1、django and scrapy How to combine
2、 adopt django start-up scrapy Reptiles
This article only introduces Django and scrapy Simple implementation of , Suitable for friends who want to get started quickly .
Django Projects can be created with commands , It can also be used. pycharm Manually create . This article uses pycharm Manually create .
1、 Use pycharm establish Django project : menu bar File-->New project-->Django--> Fill in the project name pro,app The name is app01-->create.
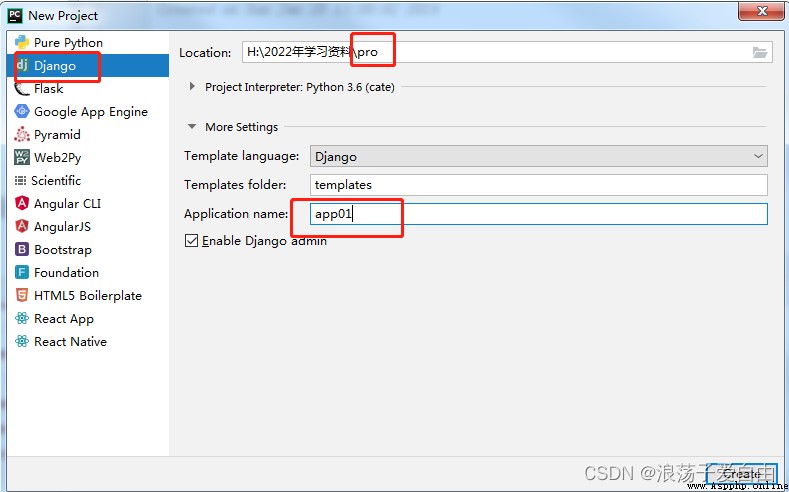
At this point, the directory structure of the project is as follows ,app01 For projects pro Sub application of .
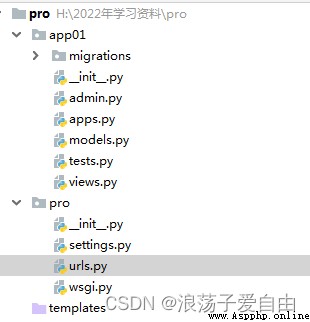
2、 Create a home page , The content of the home page is " This is a test page ".
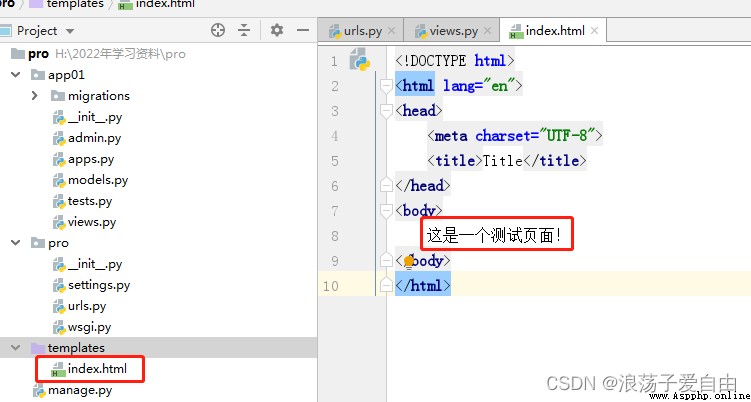
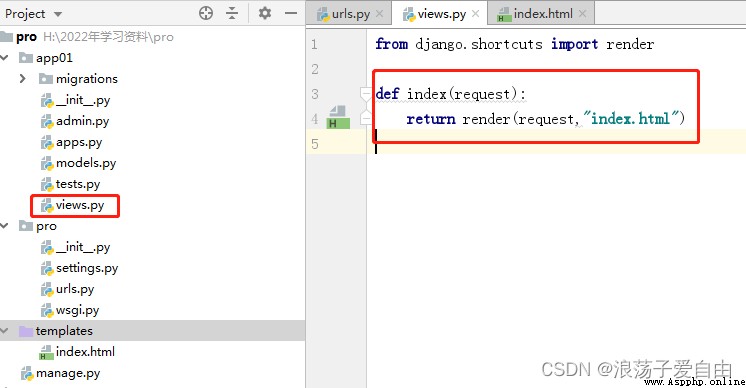
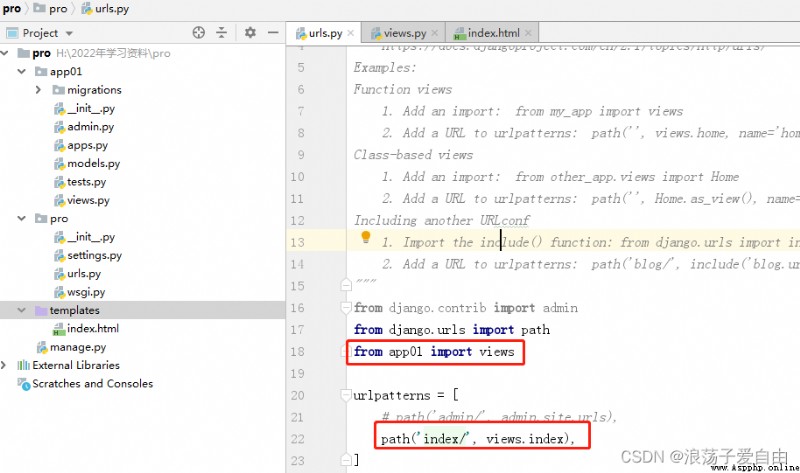
3、 Run the program , Enter... In the browser http://127.0.0.1:8000/index/. appear 【 This is a test page !】 The successful .
demo download : Use alone django Framework creation web project -Webpack Document resources -CSDN download Use alone django Framework creation web Project more download resources 、 For learning materials, please visit CSDN Download channel . https://download.csdn.net/download/weixin_56516468/85745510
https://download.csdn.net/download/weixin_56516468/85745510
One 、 preparation
scrapy install : Make sure it is installed scrapy, If not installed , Then open cmd, Input pip install scrapy.

Common commands :
scrapy startproject Project name # establish scrapy project
scrapy genspider Reptile name domain name
scrapy crawl Reptile name Task description :
1、 Climb phoenix net , The address is :http://app.finance.ifeng.com/list/stock.php?t=ha, Crawl to the Shanghai Stock Exchange on this page A Code of shares 、 name 、 Latest price and other information .
2、 Save files in H:\2022 Annual learning materials in .
3、 The project is called ifengNews
Two 、 Implementation steps
1、 Use cmd Enter to gen Catalogue of construction projects 【2022 Learning materials 】, Use command 【scrapy startproject ifengNews】 establish scrapy project .
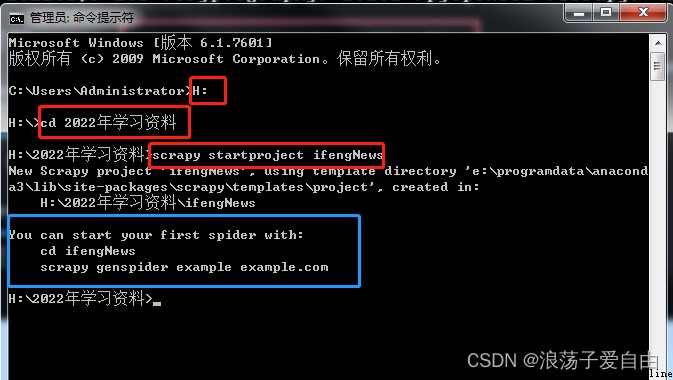
effect : appear 【 Blue frame 】 Content ,【ifengNews】 The project has been created successfully .
2、 Use pycharm Open folder 【ifengNews】. The file directory is as follows :

items.py: Define the data model of the crawler
middlewares.py: Define the middleware in the data model
pipelines.py: Pipeline files , Responsible for processing the data returned by the crawler
settings.py: Crawler settings , Mainly some priority settings ( take ROBOTSTXT_OBEY=True Change it to False, This line of code indicates whether the crawler protocol is followed , If it is Ture There may be some content that cannot be crawled )
scrapy.cfg: The content is scrapy The basic configuration of
spiders Catalog : place spider Code directory
3、 stay pycharm Input... In the terminal 【scrapy genspider ifeng_spider ifeng.com】 among :ifeng_spider File name , You can customize , But it can't be the same as the project name ;ifeng.com Is the domain name .
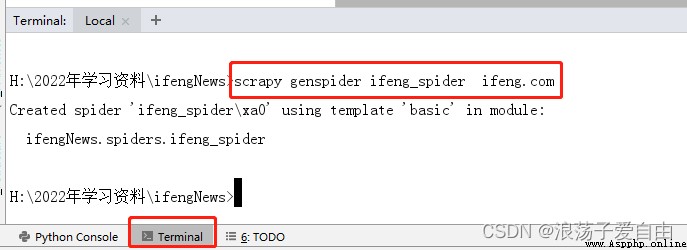
effect :spiders Create one under the folder ifeng_spider.py file , The crawler code is written in this file def parse in .
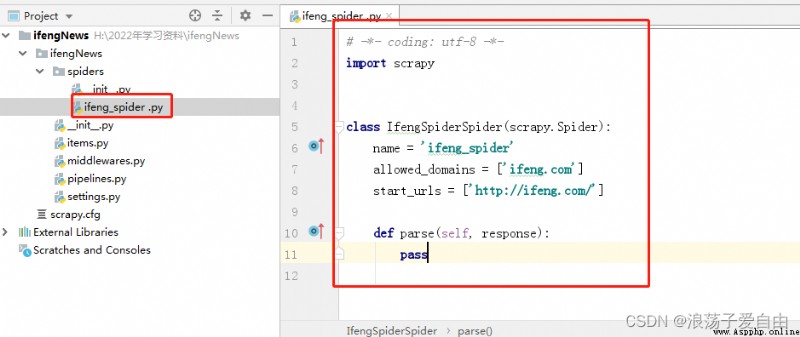
3.1 This step can also be done in cmd Finish in .

4、 modify setting
The first is not following the robot protocol
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # Whether the robot protocol is followed , The default is true, Need to be changed to false, Otherwise, many things can't climb The first Two One is the request header , Add one User-Agent
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Cookie':'adb_isBlock=0; userid=1652710683278_ihrfq92084; prov=cn0731; city=0732; weather_city=hn_xt; region_ip=110.53.149.x; region_ver=1.2; wxIsclose=false; ifengRotator_iis3=6; ifengWindowCookieName_919=1'
# Default is annotated , This thing is very important , If you don't write, you can easily be judged as a computer , Simply wash one Mozilla/5.0 that will do
}The first Three is to open a pipe
# ITEM_PIPELINES: Project pipeline ,300 For priority , The lower the climb, the higher the priority
ITEM_PIPELINES = {
'ifengNews.pipelines.IfengnewsPipeline': 300,
# 'subeiNews.pipelines.SubeinewsMysqlPipeline': 200, # A pipeline for storing data
}5、 Page crawl . First, in the ifeng_spider.py Write your own crawler file in :
import scrapy
from ifengNews.items import IfengnewsItem
class IfengSpiderSpider(scrapy.Spider):
name = 'ifeng_spider'
allowed_domains = ['ifeng.com']
start_urls = ['http://app.finance.ifeng.com/list/stock.php?t=ha'] # Crawl address
def parse(self, response):
# Crawling stock specific information
for con in response.xpath('//*[@class="tab01"]/table/tr'):
items = IfengnewsItem()
flag = con.xpath('./td[3]//text()').get() # The latest price
if flag:
items['title'] = response.xpath('//div[@class="block"]/h1/text()').get()
items['code'] = con.xpath('./td[1]//text()').get() # Code
items['name'] = con.xpath('./td[2]//text()').get() # name
items['latest_price'] = con.xpath('./td[3]//text()').get() # The latest price
items['quote_change'] = con.xpath('./td[4]//text()').get() # applies
items['quote_num'] = con.xpath('./td[5]//text()').get() # Up and down
items['volume'] = con.xpath('./td[6]//text()').get() # volume
items['turnover'] = con.xpath('./td[7]//text()').get() # turnover
items['open_today'] = con.xpath('./td[8]//text()').get() # Opening today
items['closed_yesterday'] = con.xpath('./td[9]//text()').get() # It closed yesterday
items['lowest_price'] = con.xpath('./td[10]//text()').get() # The lowest price
items['highest_price'] = con.xpath('./td[11]//text()').get() # Highest price
print(items['title'], items['name'])
yield items
open items.py, change items.py For storing data :
import scrapy
class IfengnewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
latest_price = scrapy.Field()
quote_change = scrapy.Field()
quote_num = scrapy.Field()
volume = scrapy.Field()
turnover = scrapy.Field()
open_today = scrapy.Field()
closed_yesterday = scrapy.Field()
lowest_price = scrapy.Field()
highest_price = scrapy.Field()
If you want to implement secondary pages 、 Page turning and other operations , You need to learn by yourself .
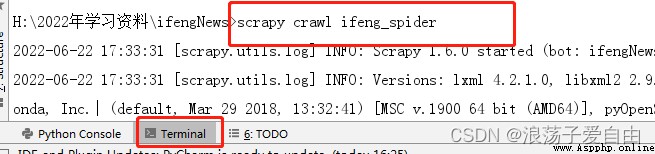
6、 Run crawler : Input in the terminal 【scrapy crawl ifeng_spider】.
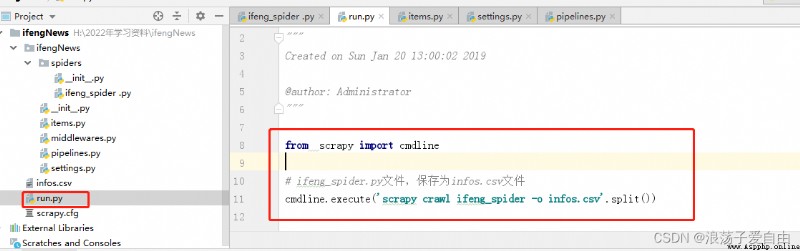
6.1 It's fine too Write a run.py File to run the program , Store data in infos.csv in .
demo download : Use alone scrapy Implement a simple crawler -Python Document resources -CSDN download Use alone scrapy Implement simple crawler to download more resources 、 For learning materials, please visit CSDN Download channel .https://download.csdn.net/download/weixin_56516468/85745577
Task description : take Django and scrapy combination , Through Django control scrapy Operation of , And store the crawled data into the database .
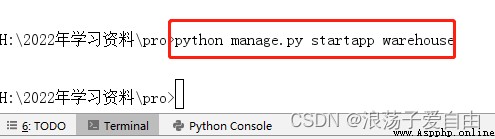
1、 stay Django Create a sub application in the root directory of the project warehouse, Separate storage scrapy Database and other information . Create... Using the command line app, Enter the execute command at the terminal :python manage.py startapp warehouse.
The directory structure at this time :
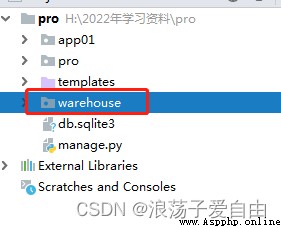
And in pro-settings.py Register in warehouse The application of , Here's the picture .
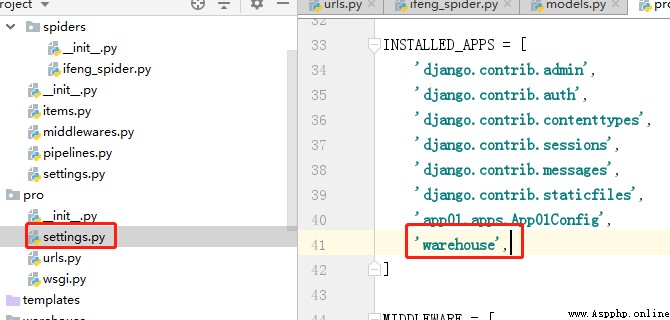
2、 stay Django Create... In the project scrapy project , And modify the project setting.py, And the steps in task 2 4 Agreement .
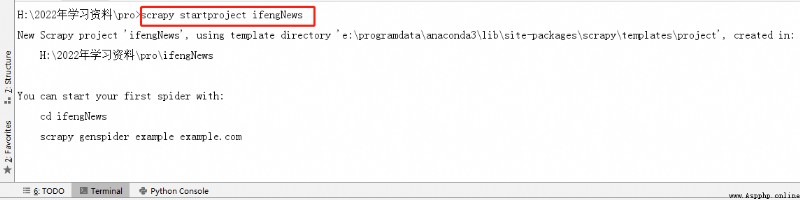

And adjust the directory structure , Consistent with the figure below :
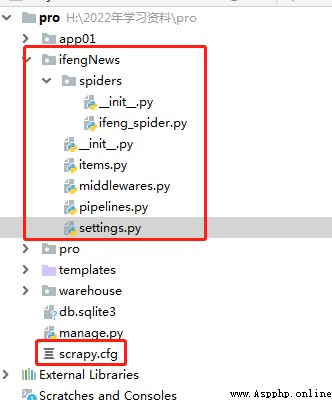
3、 stay scrapy Of setting.py Add the following code to :
import os
import sys
import django
sys.path.append(os.path.dirname(os.path.abspath('.')))
os.environ['DJANGO_SETTINGS_MODULE'] = 'pro.settings' # Project name .settings
django.setup()4、warehouse Under the model.py Create database , Used to store crawled data . And execute the command at the terminal python manage.py makemigrations and python manage.py migrate, Generate database tables .
from django.db import models
class StockInfo(models.Model):
"""
Stock information
"""
title = models.TextField(verbose_name=" Stock type " )
code = models.TextField(verbose_name=" Code " )
name = models.TextField(verbose_name=" name " )
latest_price = models.TextField(verbose_name=" The latest price " )
quote_change = models.TextField(verbose_name=" applies " )
quote_num = models.TextField(verbose_name=" Up and down " )
volume = models.TextField(verbose_name=" volume " )
turnover = models.TextField(verbose_name=" turnover " )
open_today = models.TextField(verbose_name=" Opening today " )
closed_yesterday = models.TextField(verbose_name=" It closed yesterday " )
lowest_price = models.TextField(verbose_name=" The lowest price " )
highest_price = models.TextField(verbose_name=" Highest price " )
5、 modify pipelines.py 、 items.py 、 ifeng_spider.py.
ifeng_spider.py:
import scrapy
from ifengNews.items import IfengnewsItem
class IfengSpiderSpider(scrapy.Spider):
name = 'ifeng_spider'
allowed_domains = ['ifeng.com']
start_urls = ['http://app.finance.ifeng.com/list/stock.php?t=ha']
def parse(self, response):
# Crawling stock specific information
for con in response.xpath('//*[@class="tab01"]/table/tr'):
items = IfengnewsItem()
flag = con.xpath('./td[3]//text()').get() # The latest price
if flag:
items['title'] = response.xpath('//div[@class="block"]/h1/text()').get()
items['code'] = con.xpath('./td[1]//text()').get() # Code
items['name'] = con.xpath('./td[2]//text()').get() # name
items['latest_price'] = con.xpath('./td[3]//text()').get() # The latest price
items['quote_change'] = con.xpath('./td[4]//text()').get() # applies
items['quote_num'] = con.xpath('./td[5]//text()').get() # Up and down
items['volume'] = con.xpath('./td[6]//text()').get() # volume
items['turnover'] = con.xpath('./td[7]//text()').get() # turnover
items['open_today'] = con.xpath('./td[8]//text()').get() # Opening today
items['closed_yesterday'] = con.xpath('./td[9]//text()').get() # It closed yesterday
items['lowest_price'] = con.xpath('./td[10]//text()').get() # The lowest price
items['highest_price'] = con.xpath('./td[11]//text()').get() # Highest price
print(items['title'], items['name'])
yield itemspipelines.py:
class IfengnewsPipeline(object):
def process_item(self, item, spider):
print(' Open the database ')
item.save()
print(' Shut down the database ')
return itemitems.py in , Import DjangoItem, Connect to the database .
from warehouse.models import StockInfo
from scrapy_djangoitem import DjangoItem
class IfengnewsItem(DjangoItem):
django_model = StockInfo Install as shown in the figure below scrapy_djangoitem: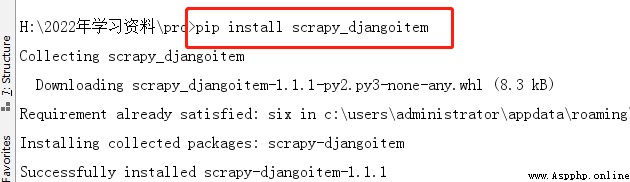 5、
5、
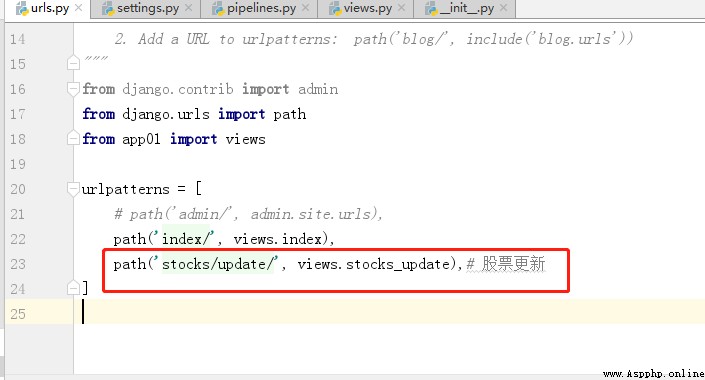
6、 modify url.py 、views.py
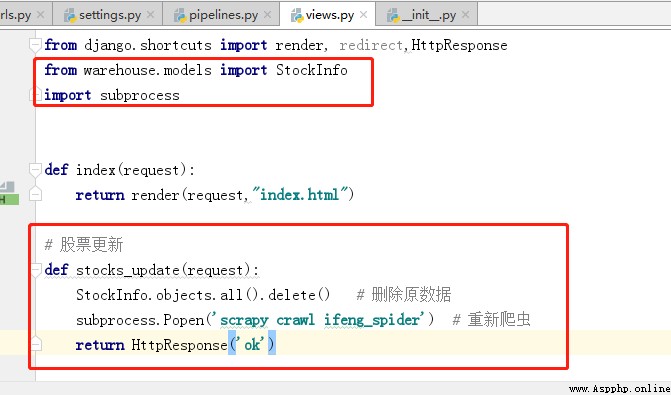
7、 Run the program , Enter... In the browser http://127.0.0.1:8000/stocks/update/. Page back ok, You can view the crawled data in the database .
demo download :
django+scrapy combination -Python Document resources -CSDN download take Django and scrapy combination , Through Django control scrapy Operation of , And save the crawled data to more data download resources 、 For learning materials, please visit CSDN Download channel .https://download.csdn.net/download/weixin_56516468/85750917