prices = {'apple':4.99,
'banana':1.99,
'orange':3.99,
'grapes':0.99}
ser = pd.Series(prices)
ser = pd.Series(2,index = range(0,5))
ser = pd.Series(range(1,15,3),index=[x for x in 'abcde'])
import random
ser = pd.Series(random.sample(range(100),6))
import pandas as pd
a =[1,3,5,7]
a = pd.Series(a,name ='JOE')
a = pd.DataFrame(a)
import pandas as pd
import random
x = random.sample(range(100),10)
print(x)
y = pd.Series(x)
print(y)
print("==============================")
print(y[y>40])
x=random.sample(range(100),10)
print(x)
y = pd.Series(x)
print(y[[2,0,1,2]])
def joe(x):
return x +10
x = random.sample(range(100),10)
print('Data => ',x,'\n')
y = pd.Series(x)
print('Applying pow => \n' ,pow(y,2),'\n')
print('Applying joe => \n',joe(y))
x = pd.Series(range(1,8),index=[x for x in 'abcdefg'])
print(x,'\n')
print('Is "j" in x? ','j' in x)
print('Is "d" in x? ', 'd' in x)
df.iloc[:,[0,3,5,1]].set_index('XXX')不行,必須這樣: df = df.set_index('XXX')才能生效。 .set_index('XXX', inplace = True])data.Area.head()data[['column_name_1', 'column_name_2']]DataFrame中分組最大值的索引idxmax()可以獲取原df中最大值的索引 contb.groupby('cand_nm',as_index=False)[['contb_receipt_amt']].max().index()獲取的是生成的新df的索引(即從0開始) contb.groupby('cand_nm')[['contb_receipt_amt']].max().index()獲取df是以 cand_nm為索引 綜上,想要獲取每個候選人獲取單筆獻金最大值的索引,只能用idxmax()方法。
但是這種方法有個缺陷,即只能找出其中一個最大捐贈者。如果一個候選人有多個相同額度的最大捐贈者,則這種方法行不通。
下面的方法,用groupby找出每個候選人最大的捐贈額,然後用候選人和捐贈額作為條件,找出相對應的行。
df_max_donation = pd.DataFrame()
s = contb.groupby('cand_nm')['contb_receipt_amt'].max()
for i in range(s.size):
ex = 'cand_nm == "%s" & contb_receipt_amt == %f' % (s.index[i], s.values[i])
# print(ex)
df_max_donation = pd.concat([df_max_donation,contb.query(ex)],axis=0,)
display(df_max_donation)
應該還有一種方法,將s(Series)轉成dataframe,然後和contb進行join操作。 參見[[美國大選獻金分析#^805156]]
dt=data.drop("Area",axis=1,inplace=True)
df.drop([0, 1])
df.drop(index=[0, 1])
注意第一個參數為index,所以在以條件刪除行的時候要確認獲得條件篩選之後的index值作為參數。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(12).reshape(3,4), columns=['A', 'B', 'C', 'D'])
# df.drop(df[df['A']==4].index,inplace=True)
df.drop(df[df['A']==4].index,inplace=True)
data.loc[data['id'] > 800, "first_name"] = "John"
這段代碼可以增加first_name列,如果first_name列已經存在,則會修改滿足條件的行的該列值。 增加列也可以用np.where或np.select。
另外,np.select也可以用來修改已經存在的某列的指定行的值,這種情況下,np.select修改的是整列的值,所以如果只想修改特定條件行的值,要注意修改default的值。
con = [abb_pop['state/region'] == 'PR', abb_pop['state/region'] == 'USA']
values = ['Puerto Rico', 'United States of America']
abb_pop['state'] = np.select(con, values, default=abb_pop['state'])
有關np.where和np.select的解釋可以參考[[#np where 和 np select 再解釋]]
對於數值列,以億為單位。如果數值較小(小於0.1億),則轉化成以萬為單位,並加上萬“萬元”,否則,加上“億元”。
如何使用np.select()直接操作?
暫時只想到一個非直達的方法:
x = np.array([0.0001,0.03,0.1,0.9,1,4.3])
df = pd.DataFrame(x, columns = ['r_amt'])
condlist = [df['r_amt']<=0.1, df['r_amt']>0.1]
choicelist = [df['r_amt']*10000, df['r_amt']]
choicelist2 = ['萬元', '億元']
# 下面的寫法出錯。
# choicelist = [str(x) + '萬元', x**2]
df['amt'] = np.select(condlist, choicelist, None)
df['unit'] = np.select(condlist, choicelist2, None)
df['amt'] = df['amt'].astype('str')
df['all'] = df['amt'] + df['unit']
df
知識點:
apply(Series, 1)。 stack將拆散成的多列打散,變成多行。 DataFrame 和 Series ,可以用 join 。 具體可參見 IMDB - Analysis by Genress = dt['genres'].str.split('|').apply(Series, 1).stack()
s.index = s.index.droplevel(-1)
s.name = 'genres'
del dt['genres']
df = dt.join(s)
兩種方式重命名列:
data.rename(columns={"Area":"place_name"},inplace = False)data.rename(columns=str.lower)df.set_index('country')
設置索引後可以方便地使用loc進行定位,也可以用join連接。
df.columns=['population','total GDP']
df['population'] =df['population']*1000
df['xxx'].value_counts()
from pandas.api.types import CategoricalDtype
cat_size_order = CategoricalDtype(
['浦東新區', '闵行區', '徐匯區', '松江區', '黃浦區', '普陀區', '嘉定區', '靜安區', '奉賢區', '楊浦區', '青浦區', '崇明區', '虹口區', '金山區', '寶山區', '長寧區', '全市'],
ordered=True
)
df['行政區'] = df['行政區'].astype(cat_size_order)
TO BE STUDIED...
參考鏈接:
https://www.cxyzjd.com/article/S_o_l_o_n/80917211
https://www.jianshu.com/p/8a859643f37e
https://blog.csdn.net/S_o_l_o_n/article/details/80917211
bins = [0,1,10,100,1000,10000,100000,1000000,10000000]
labels = pd.cut(contb_vs['contb_receipt_amt'],bins)
contb_vs['label'] = labels
contb_vs
axis的理解我的理解:axis = 0 可以理解為結果影響行,axis = 1 可以理解為結果影響列。也就是說,最終作用的結果是行減少了(增加了)還是列減少了(增加了)。
比如:
data.drop("Area",axis=1),列減少;
df.mean(axis=0),行減少;
df.apply(lambda x:x.max()-x.min()),默認axis = 0,行增加(或減少);
另外可以參考Ambiguity in Pandas Dataframe / Numpy Array "axis" definition
np.where和np.select再解釋df['hasimage'] = np.where(df['photos']!= '[]', True, False)
store_patterns = [
(df['Store Name'].str.contains('Hy-Vee', case=False, regex=False), 'Hy-Vee'),
(df['Store Name'].str.contains('Central City',
case=False, regex=False), 'Central City'),
(df['Store Name'].str.contains("Smokin' Joe's",
case=False, regex=False), "Smokin' Joe's"),
(df['Store Name'].str.contains('Walmart|Wal-Mart',
case=False), 'Wal-Mart')
]
store_criteria, store_values = zip(*store_patterns)
df['Store_Group_1'] = np.select(store_criteria, store_values, 'other')
TO BE STUDIED...
df.resample('M').first() 相關資源:pandas.DataFrame.resample、時間重采樣的間隔參數
可以在求諸如“5日平均”數據時使用。 相關資源:pandas.Series.rolling
doc: pd.to_datetime,注意format等參數。
參考[[消費行為分析#獲取月份]] astype('datetime64[M]')可以將datetime格式的數據轉成月份,優點是datetime64格式,但是在顯示的時候會顯示成“1970-01-01”這樣的格式。
to_period('M')可以將datetime格式的數據轉成月份,而且可以顯示成“1970-01”這樣的格式。缺點是不是datetime64格式。
如果只想獲取單獨的月或年,可以這樣:
df['year'] = df.order_dt.dt.year
df['month'] = df.order_dt.dt.month
格式為int64。
另注意,這裡只是要獲取月份,暫時並不是要以月份重取樣然後求和、技術等操作。如果想做數據重取樣,需要對order_dt設置索引。因為resample只能對DatetimeIndex, TimedeltaIndex or PeriodIndex格式的數據進行。
這裡有個resample的常見問題**TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of 'RangeIndex'**,
Stack Overflow上有個答案:
Convert column date to datetimes and add parameter on to resample:
df['date'] = pd.to_datetime(df['date'])
weekly_summary = df.story_point.resample('W', on='date').sum()If need new column:
weekly_summary['weekly'] = df.story_point.resample('W', on='date').transform('sum')Or create DatetimeIndex:
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
weekly_summary = df.story_point.resample('W').sum()If need new column:
weekly_summary['weekly'] = df.story_point.resample('W').transform('sum')
map、apply、applymap、transform用法map: 針對 Seriesapply: - 針對 DataFramed的軸向做運算,也就是說對行或列做運算,不能對單個元素做運算。運算結果返回去重長度的 Series。 - 針對 Series的元素進行運算。 applymap: 針對 DataFrame的元素做運算。 transform: 運算結果返回原長度的 Series。 map操作Series的方法 計算每一種水果的平均價格 dic = {
'item':['apple','banana','orange','banana','orange','apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]
}
df = DataFrame(dic)
mean_price = df.groupby('item')['price'].mean().to_dict()
df['mean_price'] = df['item'].map(mean_price)
apply操作DataFramed的方法, 返回去重長度的SeriesDataFramed中的行或列數據進行某種形式的運算操作。 def func(s):
s = s.sum()
print(s)
df.apply(func)
transform操作Seriestransformdef my_mean(s):
sum = 0
for i in s:
sum += i
return sum / s.size
df.groupby('item')['price'].apply(my_mean)
## 結果:
# item
# apple 3.00
# banana 2.75
# orange 3.50
# Name: price, dtype: float64
df.groupby('item')['price'].transform(my_mean)
# 結果:
# 0 3.00
# 1 2.75
# 2 3.50
# 3 2.75
# 4 3.50
# 5 3.00
# Name: price, dtype: float64
是否可以計算出每種水果的平均價格,即: 下面的方法是生成一個新的dataframe,是否有方法可以直接在原dataframe上直接出結果?
df['gross'] = df['price'] * df['weight']
df2 = df.groupby('item').agg({'gross':sum,'weight':sum})
df2['total_mean_price'] = round(df2['gross']/df2['weight'],2)
df2
修改索引、列名。
df4 = DataFrame({'color':['white','gray','purple','blue','green'], 'value':np.random.randint(10,size=5)})
new_index = {0:'first',1:'two',2:'three',3:'four',4:'five'}
new_col = {'color':'cc','value':'vv'}
df4.rename(index = new_index, columns = new_col)
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
# First, add the platform and device to the user usage - use a left join this time.
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id',
how='left')
# At this point, the platform and device columns are included
# in the result along with all columns from user_usage
# Now, based on the "device" column in result, match the "Model" column in devices.
devices.rename(columns={"Retail Branding": "manufacturer"}, inplace=True)
result = pd.merge(result,
devices[['manufacturer', 'Model']],
left_on='device',
right_on='Model',
how='left')
merge、join也可以用來合並,比較簡單。
print(data['item'].count())
print(data['duration'].max())
print(data['duration'][data['item']=='call'].sum())
print(data['month'].value_counts())
print(data['network'].nunique())
另有unique、nunique等函數。
np.ptp(arr,axis=0)
如果不用ptp,下面的寫法就比較復雜了:
df_arr = pd.DataFrame(arr)
df_arr.loc[:,[0,1,2,3,4]].max() -df_arr.loc[:,[0,1,2,3,4]].min()
data.groupby('month')['duration'].sum()
data[data['item']=='call'].groupby('network')['duration'].sum().sort_values(ascending=False)
data.groupby(['month','item'])['date'].count()
data.groupby('month',as_index=False).agg({'duration':['sum','count', 'max','min','mean']})
data.groupby('month')['duration'].sum() # produces Pandas Series
data.groupby('month')[['duration']].sum() # Produces Pandas DataFrame

聚合字典語法非常靈活,可以在操作之前定義。還可以使用 lambda 函數內聯定義函數,以提取內置選項未提供的統計信息。
from datetime import timedelta
aggregations = {
'duration':'sum',
'date': [lambda x: max(x).date(), lambda x: (max(x) - timedelta(days=1)).date()]
}
grp = data.groupby('month',as_index=False).agg(aggregations)
grp.columns = grp.columns.droplevel(level=0)
grp.rename(columns={'sum':'duration_sum', r'<lambda_0>':'date', r'<lambda_1>':'date-1'})
參考文章
知識點 篩選行不僅可以用loc,還可以用query:
df.query('Product==["CPU","Software"]')
設置數據類型為類別的好處:比如查詢單元格中是否有某個字符串,如果是str(object)類型,則需要對每一個單元格進行運算;如果是category類型,則不需要每個單元格運算,只需要對僅有的幾個類型進行運算即可。對於較大數據,會明顯提升速度。
df["Status"] = df["Status"].astype("category")
# 設置排序的順序.如果不設置,可能按字母順序。
df['Status'].cat.set_categories(["won","pending","presented","declined"],inplace=True)
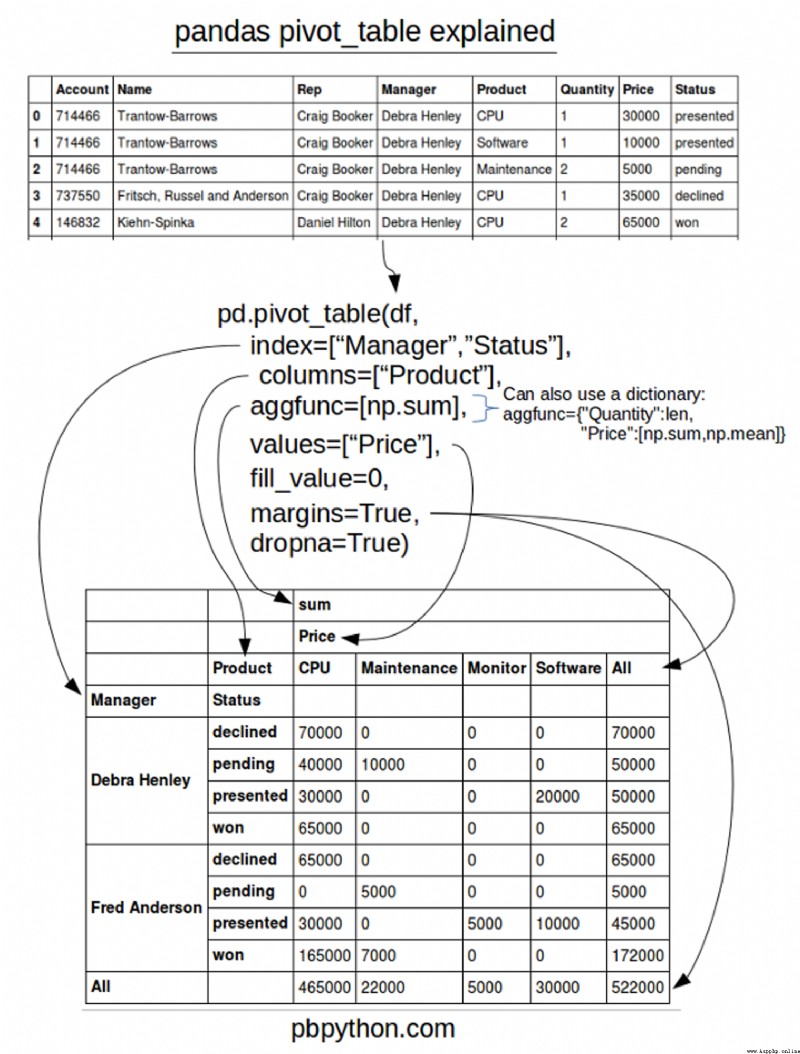
table = pd.pivot_table(df,index=["Manager","Status"],columns=["Product"],values=["Quantity","Price"],
aggfunc={"Quantity":len,"Price":[np.sum,np.mean]},fill_value=0)
pd.pivot_table(df,index=["Name","Account"])
pivot_table 的一個令人困惑的問題是使用列和值。請記住,
pd.pivot_table(df,index=['Manager','Rep'],values=['Price'],aggfunc=['sum'],fill_value=0)
pd.pivot_table(df,index=['Manager','Rep'],values=['Price'],columns=['Product'],aggfunc=[np.sum],fill_value=0)
pd.pivot_table(df,index=['Manager','Rep','Product'],values=['Price','Quantity'],aggfunc=[np.sum],fill_value=0)
pd.pivot_table(df,index=['Manager','Rep','Product'],values=['Price','Quantity'],aggfunc=[np.sum,np.mean],fill_value=0,margins=True)
Status就根據之前定義的順序排列
pd.pivot_table(df,index=['Manager','Status'],values=['Price'],aggfunc=[np.sum],fill_value=0,margins=True)
## 以下兩句代碼效果一樣
pd.pivot_table(contb,index=['contbr_occupation'],columns=['party'],aggfunc='sum',values=['contb_receipt_amt'])
contb.groupby(['contbr_occupation','party'])['contb_receipt_amt'].sum().unstack()
讀取文件比較簡單,但是讀取csv文件的有個小技巧:有些csv文件的分隔符為一個或多個空格、一個或多個制表符,此時sep參數要設置為sep='\s+'。
columns = ['user_id','order_dt', 'order_products', 'order_amount']
df = pd.read_csv('CDNOW_master.txt', names=columns, sep='\s+')
with pd.ExcelWriter(xlsname) as writer:
df1.to_excel(writer, sheet_name='XXX',index=False)
df2.to_excel(writer, sheet_name='YYY',index=False)
import openpyxl as op
ontent_1 = '上海' + str(int(month)) + '月' + str(int(day)) + '日日報未直報機構匯總數(' + str(not_direct_report) + '家未直報,另有8280北德意志銀行日報無數據)'
file = 'filename'
# 加載工作簿
wb = op.load_workbook(file)
# 選定工作表
sh=wb["AAA"]
# 對單個單元格填充內容,cell的三個參數分別是行號(1開始)、列號(1開始)、內容
sh.cell(1,1,content_1)
sh=wb["BBB"]
## 表頭
headlines = {1:'aa', 2:'bb', 3:'cc', 4:'dd', 5:str(int(month)) + '月' + str(int(day)) + '日余額', 6:'ee'}
for col,headline in headlines.items():
sh.cell(1,col,headline)
sh.row_dimensions[1].height = 43.2
## 數據內容
for col in mx_not_direct_repo.columns:
a = mx_not_direct_repo[col].tolist()
for i in range(len(a)):
sh.cell(i+2,j,a[i])
j += 1
df.isna()
any 和 all 方法 df.drop(df.loc[df.isna().any(axis=1)].index,inplace=True,axis=0)
df.reset_index()
any 方法的 axis 參數為 1 ,表名對每一行的多列來說,最終形成一個字段 True 或 False ,效果就是列減少。參見 [[#axis 的理解]] 。
dropnadf.dropna(inplace=True)
ffill 向前填充 bfill 向後填充 df.fillna(method='ffill',axis=0)
df.loc[1] = [1,1,1,1,1,1]
df.loc[3] = [1,1,1,1,1,1]
df.loc[5] = [1,1,1,1,1,1]
df.loc[7] = [1,1,1,1,1,1]
df.drop_duplicates(keep='first',inplace=True)
df = pd.DataFrame(np.random.random(size=(1000,3)),columns=['A','B','C'])
## 剔除大於2倍標准差的
df.drop(df.loc[~(df['C'] > (2 *df['C'].std()))].index,inplace=True,axis=0)
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
df = DataFrame(np.random.randint(0,100,size=(8,7)))
## df.replace(to_replace=0, value='zero')
df.replace(to_replace={0:'zero',4:'four'})
## 替換第4列的0
df.replace(to_replace={4:0},value=666)
df.columns = ['zero','one','two','three','four','five','six']
# 下面兩種方式效果一樣
df.replace(to_replace={'four':0},value=777)
# df.replace(to_replace={'four':{0:777}})
可否對指定行替換?
df.loc[3][df.loc[3] == 18] = 200
df
"""
是否還有別的方法?
"""
map替換map是Seris的一個方法。 map傳字典可以進行映射操作。
dic_data = {
'name':['張三','李四','王老五'],
'salary':[22222,7777,11111]
}
df = DataFrame(dic_data)
dic_map = {
'張三':'tom',
'李四':'jay',
'王老五':'jerry'
}
df['e_name'] = df['name'].map(dic_map)
df
map、replace、np.selectmap : 將列裡面的所有的數據進行替換;如果不存在相關鍵值,則賦值NaN replace : 替換其中一部分 np.select : 可以替換,需設定好default值。 map 也可以用別的方式來達到替換某些索引行的目的,即傳入函數,而不是字典。這種方法可以替換 np.select 。
dic_map = {
'張三':'tom',
'李四':'jay',
}
# dict.get(a,b),如果dict中存在鍵a,則返回其對應的值,否則返回b。
f = lambda x : dic_map.get(x,x)
df['name'] = df['name'].map(f)
df
替換行列名,可以用rename。參考[[#映射索引]]節。
map函數可以做運算工具:
# 超過3000的部分繳納50%的稅,計算稅後工資
df['net_pay'] = df['salary'].map(lambda x: (x - 3000) * 0.5 + 3000)
df
運算工具主要有map、apply、applymap ,用法參考[[#map 、 apply 、 applymap 用法]]。
"""
take的第一個參數只能用隱式索引,而不能用顯式索引,因為這個列表一般是要自動生成的,而不是讓用戶自己寫列名等操作。
"""
df = DataFrame(data=np.random.randint(0,100,size=(100,3)),columns=['A','B','C'])
## take的用法
df.take([2,0,1,4],axis=0)
## take更一般的用法:自動生成,將行和列均打散
df.take(np.random.permutation(3),axis=1).take(np.random.permutation(100),axis=0)[:10]