@[TOC] Data cleaning methods and steps
The state of data in the real world is very strange , Data sets are missing for various reasons 、 Errors and repetition . Data cleaning (Data Cleansing), According to the actual situation , Through a series of data “ clear ” step , Correct the error message , Discrimination of abnormal data , Delete duplicate values , Output the cleaned data in the appropriate modeling format .
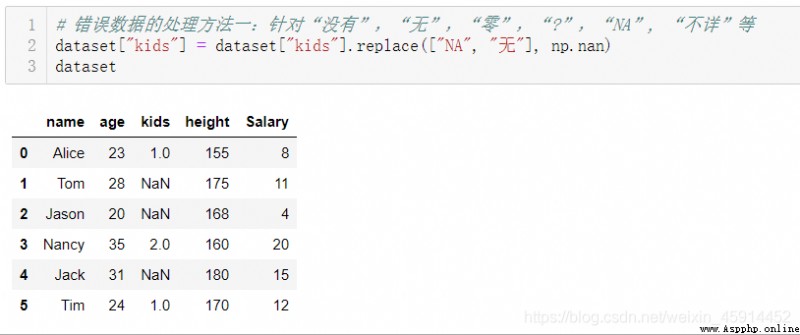
There are many reasons for missing values , For example, some observations are not recorded during data collection ; There are also some missing values because there are no recording criteria when recording data , for example “ The number of children ”, You will encounter such a record description :“ No, ”,“ nothing ”,“ individual ”,“ zero ”,“0 individual ”,“NA”,“?”, wait , Some descriptions represent “0” value , Some are caused by missing or wrong filling . Before entering the data cleaning phase , It is better to have a certain global understanding of the data set through browsing or some visual tools , So as to make correct judgment and decision in the process of data cleaning .
Method to check whether there are missing values in the data set :
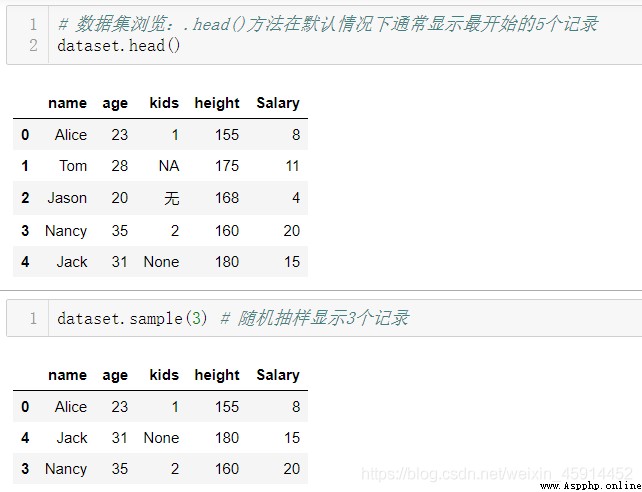
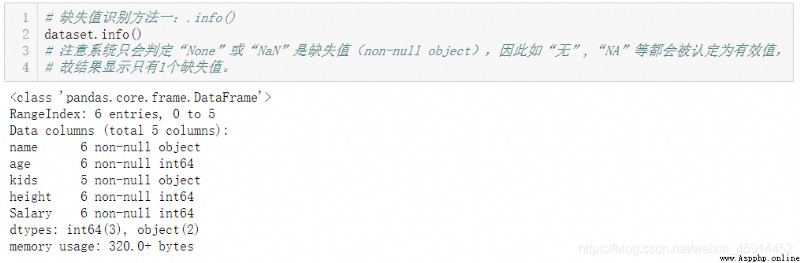
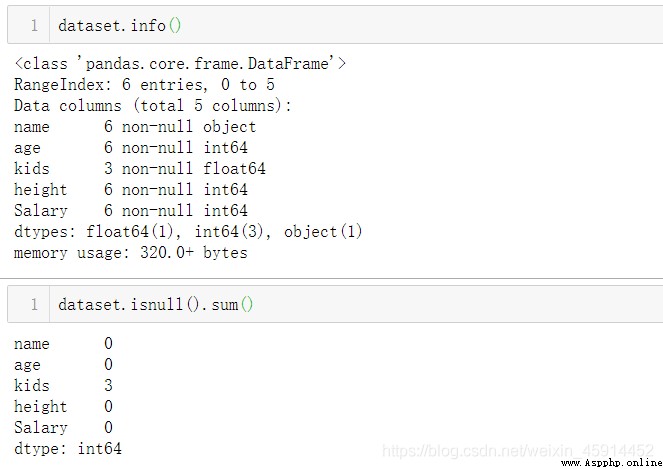
.info() : See how many lines of data , Whether there are missing values , And the data type of each column
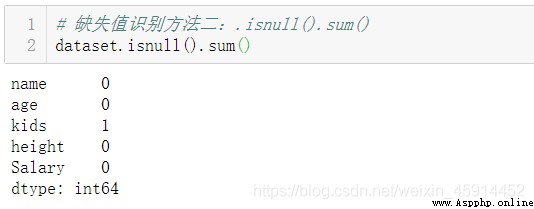
.isnull(): Count the number of missing values by column
Be careful : Because the system only determines ”None“,”NaN“ It's missing values , about "NA", “ nothing ”, "?" The computer will think that they are valid data , And the wrong result , So before using the above method to distinguish the missing values , Best use .head() Method or .sample() Method browse the original data set first .
Code example :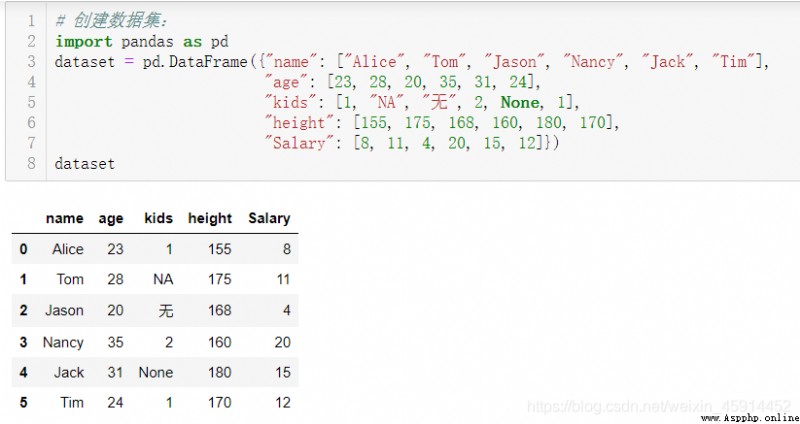
Delete records with missing values :DataFrame Methods :dropna()、drop() 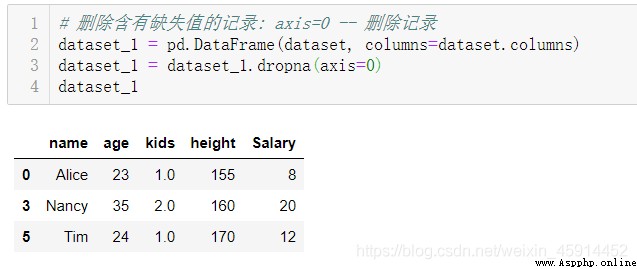
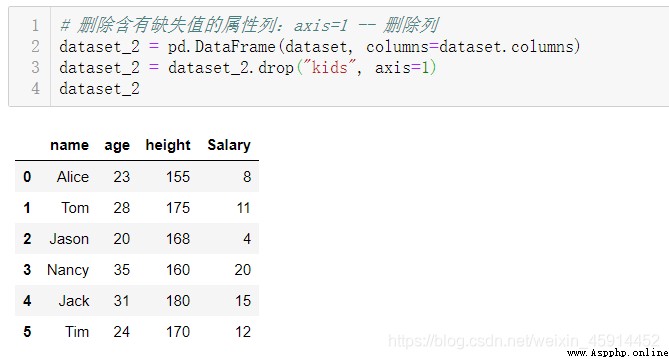
You can determine whether to delete sample records or attribute examples with missing values according to the actual situation , For example, consider the proportion of missing value records in the whole valid data . Personal modeling experience , In some cases, records with missing values are deleted directly , Does not degrade the performance of the model , Even the performance of the model will be better than that of the model using filled values . If the missing value occurs in the response value (response) On , In general, it is recommended to delete these records , Because the accuracy of the filling value will have a great impact on the accuracy of the model .
The missing values are “0” Value padding :.fillna(“0”)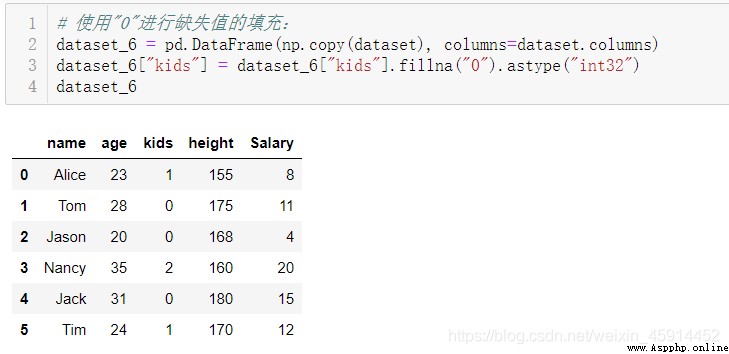
Fill in the missing values with statistical data ( Include : mean value 、 Median or mode, etc ): Such as :fillna(median),fillna(mean); You can also use scikit-learn Medium imputer() Method to quickly populate the entire data set with missing values :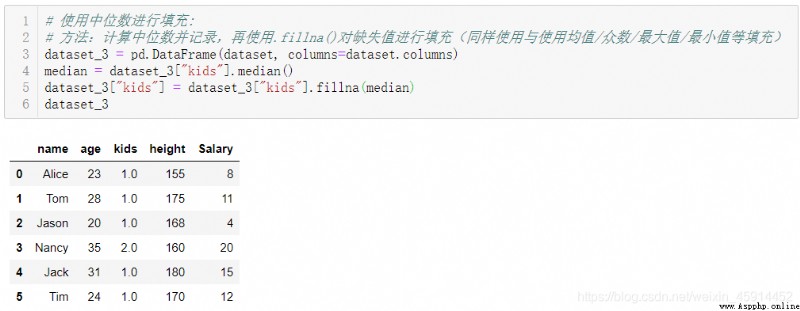
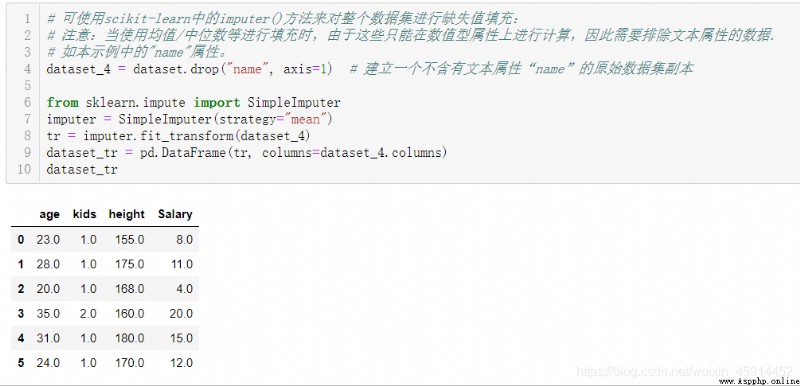
Imputer Class can also be used in the pipeline of machine learning , There is not much to be said here .
Call the regression method to predict the missing values and fill in : Such as linear regression , Tree regression, etc
During data cleaning , Except for the obvious wrong data , There are also some abnormal data . outliers ( Also known as outliers ) Refers to recording individual data in the sample , Its value obviously deviates from the other observed values of the attribute sample . General outliers are significantly larger or smaller than other values , Easier to identify , There are... Not obvious , It can be identified and eliminated by statistical test .
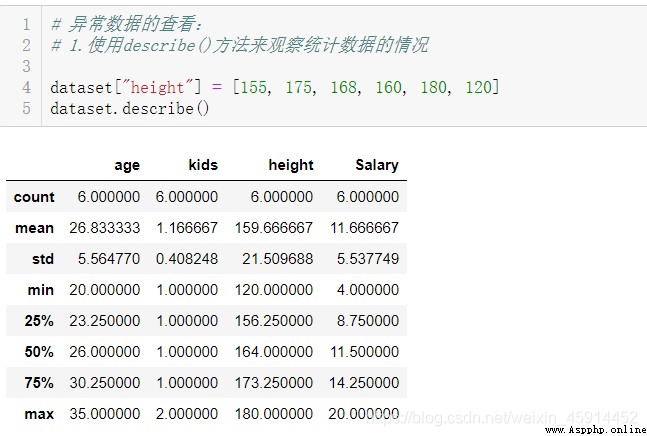
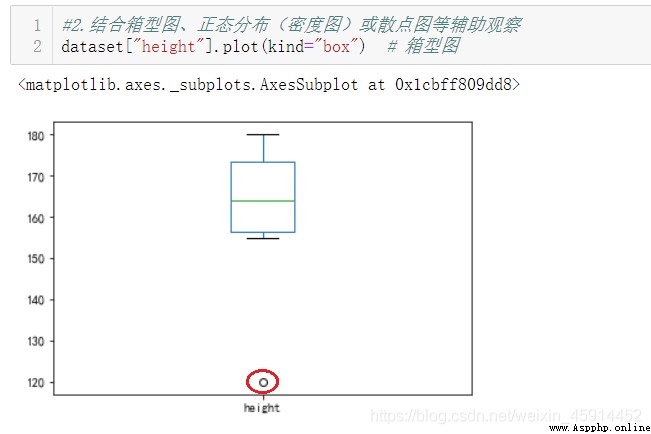
Facing outliers , It is better to understand the reasons behind these outliers in detail , This may lead to an opportunity to better stabilize or control process performance . Handling outliers must be based on the actual situation , After marking and recording , You can select some common processing methods below :
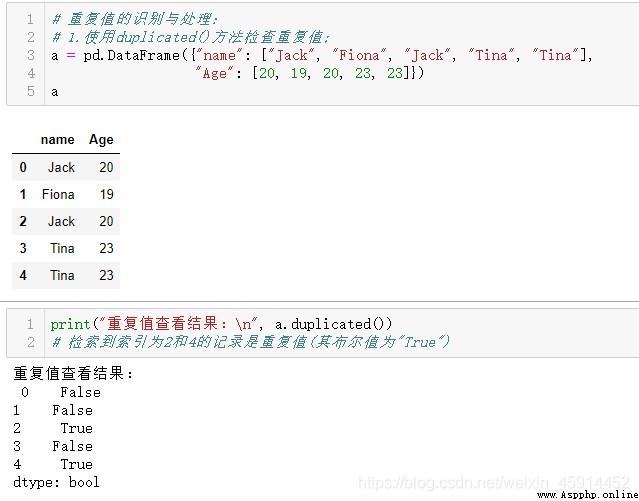
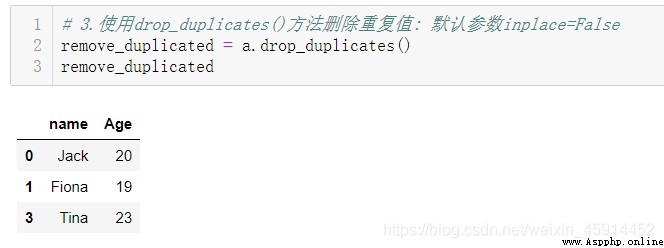
Example : View the duplicate values of the entire dataset , Count the number of duplicate values and distinguish which data are duplicate values , Finally, remove duplicate values .