數據清洗過程中經常會遇到異常值和缺失值等問題,有時候,會把異常值看作缺失值來處理。一般的缺失值處理方法包括:刪除、統計值充填(均值、中位數等)、回歸方程預測充填等。
使用直接刪除這種方法簡單易行,但缺點是,在記錄數據較少的情況下,會造成樣本量的進一步減少,可能會改變響應變量的原有分布,造成分析結果不准確。因此,將異常值視為缺失值來處理的益處在於可以利用現有變量的信息進行建模挖掘,對異常值(缺失值)進行填補。(本文旨在探索如何使用回歸方程進行預測估算,對異常值、缺失值進行充填的操作方法)
回歸方程充填法,是選擇若干能預測缺失值的自變量,通過建立回歸方程估算缺失值。該方法能盡可能地利用原數據集中的信息,但也存在一些不足之處:1. 雖然這是一個無偏估計,但會忽視隨機誤差,低估標准差和其他未知性質的測量值。2.使用前,必須假設存在缺失值所在的變量與其他變量是存在線性關系的,但現實它們不一定存在這樣的線性關系,這可以借助統計工具來辨析,但往往更需要建模人員的實踐經驗和業務知識來進行分析和判斷。
根據需要充填缺失值的變量,把原始數據集拆分為2個子集(1. 不含有缺失值:dataset_train; 2. 只含有缺失值dataset_pred)
經驗分析判定與充填缺失值的變量相關的屬性列有哪些,應用統計分析工具,在dataset_train數據集上查看驗證所選擇的屬性列之間的相關性。
使用dataset_train數據集建立線性回歸模型,並應用建好的模型對dataset_pred數據集中的缺失變量進行預測估計
將兩個子集合並還原為一個數據集,為後續建模准備好數據。
數據集說明:
數據集截取自一個計算強度(響應值為”strength“)的部分原始數據作為示例。
本例中"force"是一個重要的特征,但是含有缺失值,嘗試使用回歸方程預測充填缺失值,為建立預測"Strength"模型做數據准備。
載入數據並確定需要充填缺失值的特征:
拆分數據集: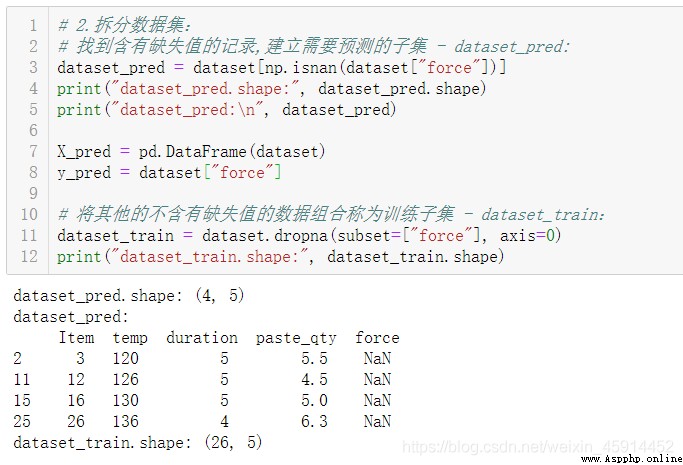
發現"item"為3, 12, 16, 26的"force"特征存在缺失值。考慮到數據量不是太多,檢查變量”force“是否符合正態分布。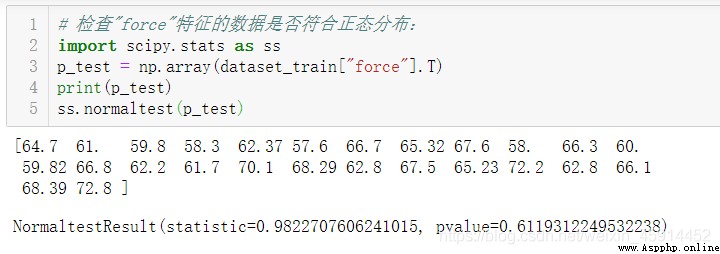
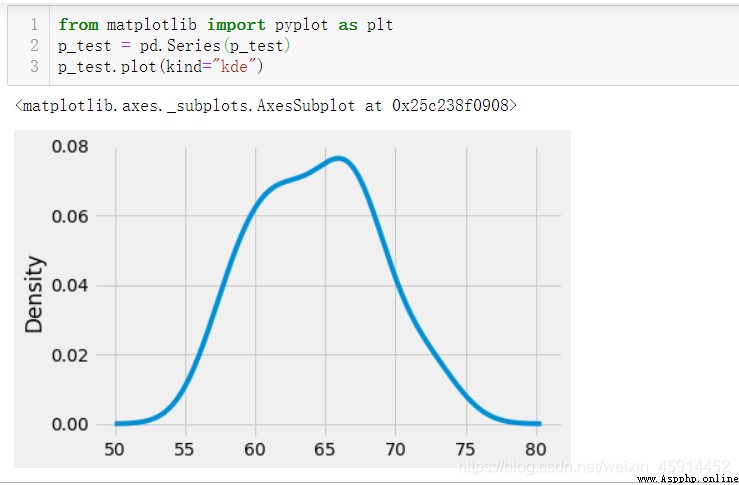
上述分析的結果得出:p值為0.612,大於0.05,特征數據符合正態分布。
辨析並檢驗相關變量的相關性:
根據實踐經驗可了解到,焊接拉拔力會受到溫度(temp)、時間(duration)和焊膏量(paste_qty)等因素的影響,因此,我們將選擇利用上述的這3個因子建立回歸方程, 在此之前先檢驗各個因子與預測變量(force)之間的相關性。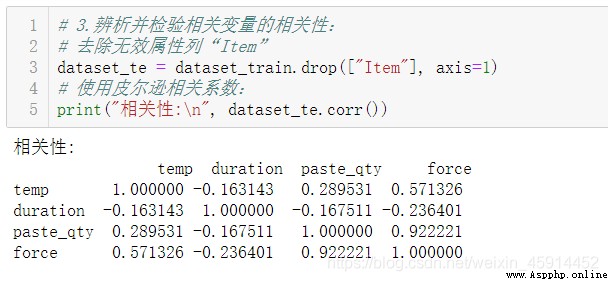
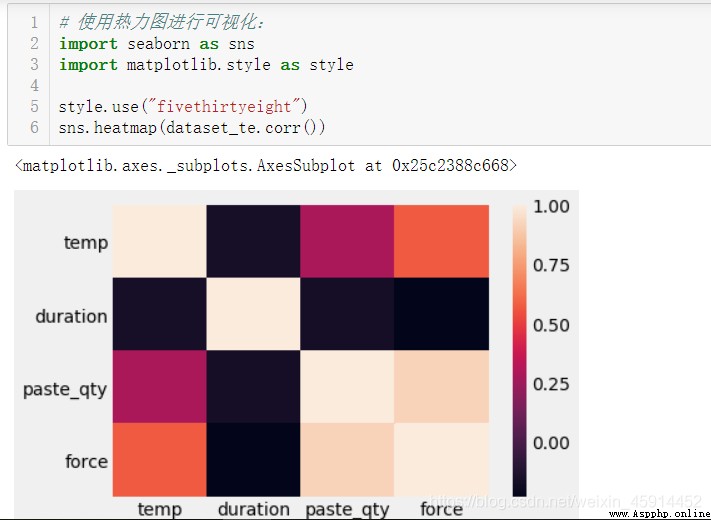
由上述結果表明:我們選擇的因子與“force”屬性之間存在一定的相關性。
建模並預測: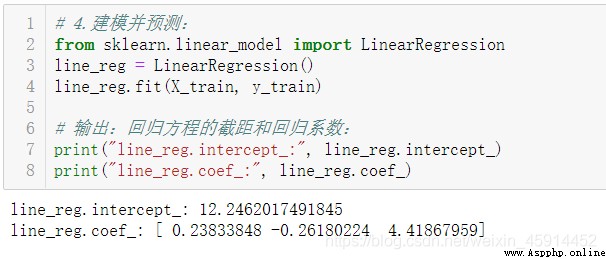
由此得到的回歸方程為:
force = 12.246 + 0.238 * temp - 0.262 * time + 4.419 * paste_qty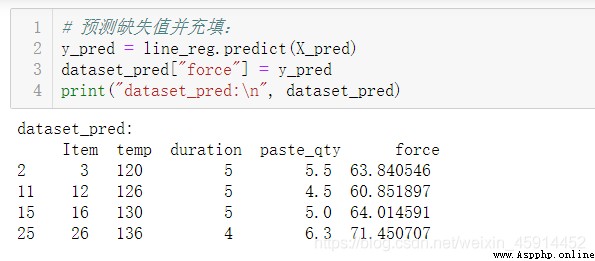
通過模型預測,估算出在"force"中的4個缺失值。
合並還原數據集:
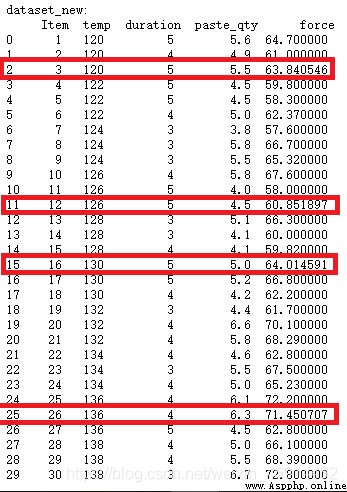
檢查"item"為3, 12,16,26的"force"特征,結果顯示原有的缺失值已經被使用回歸方程的預測值填充好了!