資源下載地址:https://download.csdn.net/download/sheziqiong/85749883
資源下載地址:https://download.csdn.net/download/sheziqiong/85749883
這裡要提一點就是後期分析錯誤的時候發現了某些困難樣本很難識別,嘗試了mix-up增強的方法從數據入手改善,mix-up簡單來說就是圖片的加權和,可以看下圖: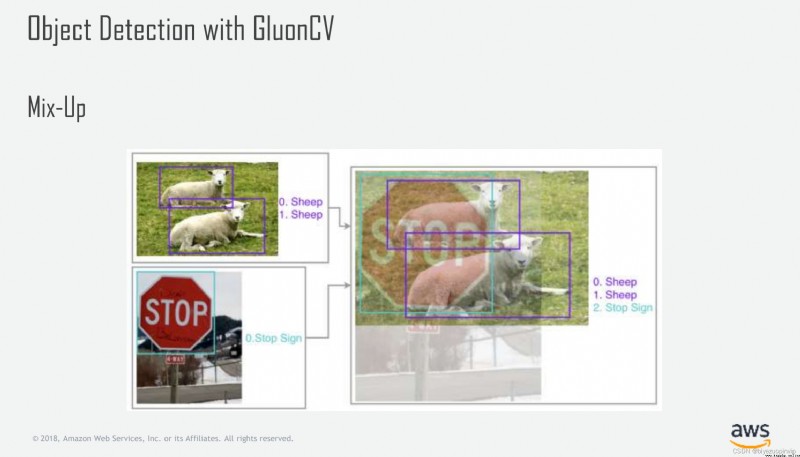
但是在本場景使用mix-up後因為整個場景背景較為復雜,兩個復雜圖片的疊加使得很多有效信息得不到很好的表達,模型的表現沒有得到提高
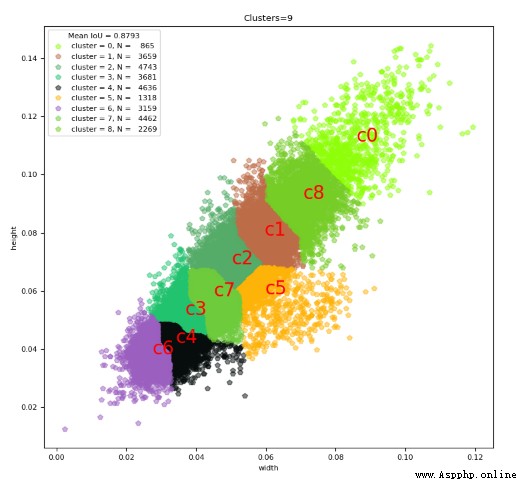
我們知道YOLO是基於anchor box來預測偏移,那anchor box的size就很重要,我們先可視化一下鋼筋框的長寬(歸一化後):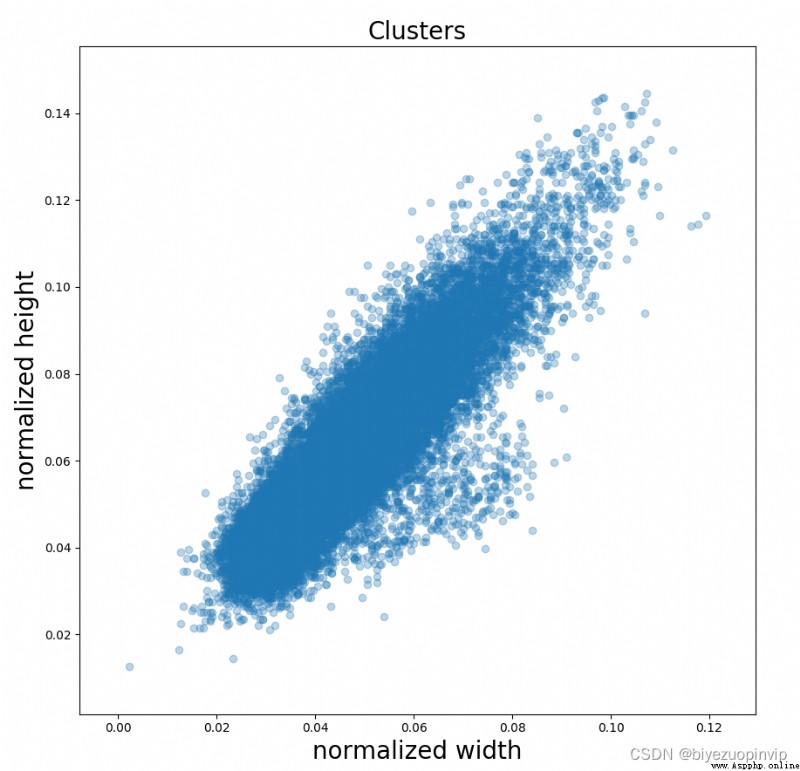
我們可以看到基本上是1:1,我們再看看YOLO v3的anchor box:
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
測試樣本中出現了許多背景樣本錯撿的問題,我們自然而然會想到Focal loss,我們知道Focal loss有兩個參數 α γ \alpha \gamma αγ,其中 γ \gamma γ固定為2不用調,主要是調整 α \alpha α,但在試驗中我發現無論怎麼調這個參數,最後訓練的時候雖然收斂的速度加快許多,但是檢測的效果都沒有變好,這和YOLO論文中作者說加了Focal loss不work一樣,後面想了很久才明白:我們知道YOLO對物體的判斷有三種:正例,負例和忽視,與ground truth的iou超過0.5就會被認為ignore,我們用YOLO v1的一張圖來說明:
我們知道整個紅色框都是這只狗,但在紅色框內的網格並不都與這只狗的gound truth的IOU超過0.5,這就讓一些本來應該忽視的樣本變成了負例,加入了我們Focal Loss的“困難樣本集”,造成了label noise,讓使用了Focal loss之後模型的表現變差。要解決這一點很簡單,將ignore的阈值從0.5調至0.1或0.2,表現馬上就提升了。(減少了很多背景錯撿,但因為阈值調低的原因多了很多框,這個可以通過後期對分數阈值的控制來消除,因為那些框基本都是低分框)

資源下載地址:https://download.csdn.net/download/sheziqiong/85749883
資源下載地址:https://download.csdn.net/download/sheziqiong/85749883