目錄
1 引言
2 問題描述
3 目的
4 重要性
5 創新點
6 Python代碼
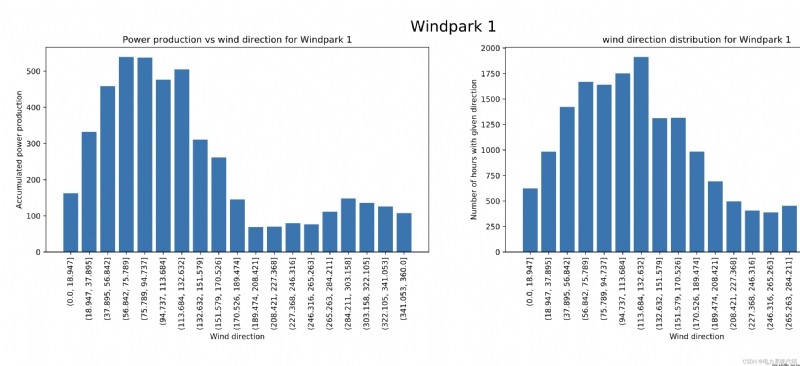
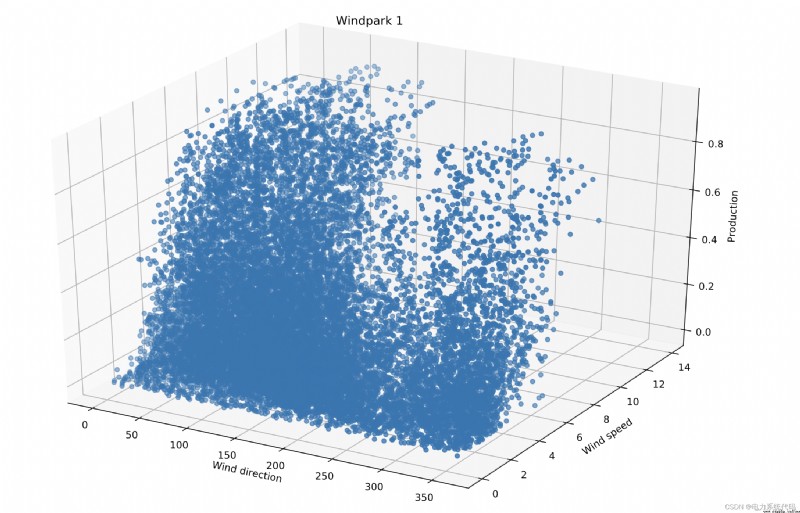
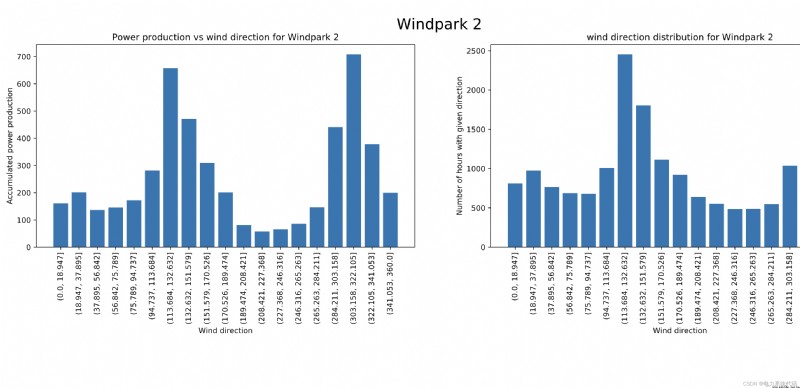
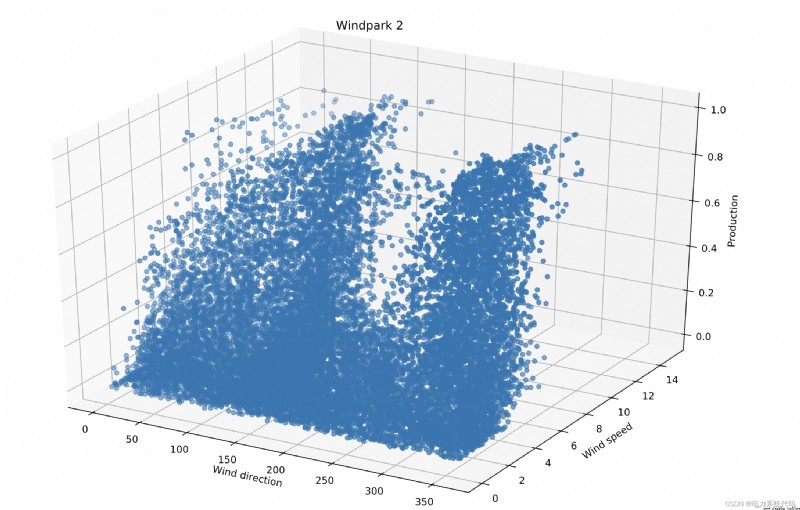
7 結果

可再生能源的開發利用一直是世界上最熱門的熱點之一。風力發電由於清潔和廣泛的可用性,正迅速向大規模產業發展,並具有波動性和間歇性電力的特點。准確可靠的風電預測方法對於電能質量、可靠性管理以及降低旋轉備用供電成本至關重要.
風能預測對應於對近期一個或多個風力渦輪機的預期產量的估計。在電網中,任何時候都必須在用電量和發電量之間保持平衡——否則可能會出現電能質量或供應的干擾。風力發電是風速的直接函數,與傳統發電系統相比,風力發電不易調度。因此,風力發電的波動受到了極大的關注。
一種風電功率預測數據挖掘方法,由K-means聚類方法和bagging神經網絡組成。根據氣象條件和歷史功率對歷史數據進行聚類。皮爾遜相關系數用於計算預測日與聚類之間的距離。
風電功率預測(WPF)對於有效指導電網調度和風電場生產規劃具有重要意義。風的間歇性和波動性導致訓練樣本的多樣性對預測精度有重大影響。由於必須保持消耗和發電之間的平衡,因此風力發電的波動是一個非常重要的研究領域。
為了處理訓練樣本的動態並提高預測精度,提出了一種針對短期WPF的由MinMax歸一化、K-means聚類和深度神經網絡組成的數據挖掘方法。基於歷史天數之間的相似性,K-means聚類用於通過取各個聚類的質心來減少數據集。此外,當給定參數的標准化值時,這個簡化的數據集用於預測未來產生的功率。
本文僅展現部分代碼,全部代碼點:正在為您運送作品詳情
import numpy as np
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
import pandas as pd
import datetime as dt
import matplotlib.dates as mdates
def str_to_datetime(date):
return dt.datetime.strptime(date, '%Y-%m-%d %H:%M:%S')
def main():
df = pd.read_csv('Processed_data/wp7.csv', names=['dates', 'ws-2', 'ws-1', 'ws', 'ws+1', 'wd-2',
'wd-1', 'wd', 'wd+1', 'hour_from_06', 'week', 'mounth',
'production'], sep=',', skiprows=1)
real_production = df.production[48:]
real_production.index = np.arange(len(real_production))
M = len(real_production)
predicted_production = df.production[:M]
df['dates'] = df['dates'].apply(str_to_datetime)
xDates = df.dates.iloc[0:M]
realFrame = pd.DataFrame({"Dates": xDates, "Real": real_production})
predFrame = pd.DataFrame({"Dates": xDates, "Prediction": predicted_production})
print("MSE: ", mean_squared_error(realFrame.Real, predFrame.Prediction))
fig, ax = plt.subplots()
ax.plot(realFrame["Dates"], realFrame["Real"])
ax.plot(predFrame["Dates"], predFrame["Prediction"])
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m.%Y'))
plt.show()
if __name__ == '__main__':
main()