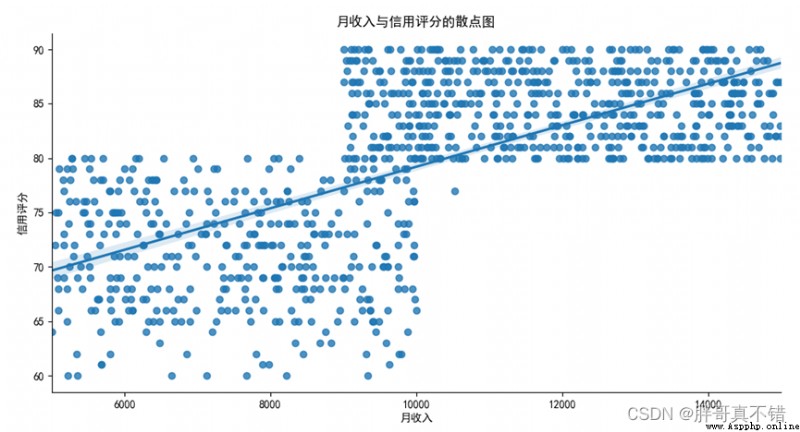
4.3 數據的散點圖
通過散點圖擬合線顯示月收入和信用評分之間的趨勢關系:
通過上圖可以看到,月收入和信用評分沒有呈線性關系。
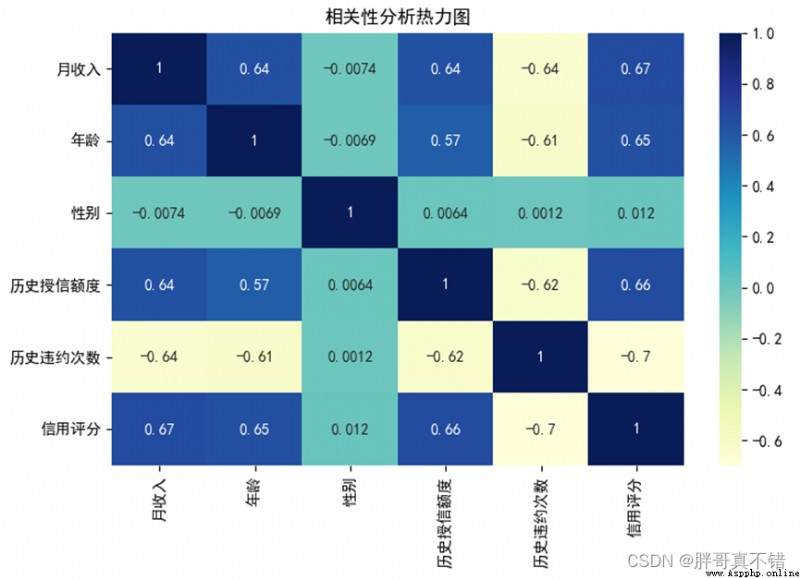
4.4 相關性分析
從上圖中可以看到,數值越大相關性越強,正值是正相關、負值是負相關。
5.特征工程
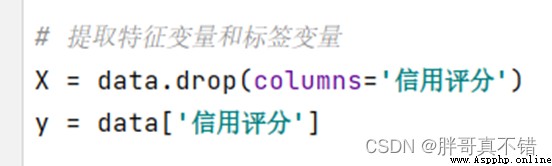
5.1 建立特征數據和標簽數據
關鍵代碼如下:
5.2 數據集拆分
通過train_test_split()方法按照80%訓練集、20%測試集進行劃分,關鍵代碼如下:
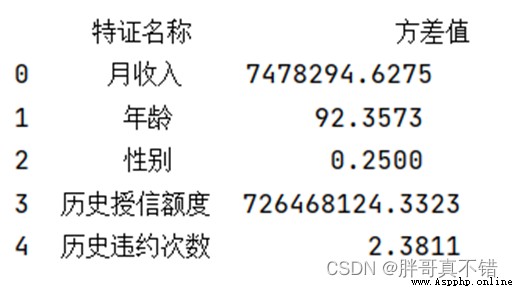
5.3 低方差過濾法特征選擇
使用VarianceThreshold()低方差過濾法進行特征選擇,關鍵代碼如下:
返回的結果:
從上圖可以看出,阈值是0.21,所有特征的方差值均大於0.21,所以不需要去掉一些特征。
6.構建遺傳算法回歸模型
遺傳算法基於創建初始種群迭代地組合群體成員,從而根據父母的“特征/參數”創建子代的思想。在每次迭代結束時,我們進行擬合測試,並將把最適合的個體從原始的種群取出+新的種群被創建。因此,在每次迭代中,我們將創建新的後代,如果後代表現更好,就可以用它們取代現有的個體。這使得總體性能增加或者至少在每次迭代保持相同。
TPOT支持的回歸器主要有決策樹、集成樹、線性模型、xgboost。
主要使用TPOTRegressor算法,用於目標回歸。
6.1模型參數
7.模型評估
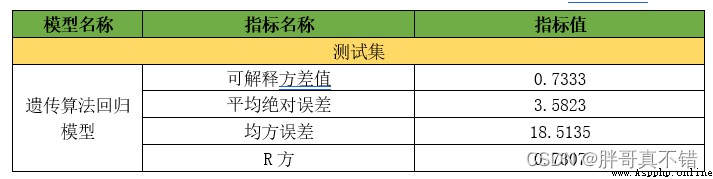
7.1評估指標及結果
評估指標主要包括可解釋方差值、平均絕對誤差、均方誤差、R方值等等。
從上表可以看出,R方為73.07% 可解釋方差值為73.33%,GBDT回歸模型效果良好,如果想要取得更好的效果,可以調整一下參數,generations調整為100,population_size調整為1000,不過運行時間會非常久的。
關鍵代碼如下:
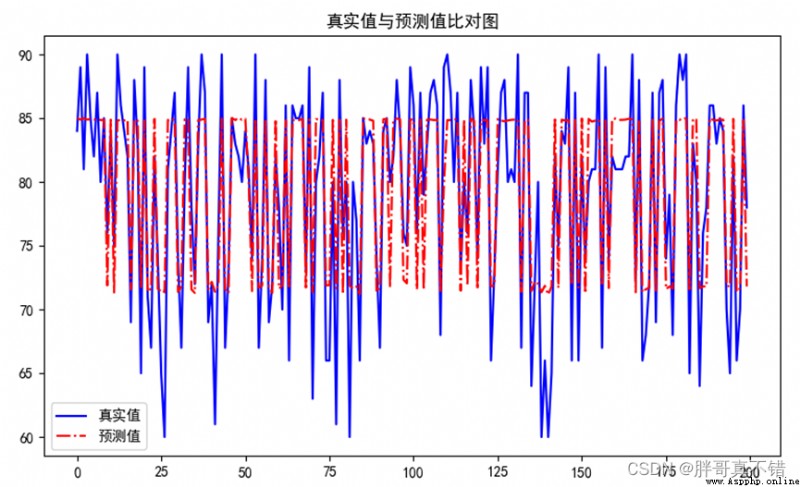
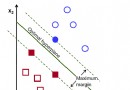
7.2 真實值與預測值對比圖
從上圖可以看出真實值和預測值波動基本一致,模型擬合效果良好。
8.結論與展望
綜上所述,本文采用了遺傳算法回歸模型,最終證明了我們提出的模型效果良好。此模型可用於日常信用評分。
本次機器學習項目實戰所需的資料,項目資源如下:
項目說明:
鏈接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取碼:bcbp網盤如果失效,可以添加博主微信:zy10178083