@[TOC]數據清洗方法及步驟
真實世界中的數據狀態可謂是千奇百怪,數據集會因為各種原因發生缺失、錯誤和重復等問題。數據清洗(Data Cleansing), 就是根據實際情況,通過一系列的數據“清理”步驟,糾正錯誤信息,辨析異常數據,刪除重復值,以合適建模的格式輸出清洗好的數據。
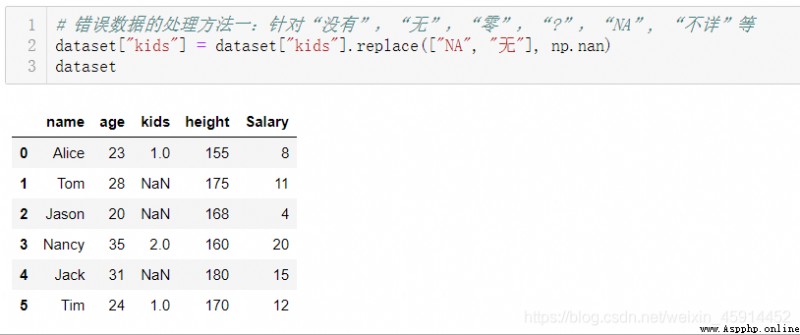
缺失值產生的原因有很多種,如數據收集時沒有記錄某些觀察值而導致的;也有一些缺失值是因為記錄數據時沒有做好記錄准則導致的,例如“子女數量”,會遇到這樣的記錄描述:“沒有”,“無”,“個”,“零”,“0個”,“NA”,“?”,等等,一些描述代表“0”值,也有的是因為漏填或錯誤填寫而造成的。在進入數據清洗階段前,最好是通過浏覽或一些可視化的工具對數據集進行一定的全局認知,以便於在數據清洗過程中做出正確的判段和決策。
檢查數據集中是否存在缺失值的方法:
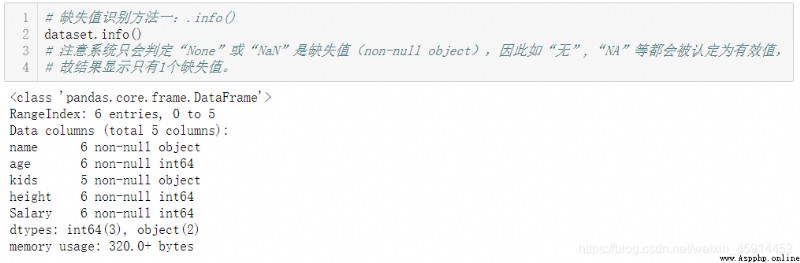
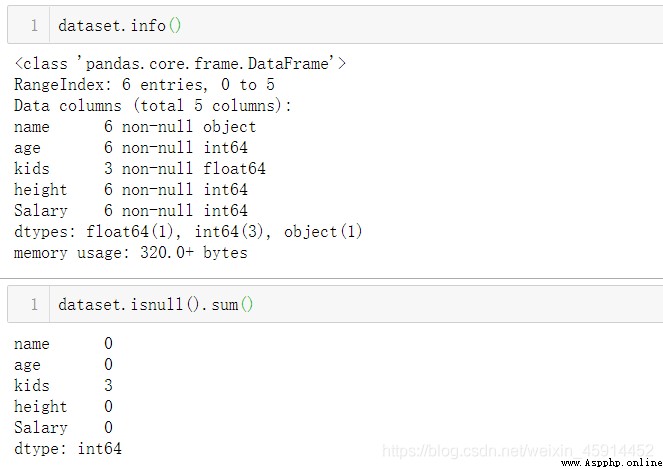
.info() : 查看數據有多少行,是否有缺失值,以及每列的數據類型等
.isnull():按列統計缺失值的數量
注意:因為系統只判定”None“,”NaN“是缺失值,對於"NA", “無”, "?"等描述計算機會認為它們是有效的數據,而導致錯誤的結果,所以在使用上述方法辨析缺失值之前,最好使用.head()方法或.sample()方法先對原始數據集進行浏覽。
代碼示例: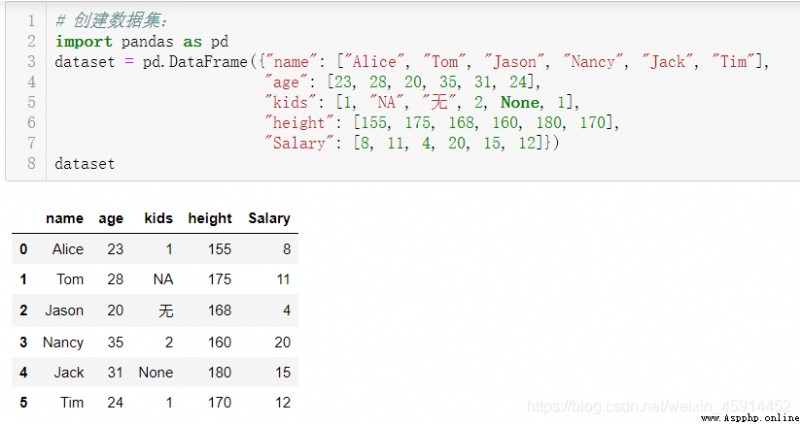
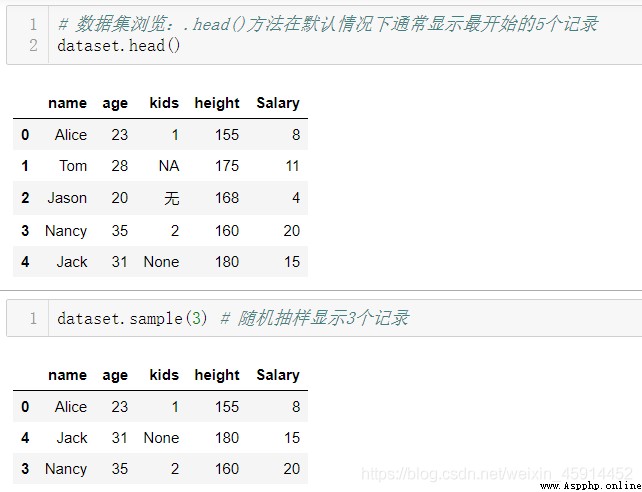

刪除含有缺失值的記錄:DataFrame的方法:dropna()、drop() 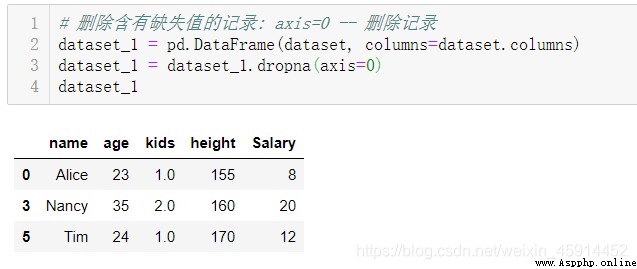
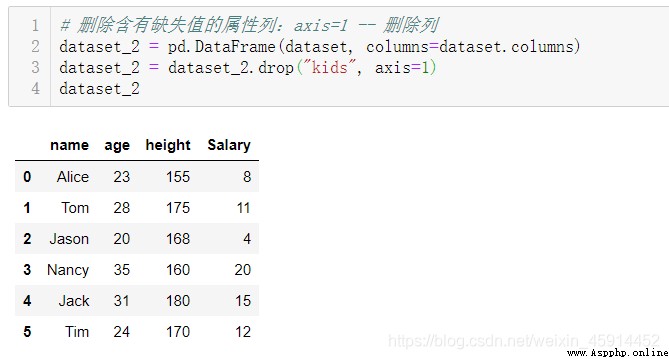
可以根據實際情況判定是否刪除含有缺失值的樣本記錄或屬性例,如考慮缺失值記錄在整個有效數據中的占比等。個人建模經驗,某些情況下直接刪除含有缺失值的記錄,並不會降低模型的性能,甚至模型的性能會比使用填充值的模型更好。如果缺失值發生在響應值(response)上,一般而言建議刪除這些記錄,因為填充值的精確性會對模型精確性產生較大的影響。
對缺失值進行“0”值填充:.fillna(“0”)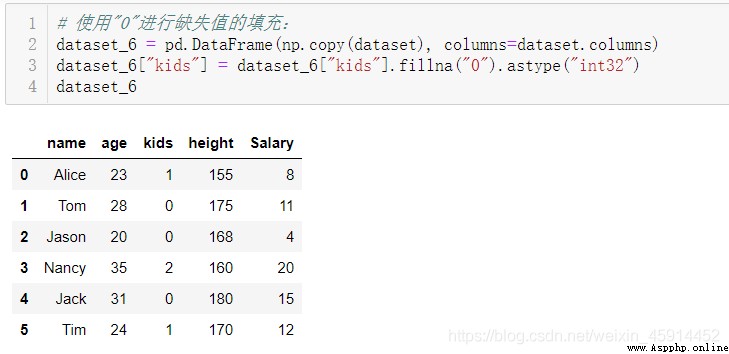
對缺失值進行統計數據填充(包括:均值、中位數或眾數等):如:fillna(median),fillna(mean);也可使用scikit-learn中的imputer()方法來對整個數據集快速進行缺失值填充: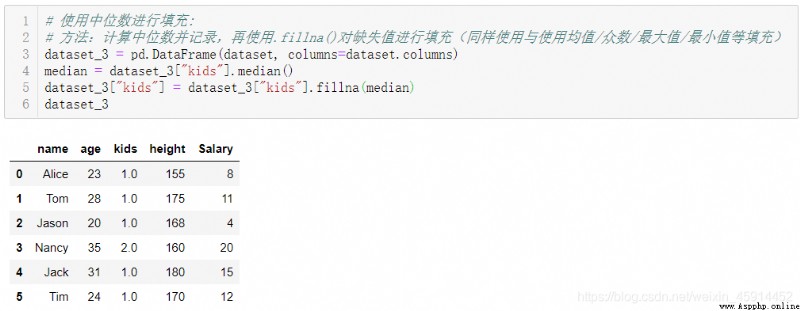
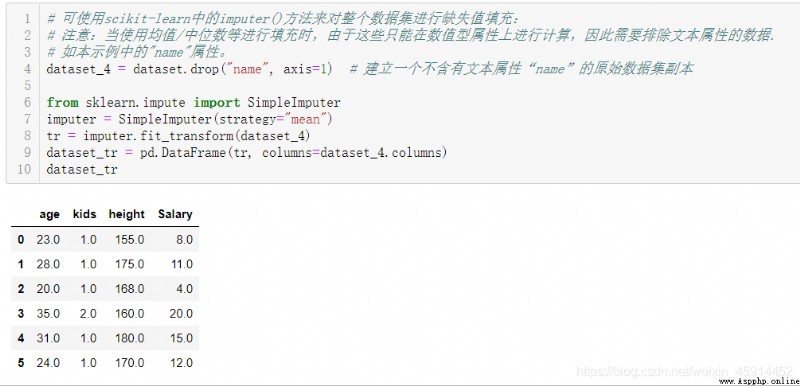
Imputer類也可以使用在機器學習的流水線上,在此不多敘述。
調用回歸方法對缺失值進行預測並填充: 如線性回歸,樹回歸等
在進行數據清洗的時候,除了明顯的錯誤數據,還有一些異常數據。異常值(又稱為離群值)是指記錄樣本中的個別數據,其數值明顯偏離該屬性樣本的其余觀察值。一般的異常值會明顯大於或小於其他值,較容易辨認,也有不明顯的,則可以通過統計檢驗方法將其識別並剔除。
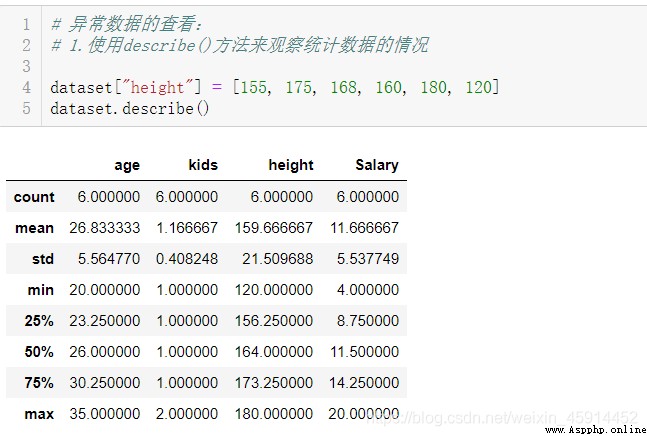
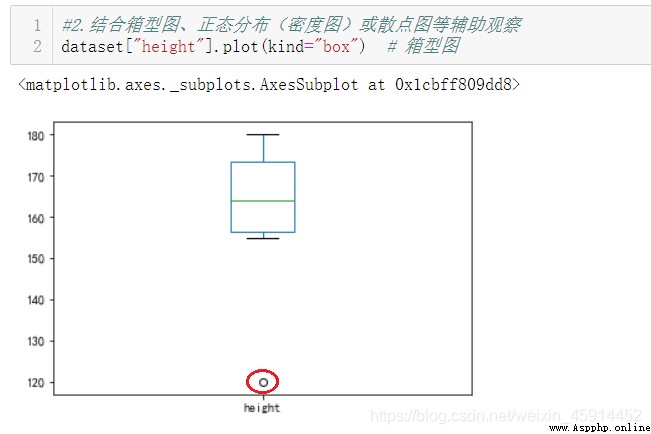
面對異常值,最好能具體了解產生這些異常值的背後原因,這可能會發掘到一個能更好地穩定或控制流程性能的機會點。處理異常值一定要基於實際情況來考慮,在做好標記和記錄後,可選擇下面一些常用的處理方法:
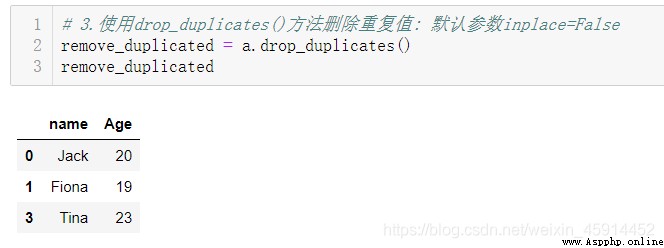
示例:查看整個數據集重復值的情況,統計重復值的數量及辨析哪些數據是重復值,最後刪除重復值。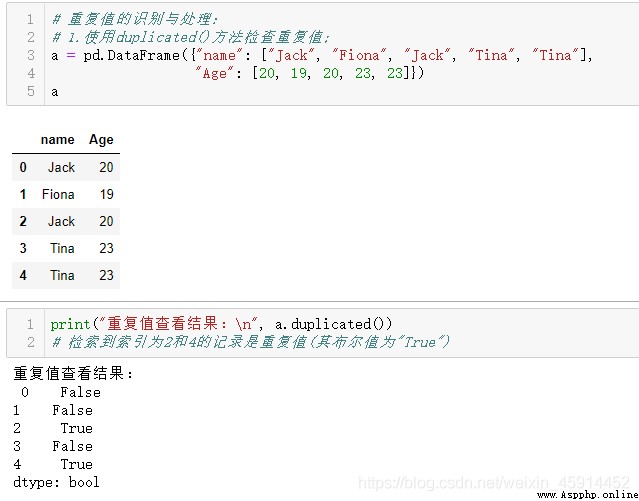

 [computer test questions (implementation language: python3)] solve cube root
[computer test questions (implementation language: python3)] solve cube root
Title Description Calculate t
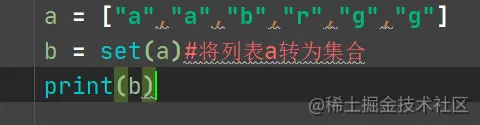 Enumerate usage and zip usage in Python: parallel traversal, collection usage and characteristics
Enumerate usage and zip usage in Python: parallel traversal, collection usage and characteristics
p{margin:10px 0}.markdown-body