Resource download address :https://download.csdn.net/download/sheziqiong/85749883
Resource download address :https://download.csdn.net/download/sheziqiong/85749883
One point to be mentioned here is that some difficult samples are difficult to identify when analyzing errors later , tried mix-up The enhanced approach starts with data and improves ,mix-up Simply put, it is the weighted sum of pictures , Look at the picture below :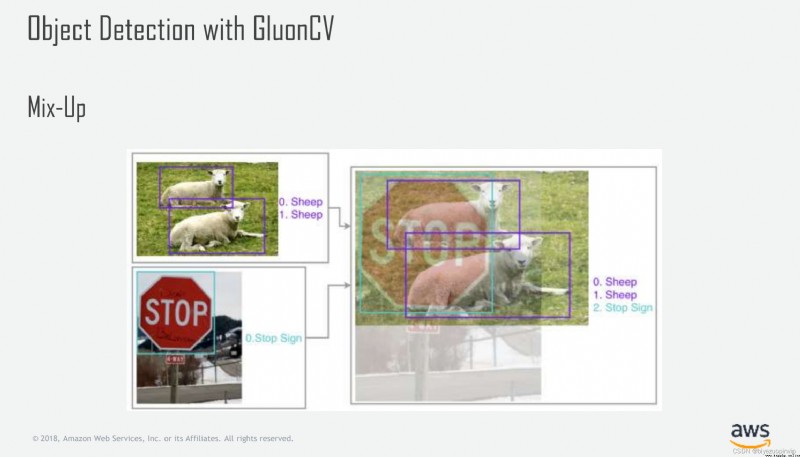
But in this scenario use mix-up Because the background of the whole scene is more complex , The superposition of two complex images makes a lot of effective information can not be well expressed , The performance of the model has not improved
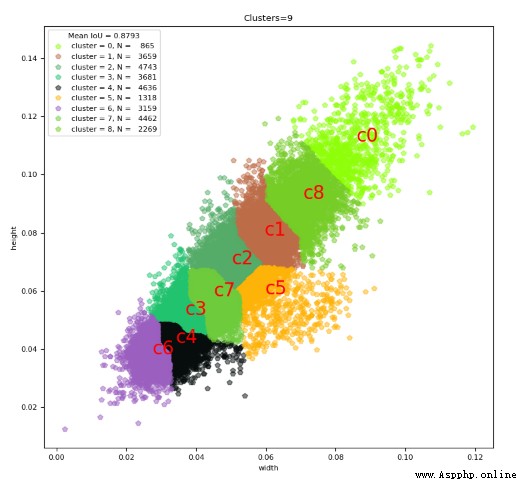
We know YOLO Is based on anchor box To predict the offset , that anchor box Of size It's very important. , Let's visualize the length and width of the steel frame ( After normalization ):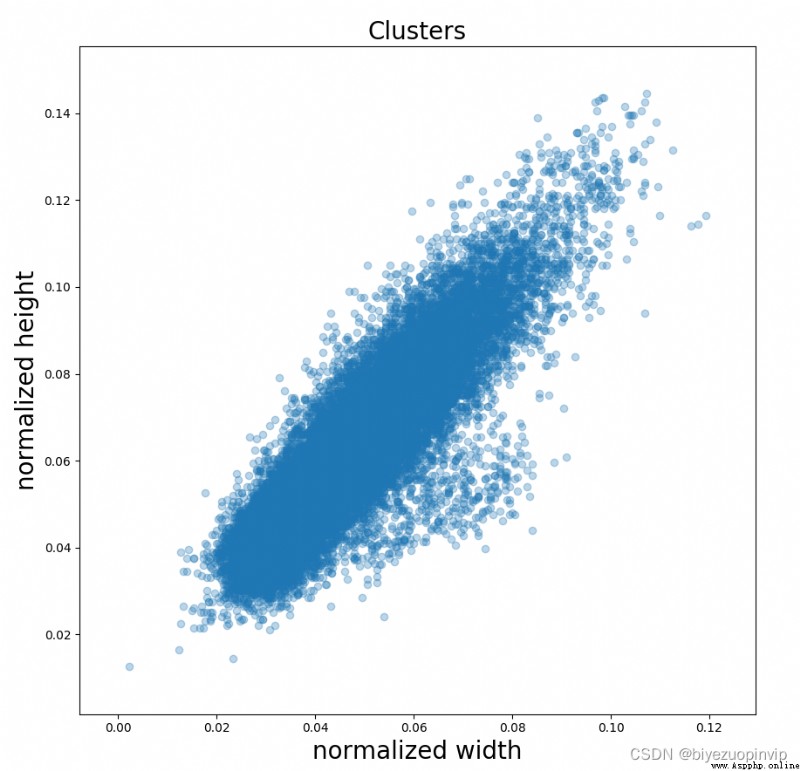
We can see that it's basically 1:1, Let's see YOLO v3 Of anchor box:
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
There are many wrong background samples in the test samples , It's natural for us to think of Focal loss, We know Focal loss There are two parameters α γ \alpha \gamma αγ, among γ \gamma γ Fixed for 2 Don't tune , Mainly adjustment α \alpha α, But in the experiment, I found that no matter how to adjust this parameter , At the end of the training, although the speed of convergence is much faster , But the results of the tests have not improved , This sum YOLO The author said in the paper that Focal loss No work equally , It took me a long time to understand : We know YOLO There are three ways to judge objects : Example , Negative examples and neglect , And ground truth Of iou exceed 0.5 It's supposed to be ignore, We use it YOLO v1 To illustrate :
We know that the whole red box is the dog , But the grid in the red box is not all the same as the dog's gound truth Of IOU exceed 0.5, This makes some samples that should have been ignored become negative examples , Join us Focal Loss Of “ Difficult sample set ”, It's caused label noise, Let's use Focal loss After that, the performance of the model became worse . It's easy to solve this , take ignore The threshold is from 0.5 Transfer to 0.1 or 0.2, Performance immediately improved .( It reduces a lot of background errors , But because the threshold is lowered, there are many more boxes , This can be eliminated by controlling the score threshold later , Because those boxes are basically low sub frames )

Resource download address :https://download.csdn.net/download/sheziqiong/85749883
Resource download address :https://download.csdn.net/download/sheziqiong/85749883