Hello, Hello everyone , I'm a programmer !
Suppose there is a file , There are 10 m url, It needs to be done for each url send out http request , And print the status code of the request result , How to write code to complete these tasks as soon as possible ?
Python There are many ways of concurrent programming , Multithreaded standard library threading,concurrency, coroutines asyncio, Of course, grequests This asynchronous Library , Each can fulfill the above requirements , Let's implement it with code one by one , The code in this article can be run directly , Give you future concurrent programming as a reference :
Define a size as 400 Queues , Then open 200 Threads , Each thread is constantly getting from the queue url And access .
The main thread reads... In the file url Put it in the queue , Then wait for all the elements in the queue to be received and processed . The code is as follows :
from threading import Thread
import sys
from queue import Queue
import requests
concurrent = 200
def doWork():
while True:
url = q.get()
status, url = getStatus(url)
doSomethingWithResult(status, url)
q.task_done()
def getStatus(ourl):
try:
res = requests.get(ourl)
return res.status_code, ourl
except:
return "error", ourl
def doSomethingWithResult(status, url):
print(status, url)
q = Queue(concurrent * 2)
for i in range(concurrent):
t = Thread(target=doWork)
t.daemon = True
t.start()
try:
for url in open("urllist.txt"):
q.put(url.strip())
q.join()
except KeyboardInterrupt:
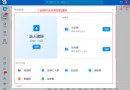
sys.exit(1)The operation results are as follows :
Is there any get To new skills ?
If you use thread pools , More advanced... Is recommended concurrent.futures library :
import concurrent.futures
import requests
out = []
CONNECTIONS = 100
TIMEOUT = 5
urls = []
with open("urllist.txt") as reader:
for url in reader:
urls.append(url.strip())
def load_url(url, timeout):
ans = requests.get(url, timeout=timeout)
return ans.status_code
with concurrent.futures.ThreadPoolExecutor(max_workers=CONNECTIONS) as executor:
future_to_url = (executor.submit(load_url, url, TIMEOUT) for url in urls)
for future in concurrent.futures.as_completed(future_to_url):
try:
data = future.result()
except Exception as exc:
data = str(type(exc))
finally:
out.append(data)
print(data)Concurrency is also a very common tool for concurrency ,
import asyncio
from aiohttp import ClientSession, ClientConnectorError
async def fetch_html(url: str, session: ClientSession, **kwargs) -> tuple:
try:
resp = await session.request(method="GET", url=url, **kwargs)
except ClientConnectorError:
return (url, 404)
return (url, resp.status)
async def make_requests(urls: set, **kwargs) -> None:
async with ClientSession() as session:
tasks = []
for url in urls:
tasks.append(
fetch_html(url=url, session=session, **kwargs)
)
results = await asyncio.gather(*tasks)
for result in results:
print(f'{result[1]} - {str(result[0])}')
if __name__ == "__main__":
import sys
assert sys.version_info >= (3, 7), "Script requires Python 3.7+."
with open("urllist.txt") as infile:
urls = set(map(str.strip, infile))
asyncio.run(make_requests(urls=urls))This is a third-party library , There are 3.8K A star , Namely Requests + Gevent[2], Make asynchronous http The request becomes simpler .Gevent The essence of is a synergetic process .
Before using :
pip install grequests
It's quite simple to use :
import grequests
urls = []
with open("urllist.txt") as reader:
for url in reader:
urls.append(url.strip())
rs = (grequests.get(u) for u in urls)
for result in grequests.map(rs):
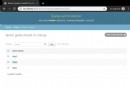
print(result.status_code, result.url)Be careful grequests.map(rs) It's concurrent . The operation results are as follows :
You can also add exception handling :
>>> def exception_handler(request, exception):
... print("Request failed")
>>> reqs = [
... grequests.get('http://httpbin.org/delay/1', timeout=0.001),
... grequests.get('http://fakedomain/'),
... grequests.get('http://httpbin.org/status/500')]
>>> grequests.map(reqs, exception_handler=exception_handler)
Request failed
Request failed
[None, None, <Response [500]>]Today I shared concurrent http Several implementations of the request , Some people say asynchronous ( coroutines ) Performance is better than multithreading , In fact, we should look at it by scene , There is no one way to apply to all scenarios , The author has done an experiment , It's also a request url, When the number of concurrent exceeds 500 when , The synergy process is significantly slower . therefore , You can't say which is better than which , Need to divide .