The list can Disposable Store multiple data , And can be different data types .
[ data 1, data 2, data 3, data 4......]
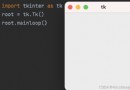
name_list = ['Tom', 'Lily', 'Rose']
print(name_list[0])# Tom
print(name_list[1])# Lily
print(name_list[2])# Rose
Lookup function :
index(): return Specify data The subscript of the position .
name_list = ['Tom', 'Lily', 'Rose']
print(name_list.index('Lily', 0, 2))# 1
# If the searched data does not exist, an error is reported
count(): Count the number of times the specified data appears in the current list .
name_list = ['Tom', 'Lily', 'Rose']
print(name_list.count('Lily'))# 1
len(): Access list ⻓ degree , That is, the number of data in the list .
name_list = ['Tom', 'Lily', 'Rose']
print(len(name_list))# 3
in: Determine whether the specified data is in a list sequence , If you are returning True, Otherwise return to False
name_list = ['Tom', 'Lily', 'Rose']
# result :True
print('Lily'in name_list)
# result :False
print('Lilys'in name_list)
not in: Judge that the specified data is not in a list sequence ,
If not returning True, Otherwise return to False
name_list = ['Tom', 'Lily', 'Rose']
# result :False
print('Lily' not in name_list)
# result :True
print('Lilys'not in name_list)

increase :
(1)append(): list At the end of Add data . When appending data to the list , Directly in the original list ⾥⾯ The specified data is appended , That is, the original list has been modified , So the list is Variable type data .
List sequence .append( data )
name_list = ['Tom', 'Lily', 'Rose']
name_list.append('xiaoming')
# result :['Tom','Lily','Rose', 'xiaoming']
print(name_list)
name_list.append(11,22)
print['Tom', 'Lily', 'Rose',[11,22]]
note: If append() The additional data is ⼀ A sequence of , The entire sequence is appended to the list .
(2)extend(): Append data to the end of the list , If the data is ⼀ A sequence of , Then the data of this sequence By ⼀ Add to list .
List sequence .extend( data )S
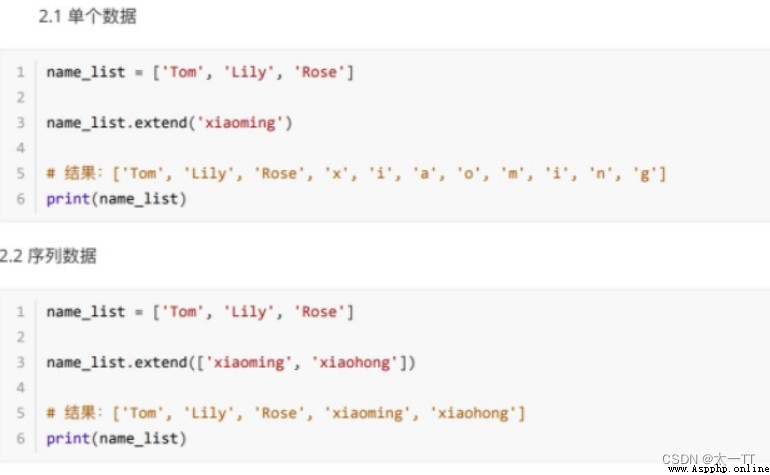
(3)insert(): Add data at the specified location
List sequence .insert( Location subscript , data )
name_list = ['Tom', 'Lily', 'Rose']
name_list.insert(1, 'xiaoming')
# result :['Tom','xiaoming', 'Lily', 'Rose']
print(name_list)
Delete :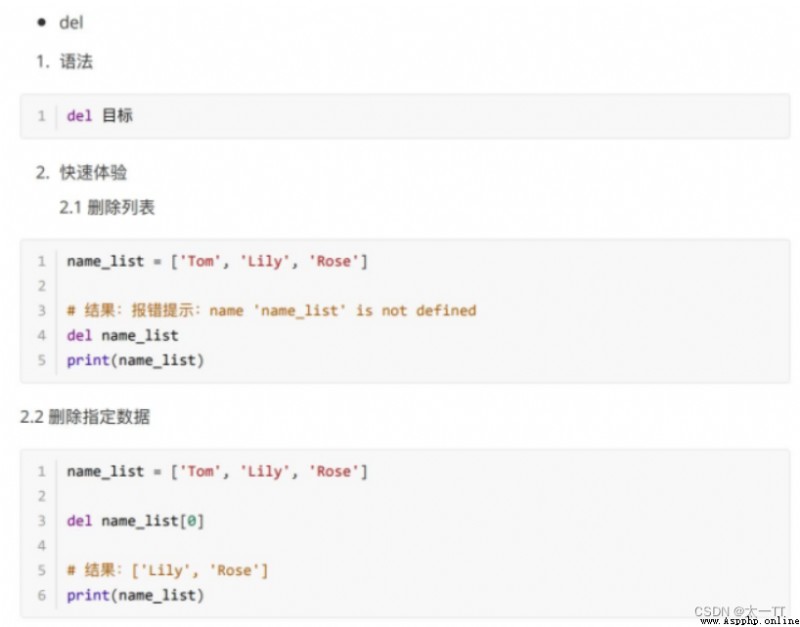
pop(): Delete Specify subscript The data of ( If you do not specify a default subscript , Default to last ⼀ individual ), And return the data .
name_list = ['Tom', 'Lily', 'Rose']
del_name = name_list.pop(1)
# result :Lily
print(del_name)
# result :['Tom','Rose']
print(name_list)
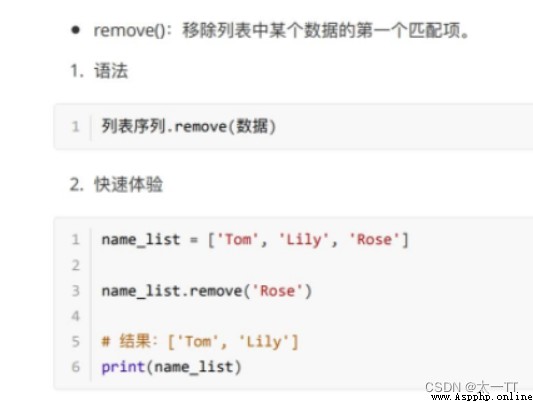
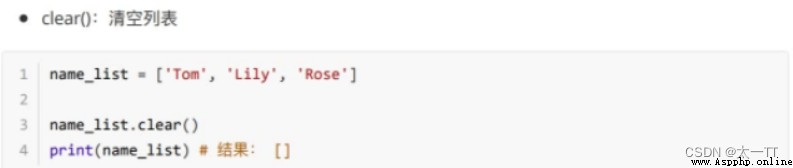
modify : Modify the specified subscript data 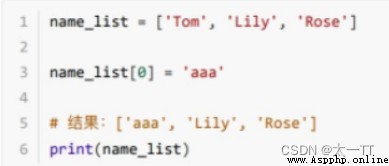

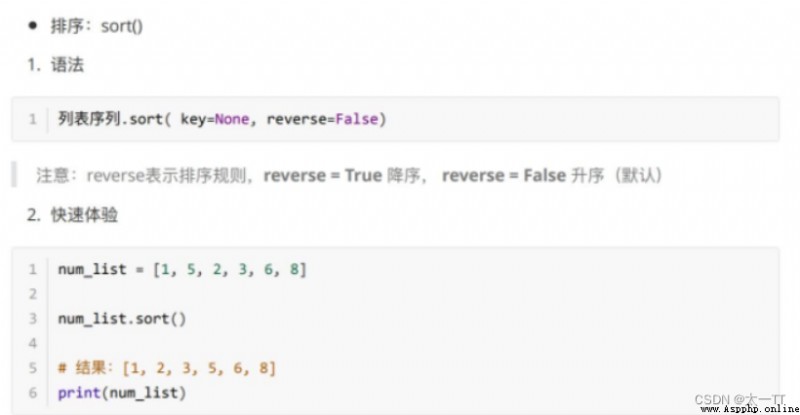
Loop traversal of list :
name_list=['Tom','Lily','Rose']
i=0
while i<len(name_list);
print(name_list[i])
i+=1
for i in name_list:
print(i)
List nesting :
The so-called list nesting refers to ⼀ A list ⾥⾯ It includes other ⼦ list .
Should be ⽤ scene : To store classes ⼀、⼆、 Three classes learn ⽣ full name , And the learning of each class ⽣ Name in ⼀ A list .
name_list = [['⼩ bright ','⼩ red ','⼩ green '],['Tom','Lily', 'Rose'],[' Zhang San ',' Li Si ',' king ']]
demand : Randomly assigned offices
There are three offices ,8 position ⽼ t ,8 position ⽼ Teachers are randomly assigned to 3 One office
# Prepare the data (8 teacher +3 The office )
import random
teachers=['A','B','C','D','E','F','G','H']
offices=[[],[],[]]
# Assign seats to the office , Get each teacher to the office list
for name in teachers:
num=random.randint(0,2);
offices[num].append(name)
# Check if the assignment is successful
for office in offices:
print(f' Office population {
len(office)}, Teacher's name ')
for name in office:
print(name)
The list can ⼀ Store multiple data at one time , But the data in the list is allowed to change .⼀ Tuples can store multiple data , Data in tuples cannot be modified .
Tuple characteristics : Define tuples to make ⽤⼩ Brackets , And comma Separate data , Data can be of different data types . If the tuple defined is only ⼀ Data , So after this data ⾯ Or add a comma , Otherwise, the data type is unique ⼀ The data type of this data .
 Tuple data does not ⽀ Hold modification , only ⽀ Hold search .
Tuple data does not ⽀ Hold modification , only ⽀ Hold search .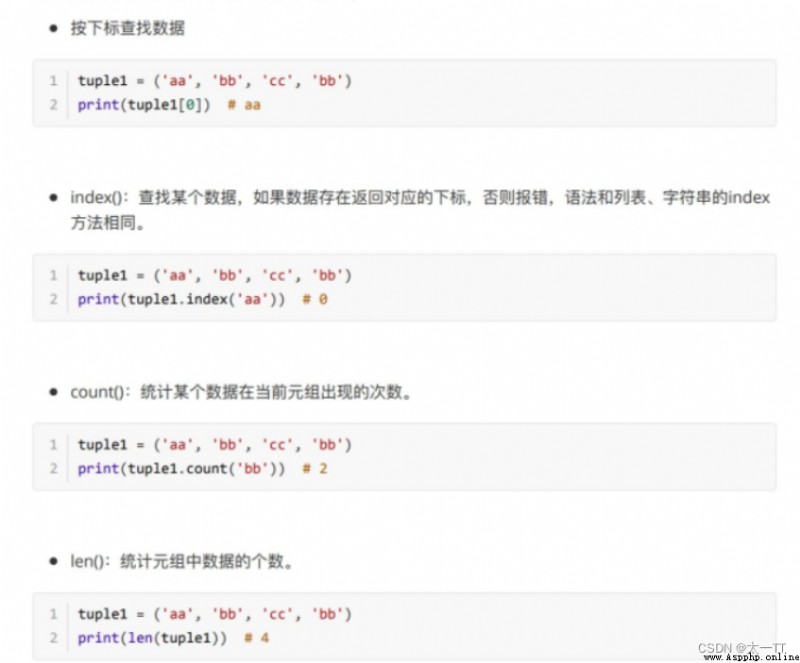

Create a collection so that ⽤{123} or set(), But if you want to create an empty collection, you can only make ⽤set(), because {}⽤ To create an empty dictionary .
s1 = {
10, 20, 30, 40, 50}
print(s1)
s2 = {
10, 30, 20, 10, 30, 40, 30, 50}
print(s2)
s3 = set('abcdefg')
print(s3)
s4 = set()
print(type(s4))# set
s5 = {
}
print(type(s5))# dict
1. Sets can remove duplicate data ;
2. The set data is ⽆ Preface , So no ⽀ Subscript holding ;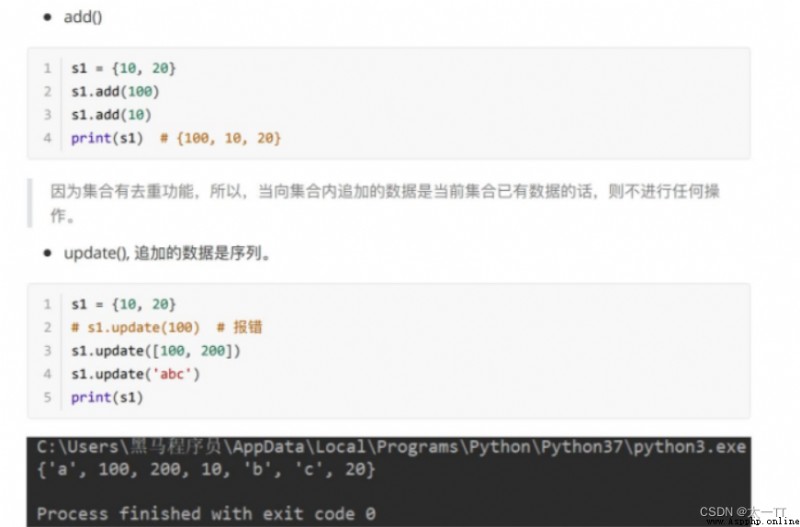
Delete data :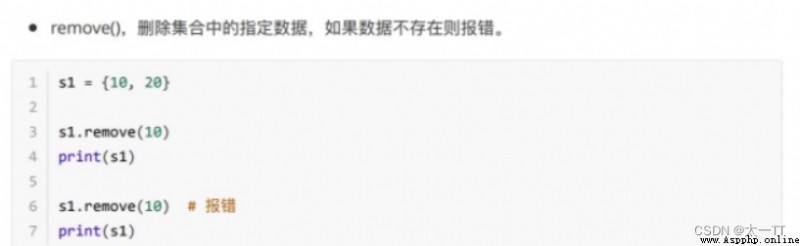
discard(): Deletes the specified data in the collection , If the data does not exist, no error will be reported 
pop(): Randomly delete a data in the set , And return this data 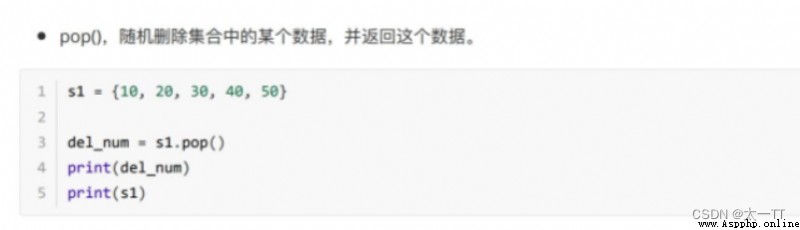
Find data :
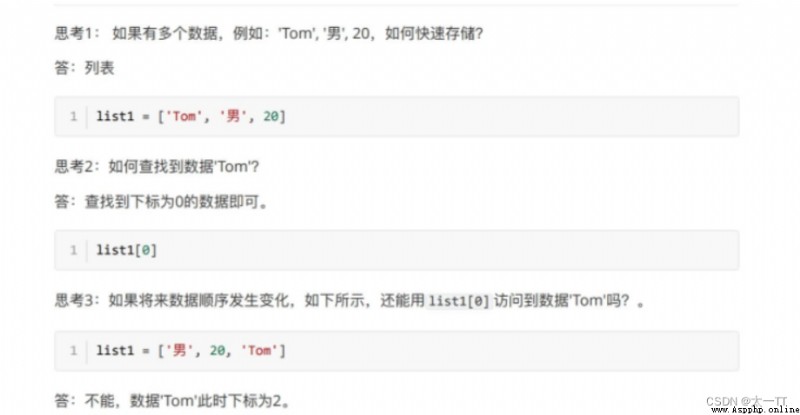 Data is sent in sequence ⽣ change , The subscript of each data will also change , How to ensure that the data sequence changes before and after ⽤ Same as ⼀ Standard search data ?
Data is sent in sequence ⽣ change , The subscript of each data will also change , How to ensure that the data sequence changes before and after ⽤ Same as ⼀ Standard search data ?
answer : Dictionaries , Dictionaries ⾥⾯ Our data is based on Key value pair Form appears , Dictionary data has nothing to do with data order , That is, the dictionary is not ⽀ Subscript holding , later stage ⽆ On how the data changes , Just follow The name of the corresponding key to find the data that will do .
(1) The syntax for creating a dictionary :
The symbols are braces + Data appears in the form of key value pairs + Each key value pair is separated by a comma
# There is a data dictionary
dict1 = {
'name':'Tom', 'age':20, 'gender''}
# An empty dictionary
dict2 = {
}
dict3 = dict()
#⼀ Before the colon ⾯ Is the key (key), abbreviation k; After the colon ⾯ The value of is (value), abbreviation v
increase : Dictionary sequence [key] = value
If key If it exists, modify this key Corresponding value ; If key If it does not exist, add this key value pair .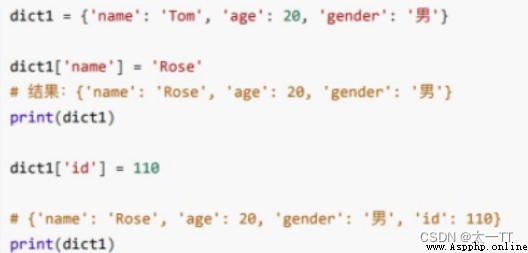
Delete :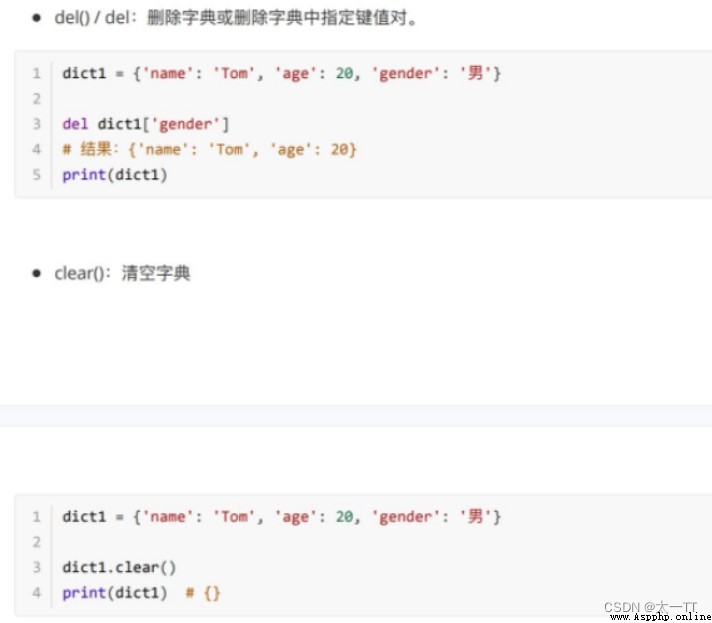
check :
(1)key Value search 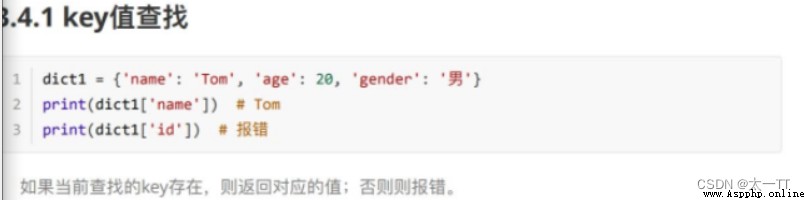 (2)get()
(2)get()
Dictionary sequence .get(key, The default value is )
If the current search key non-existent
Then go back to ⼆ Parameters ( The default value is ),
If you omit paragraph ⼆ Parameters , Then return to None
 (3)keys
(3)keys
(4)values: (5)items:
(5)items:
Dictionary loop traversal :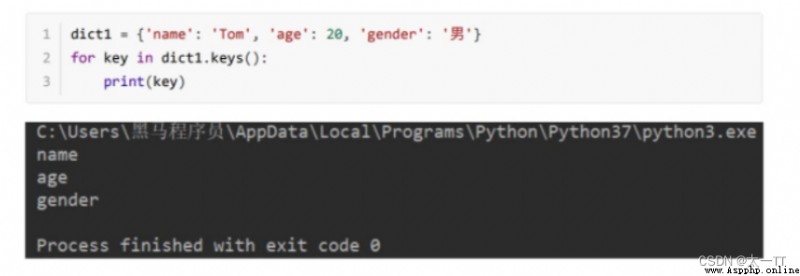
for key in dict.keys():
for value in dict.values():
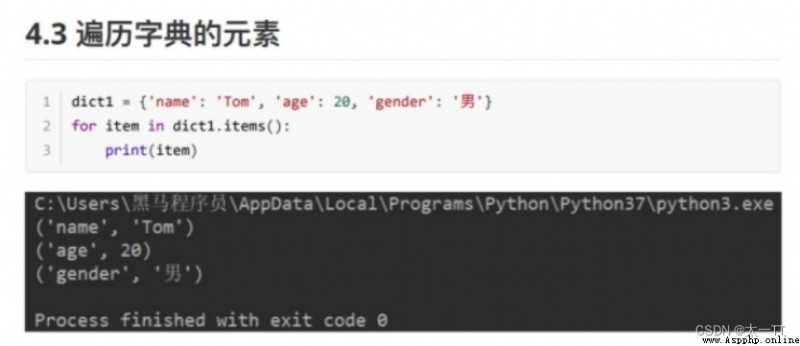
for item in dict.items():# Traversing elements
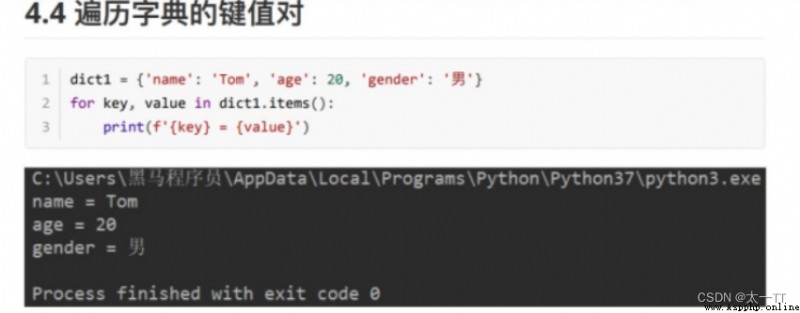
for key,value in dict.items(): # Traversal key value pairs