I'm sure that all of you have introduced Python+Selenium The basic chapter , Through the introduction and practice of the previous articles ,Selenium+Python Of webUI Automated testing is One foot has reached the threshold. If you want the second foot to come in . Then we should continue to follow brother Hong's footsteps and move on . Next , Macro brother
Plan to write a second series : Exercises , Through some practice , Understand and master some Selenium A common interface or method . At the same time, you can also lay a solid foundation for your little friends or children's shoes 、 Consolidate . This will help children or students to step in their second foot outside the door faster , Join the team of automated tests .
In this paper, three knowledge points are practiced : Regular extraction keywords 、ID and tag name location web Page elements .
for example : We are interested in some fields or keywords on a certain web page , We want to extract it , Other operations . But these fields may be in different places on a web page . for example , We need to be on Baidu page - Contact us , Pick up all the mailboxes .
1. First , Need to get the source Content , It's like , Open a page , Right click - View page source code .
2. Find out the rules , Use regular expressions to extract matching fields , Store in a dictionary or list .
3. To print in a dictionary or list ,Python of use for Statements for .
1. View the source code of the page , stay Selenium There is driver.page_source This way we get
2. Python Using regular , Import required re modular
3. Print out the fields with the following code
for email in emails : print email
Ideas and techniques are all found , We build a new one extract_email.py file , Enter the following code :
# coding=utf-8
# 1. Set code first ,utf-8 Support Chinese and English , Above , Usually put it on the first line
# 2. notes : Include record creation time , founder , Project name .
'''
Created on 2019-11-28
@author: Beijing - Macro brother QQ Communication group :705269076
Project: python+ selenium Automation test exercises
'''
# 3. The import module
from selenium import webdriver
import re
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("http://home.baidu.com/contact.html")
# Get the page source code
doc = driver.page_source
emails = re.findall(r'[\w][email protected][\w\.-]+', doc) # Use regular , find [email protected] Field of , Save to emails list
# Loop print matching mailbox
for email in emails:
print(email)stay python In regular expression syntax ,Python Add... Before the middle string r Represents a native string , use \w Match alphanumeric and underline .re Under module findall Method returns a list of matching substrings .
After running the code , The console prints the following results
On top , We showed you how to extract page fields , Match the fields that meet the requirements through regular . If it feels a little difficult , Can't understand immediately , It doesn't matter. . Take the string and put it in the first part , Because automated test scripts , Always use string operations , String cutting , lookup , Match, etc , Get a new string or array of strings , Then judge whether the use case passes or not according to the new string .
Here's how to use element node information ID To locate the element , Use id To locate elements even though they are more efficient than XPath, But the actual test items , Can go straight through id The positioning elements are still relatively few , Take Baidu home page search input box as an example id location .
We build a new one test_baidu_id.py file , Enter the following code :
# coding=utf-8
# 1. Set code first ,utf-8 Support Chinese and English , Above , Usually put it on the first line
# 2. notes : Include record creation time , founder , Project name .
'''
Created on 2019-11-28
@author: Beijing - Macro brother QQ Communication group :705269076
Project: python+ selenium Automation test exercises
'''
# 3. The import module
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("https://www.baidu.com")
try:
driver.find_element_by_id("kw")
print ('test pass: ID found')
except Exception as e:
print ("Exception found", format(e))
driver.quit()here , We go through try except Statement block to test assertions , This is in the actual automated test script development , It's often used to handle exceptions . this paper , We have learned to make use of find_element_by_id() Method to locate the web element object .
5.3 Running results :
After running the code , The console prints the following results
How to pass through the elements is introduced in the front id Value to locate web Elements , How does this article describe tag name To locate elements . Personally think that , adopt tag name There is still a big flaw in positioning , Positioning is not accurate enough . Mainly tag name There's a lot of repetition , Made a choice tag name To locate page elements is not accurate , So use this method to locate web There are few opportunities for elements .
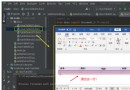
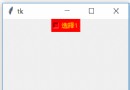
What is? tag name? Or Baidu home search input box , In Firefox , Right click , adopt firepath, Check elements , Look at the picture below :
In the above picture, the label names of the red circle areas are tag name; In fact, our target element is the input box , Should be input This tag name, In the blue highlighted area . But if only through input This tag name To locate , I found a lot of input The option to . So we expand the reference selection of nodes , Let's choose the one above
form Come as us tag name.
See how to write positioning form The script for this element :
# coding=utf-8
# 1. Set code first ,utf-8 Support Chinese and English , Above , Usually put it on the first line
# 2. notes : Include record creation time , founder , Project name .
'''
Created on 2019-11-28
@author: Beijing - Macro brother QQ Communication group :705269076
Project: python+ selenium Automation test exercises
'''
# 3. The import module
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("https://www.baidu.com")
try:
driver.find_element_by_tag_name("form")
print ('test pass: tag name found')
except Exception as e:
print ("Exception found", format(e))
driver.quit()After running the code , The console prints the following results
summary : This paper introduces webdriver Among the eight positioning element methods driver.find_element_by_tag_name("form") # form yes tag name From the perspective of automatic script development in actual projects , There are fewer opportunities to use this method to locate elements , Just know there is such a way .
Your affirmation is the driving force of my progress . If you feel good , Please encourage me ! Remember to wave recommend Don't forget !!!
In order to make it convenient for you to see the blog I shared on the mobile terminal , The registered WeChat official account is now registered , Scan the QR code at the bottom left , Welcome to pay attention , I will share related technical blogs in time . In order to facilitate the interactive discussion of relevant technical issues , Now we have set up a special wechat group , Because wechat group is full 100, Please scan Hongge's personal wechat QR code at the bottom right to pull you into the group ( Please note : You have followed the official account into the group ) Usually busy at work ( same as you do ), So it's not timely to add friends , Please take a moment ~, Welcome to join this family , Let's enjoy the ocean of knowledge . Thank you for taking the time to read this article , If you think that you have learned something in this article in order to reward the bloggers, you may as well give them a reward , Let bloggers have a cup of coffee , Thank you for ! If you think reading this article will help you , Please click on the lower left corner “ recommend ” Button , Your “ recommend ” It will be my biggest driving force for writing ! You can also choose 【 Pay attention to me 】, It's easy to find me ! The copyright of this article belongs to the author and blog Park , Source URL :https://www.cnblogs.com/du-hong Welcome to reprint , But without the author's consent , After the reprint of the article, the author and the original link must be provided in the obvious position of the article page , Otherwise, the right to pursue legal responsibility is reserved !