official account : Youer cottage
author :Peter
edit :Peter
Hello everyone , I am a Peter~
This paper introduces 11 Two ways to compare Pandas in DataFrame Sum of two columns
direct_add
for_iloc
iloc_sum
iat
apply( Specified field )
apply( For the whole DataFrame)
numpy_array
iterrows
zip
assign
sum
Send books at the end of the article , Send books at the end of the article , Send books at the end of the article !
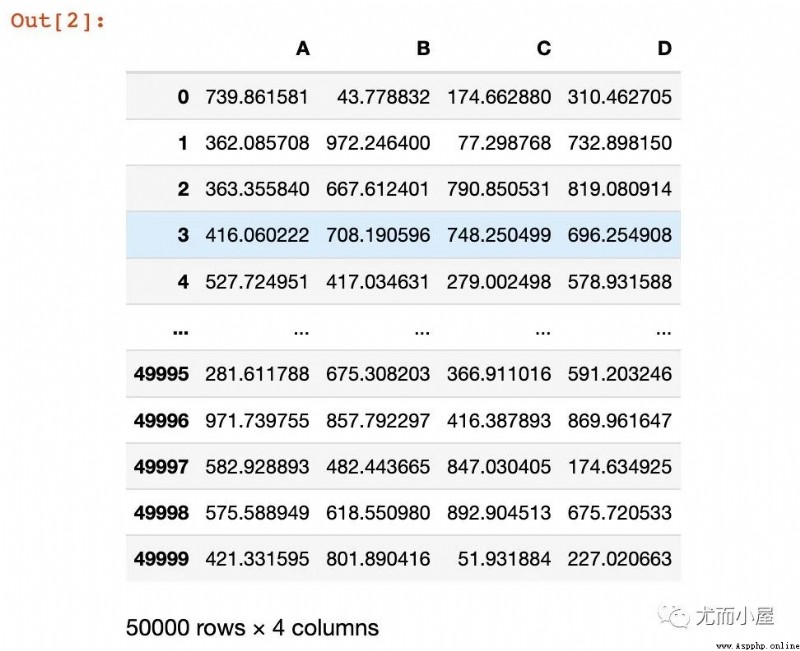
In order to have a clear effect , Simulated a 5 Million pieces of data ,4 A field :
import pandas as pd
import numpy as np
data = pd.DataFrame({
"A":np.random.uniform(1,1000,50000),
"B":np.random.uniform(1,1000,50000),
"C":np.random.uniform(1,1000,50000),
"D":np.random.uniform(1,1000,50000)
})
dataHere is the passage 11 Three different functions to implement A、C The data of two columns are added and summed E Column
hold df The two columns of are added directly
In [3]:
def fun1(df):
df["E"] = df["A"] + df["C"]for sentence + iloc Method
In [4]:
def fun2(df):
for i in range(len(df)):
df["E"] = df.iloc[i,0] + df.iloc[i, 2] # iloc[i,0] location A Columns of data iloc Method specifies the sum of columns for all rows :
0: First column A
2: The third column C
In [5]:
def fun3(df):
df["E"] = df.iloc[:,[0,2]].sum(axis=1) # axis=1 Means to operate on a column for sentence + iat location , Analogy to for + iloc
In [6]:
def fun4(df):
for i in range(len(df)):
df["E"] = df.iat[i,0] + df.iat[i, 2]apply Method , Just take out AC Two
In [7]:
def fun5(df):
df["E"] = df[["A","C"]].apply(lambda x: x["A"] + x["C"], axis=1)For the front DataFrame Use apply Method
In [8]:
def fun6(df):
df["E"] = df.apply(lambda x: x["A"] + x["C"], axis=1)Use numpy Array resolution
In [9]:
def fun7(df):
df["E"] = df["A"].values + df["C"].valuesiterrows() Iterate over each row of data
In [10]:
def fun8(df):
for _, rows in df.iterrows():
rows["E"] = rows["A"] + rows["C"]adopt zip The function will now AC Two columns of data are compressed
In [11]:
def fun9(df):
df["E"] = [i+j for i,j in zip(df["A"], df["C"])]Through derived functions assign Generate new fields E
In [12]:
def fun10(df):
df.assign(E = df["A"] + df["C"])At the designated A、C Use... On both columns sum function
In [13]:
def fun11(df):
df["E"] = df[["A","C"]].sum(axis=1)call 11 Functions , Compare their speed :


Count the mean value of each method , And put them into the same us:
result = pd.DataFrame({"methods":["direct_add","for_iloc","iloc_sum","iat","apply_part","apply_all",
"numpy_arry","iterrows","zip","assign","sum"],
"time":[626,9610000,1420,9200000,666000,697000,216,3290000,17900,888,1330]})
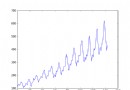
resultVisualize in descending order :
result.sort_values("time",ascending=False,inplace=True)
import plotly_express as px
fig = px.bar(result, x="methods", y="time", color="time")
fig.show()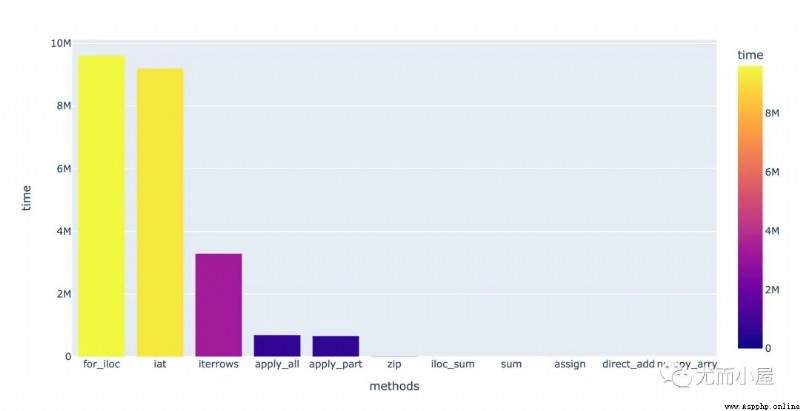
From the results we can see :
for Loops are the most time consuming , Use numpy Arrays save the most time , Difference between 4 More than ten thousand times ; Mainly because Numpy Vectorization operation used by array
sum function ( Specify axis axis=1) The effect is obviously improved
summary : If we save energy, we will save , Use... As much as possible Pandas perhaps numpy Built in functions to solve .

Past highlights
It is suitable for beginners to download the route and materials of artificial intelligence ( Image & Text + video ) Introduction to machine learning series download Chinese University Courses 《 machine learning 》( Huang haiguang keynote speaker ) Print materials such as machine learning and in-depth learning notes 《 Statistical learning method 》 Code reproduction album machine learning communication qq Group 955171419, Please scan the code to join wechat group