列表可以一次性存儲多個數據,並且可以是不同的數據類型。
[數據1,數據2,數據3,數據4......]
name_list = ['Tom', 'Lily', 'Rose']
print(name_list[0])# Tom
print(name_list[1])# Lily
print(name_list[2])# Rose
查找函數:
index():返回指定數據所在位置的下標。
name_list = ['Tom', 'Lily', 'Rose']
print(name_list.index('Lily', 0, 2))# 1
# 如果查找的數據不存在就報錯
count():統計指定數據在當前列表中出現的次數。
name_list = ['Tom', 'Lily', 'Rose']
print(name_list.count('Lily'))# 1
len():訪問列表⻓度,即列表中數據的個數。
name_list = ['Tom', 'Lily', 'Rose']
print(len(name_list))# 3
in:判斷指定數據在某個列表序列,如果在返回True,否則返回False
name_list = ['Tom', 'Lily', 'Rose']
#結果:True
print('Lily'in name_list)
#結果:False
print('Lilys'in name_list)
not in:判斷指定數據不在某個列表序列,
如果不在返回True,否則返回False
name_list = ['Tom', 'Lily', 'Rose']
#結果:False
print('Lily' not in name_list)
#結果:True
print('Lilys'not in name_list)

增加:
(1)append():列表末尾增加數據。列表追加數據的時候,直接在原列表⾥⾯追加了指定數據,即修改了原列表,故列表為可變類型數據。
列表序列.append(數據)
name_list = ['Tom', 'Lily', 'Rose']
name_list.append('xiaoming')
#結果:['Tom','Lily','Rose', 'xiaoming']
print(name_list)
name_list.append(11,22)
print['Tom', 'Lily', 'Rose',[11,22]]
note:如果append()追加的數據是⼀個序列,則追加整個序列到列表.
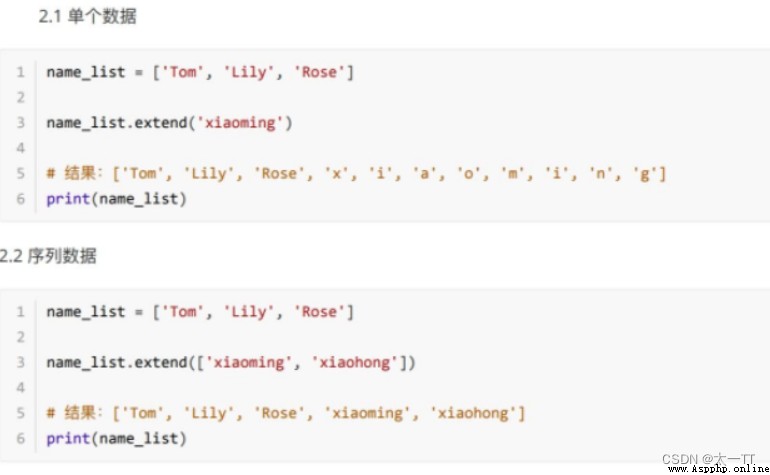
(2)extend():列表結尾追加數據,如果數據是⼀個序列,則將這個序列的數據逐⼀添加到列表。
列表序列.extend(數據)S
(3)insert():指定位置新增數據
列表序列.insert(位置下標,數據)
name_list = ['Tom', 'Lily', 'Rose']
name_list.insert(1, 'xiaoming')
#結果:['Tom','xiaoming', 'Lily', 'Rose']
print(name_list)
刪除: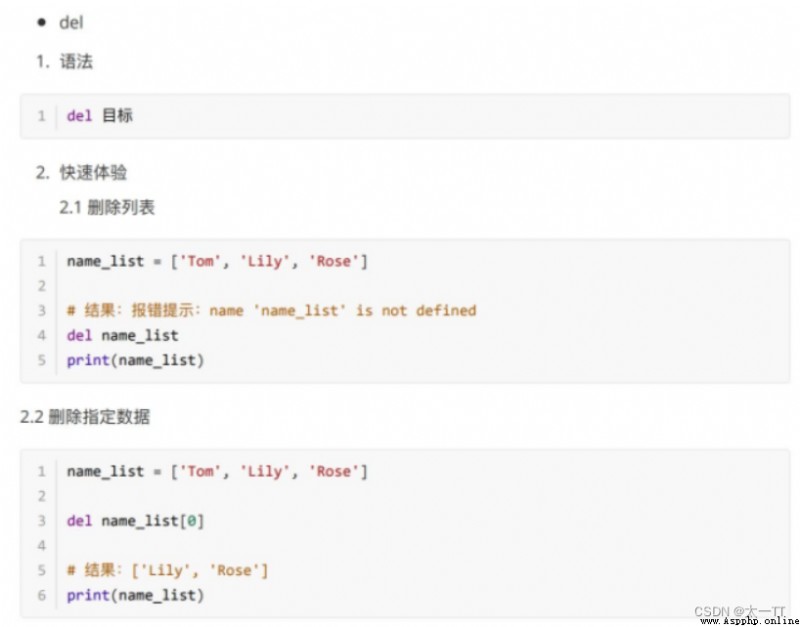
pop():刪除指定下標的數據(如果不指定默認的下標,默認為最後⼀個),並返回該數據。
name_list = ['Tom', 'Lily', 'Rose']
del_name = name_list.pop(1)
#結果:Lily
print(del_name)
#結果:['Tom','Rose']
print(name_list)
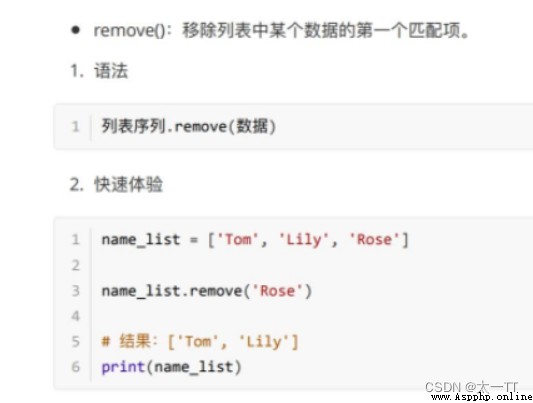
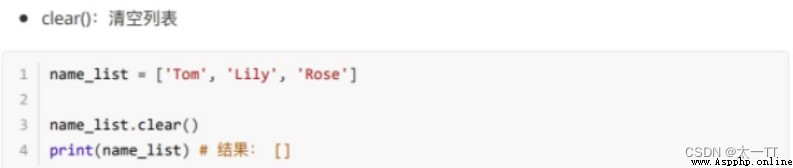
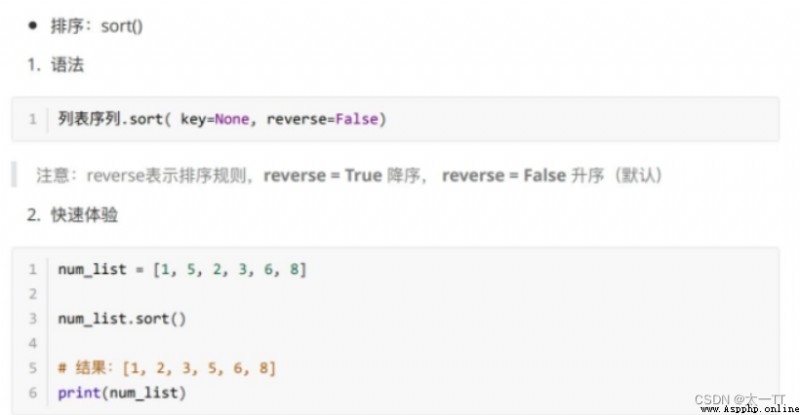
修改:修改指定下標數據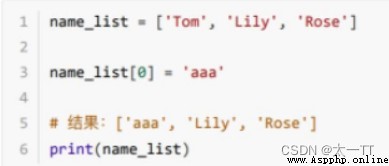

列表的循環遍歷:
name_list=['Tom','Lily','Rose']
i=0
while i<len(name_list);
print(name_list[i])
i+=1
for i in name_list:
print(i)
列表嵌套:
所謂列表嵌套指的就是⼀個列表⾥⾯包含了其他的⼦列表。
應⽤場景:要存儲班級⼀、⼆、三三個班級學⽣姓名,且每個班級的學⽣姓名在⼀個列表。
name_list = [['⼩明','⼩紅','⼩綠'],['Tom','Lily', 'Rose'],['張三','李四','王']]
需求:隨機分配辦公室
有三個辦公室,8位⽼師,8位⽼師隨機分配到3個辦公室
#准備數據(8老師+3辦公室)
import random
teachers=['A','B','C','D','E','F','G','H']
offices=[[],[],[]]
#分配座位到辦公室,取到每個老師到辦公室列表中
for name in teachers:
num=random.randint(0,2);
offices[num].append(name)
#檢查是否分配成功
for office in offices:
print(f'辦公室人數{
len(office)},老師名字')
for name in office:
print(name)
列表可以⼀次性存儲多個數據,但是列表中的數據允許更改。⼀個元組可以存儲多個數據,元組內的數據是不能修改的。
元組特點:定義元組使⽤⼩括號,且逗號隔開各個數據,數據可以是不同的數據類型。如果定義的元組只有⼀個數據,那麼這個數據後⾯也好添加逗號,否則數據類型為唯⼀的這個數據的數據類型。
 元組數據不⽀持修改,只⽀持查找。
元組數據不⽀持修改,只⽀持查找。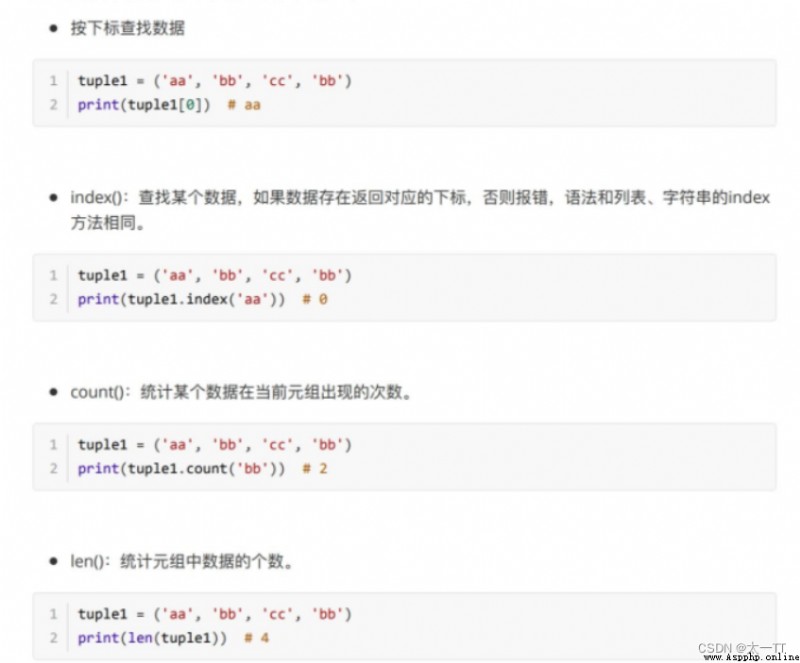

創建集合使⽤{123}或set(),但是如果要創建空集合只能使⽤set(),因為{}⽤來創建空字典。
s1 = {
10, 20, 30, 40, 50}
print(s1)
s2 = {
10, 30, 20, 10, 30, 40, 30, 50}
print(s2)
s3 = set('abcdefg')
print(s3)
s4 = set()
print(type(s4))# set
s5 = {
}
print(type(s5))# dict
1.集合可以去掉重復數據;
2.集合數據是⽆序的,故不⽀持下標;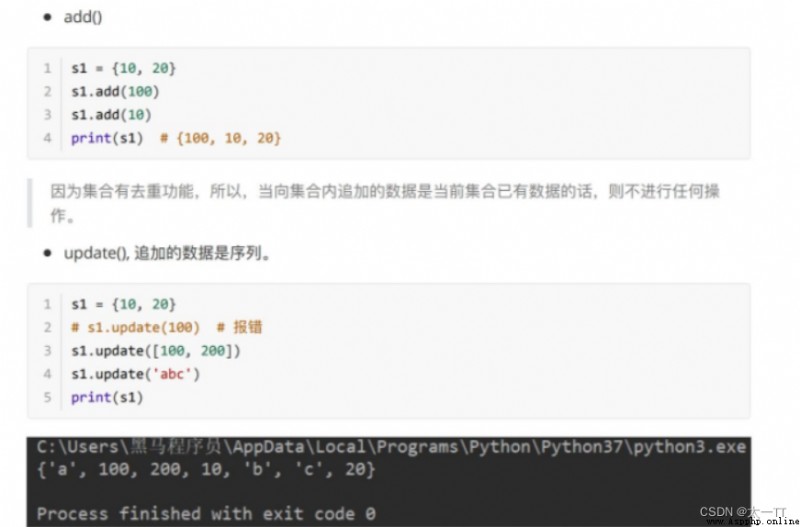
刪除數據: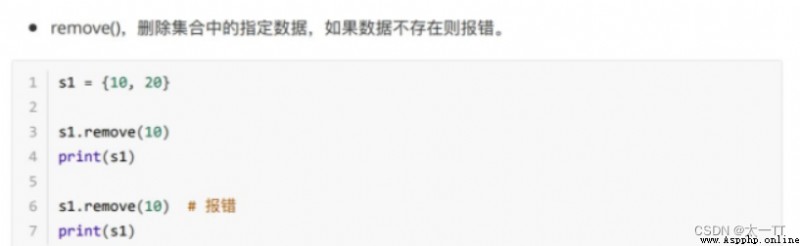
discard():刪除集合中指定數據,如果數據不存在也不會報錯
pop():隨機刪除集合中某個數據,並且返回這個數據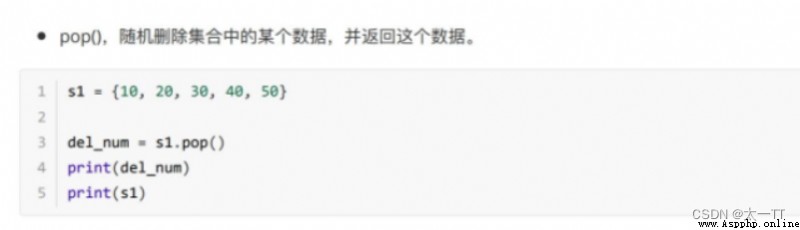
查找數據:
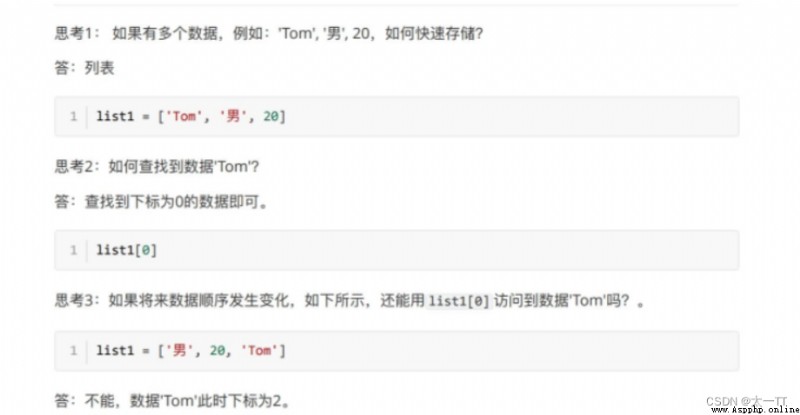 數據順序發⽣變化,每個數據的下標也會隨之變化,如何保證數據順序變化前後能使⽤同⼀的標准查找數據呢?
數據順序發⽣變化,每個數據的下標也會隨之變化,如何保證數據順序變化前後能使⽤同⼀的標准查找數據呢?
答:字典,字典⾥⾯的數據是以鍵值對形式出現,字典數據和數據順序沒有關系,即字典不⽀持下標,後期⽆論數據如何變化,只需要按照對應的鍵的名字查找數據即可。
(1)創建字典的語法:
符號為大括號+數據為鍵值對形式出現+每個鍵值對用逗號隔開
#有數據字典
dict1 = {
'name':'Tom', 'age':20, 'gender''}
#空字典
dict2 = {
}
dict3 = dict()
#⼀般稱冒號前⾯的為鍵(key),簡稱k;冒號後⾯的為值(value),簡稱v
增:字典序列[key] =值
如果key存在則修改這個key對應的值;如果key不存在則新增此鍵值對。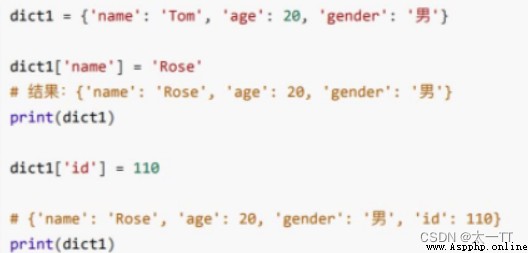
刪: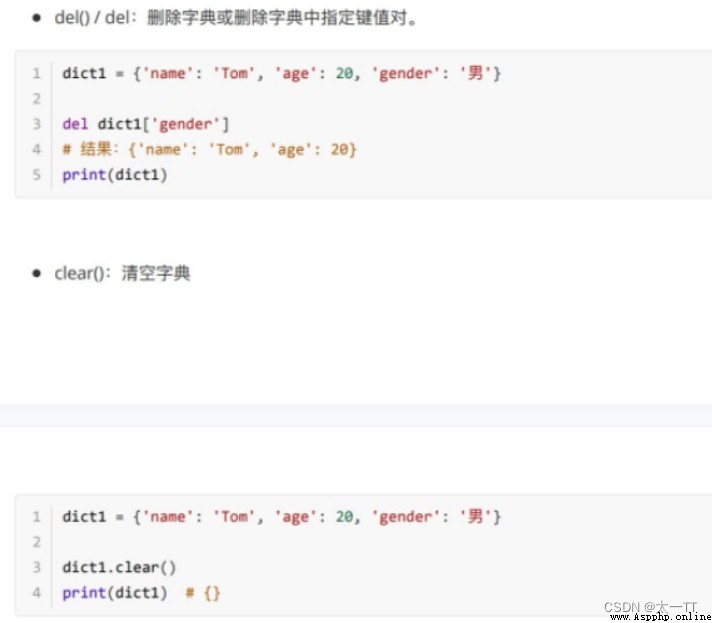
查:
(1)key值查找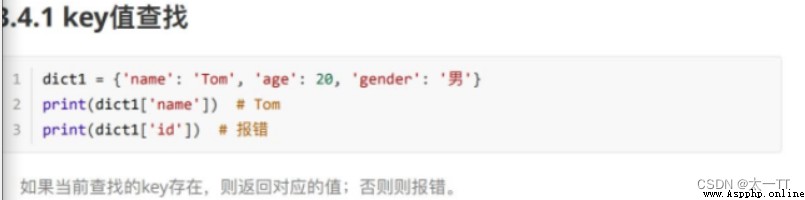 (2)get()
(2)get()
字典序列.get(key,默認值)
如果當前查找的key不存在
則返回第⼆個參數(默認值),
如果省略第⼆個參數,則返回None
 (3)keys
(3)keys
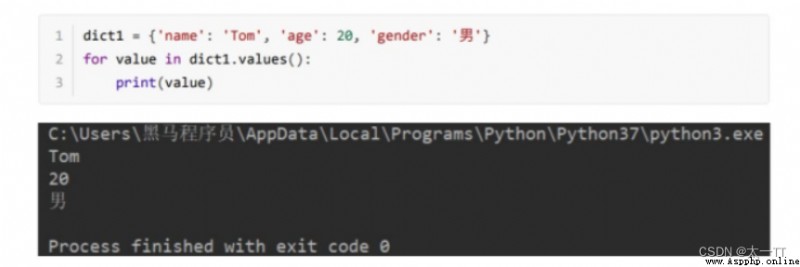
(4)values: (5)items:
(5)items:
字典的循環遍歷: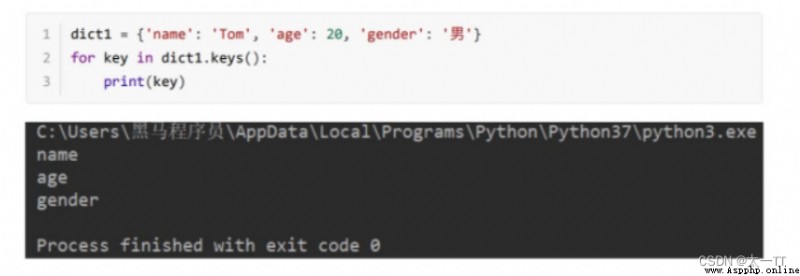
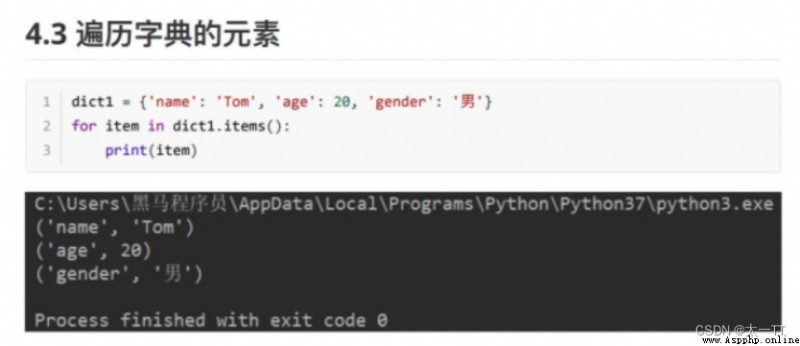
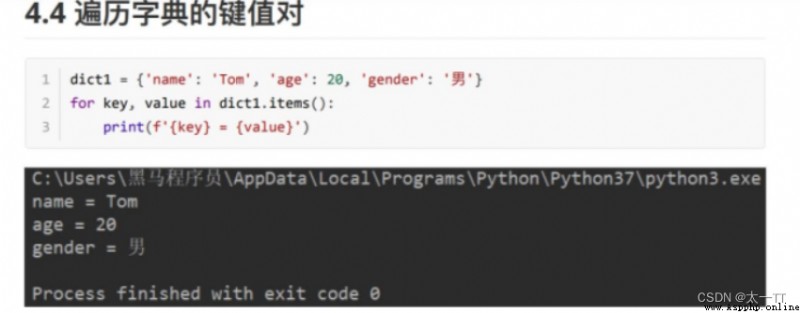
for key in dict.keys():
for value in dict.values():
for item in dict.items():# 遍歷元素
for key,value in dict.items(): #遍歷鍵值對