Catalog
1 introduction
2 Problem description
3 Purpose
4 Importance
5 Innovation points
6 Python Code
7 result

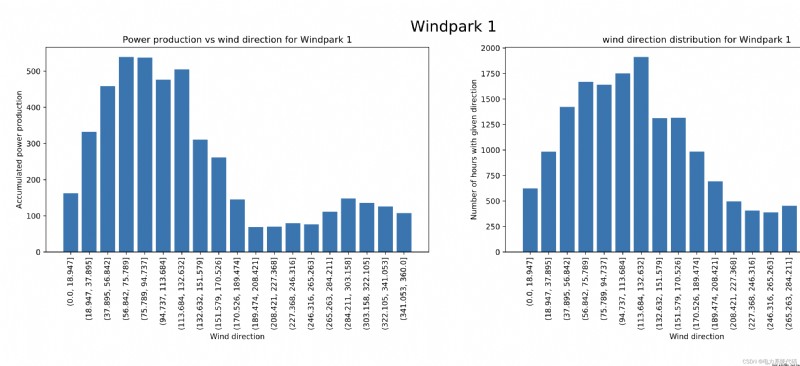
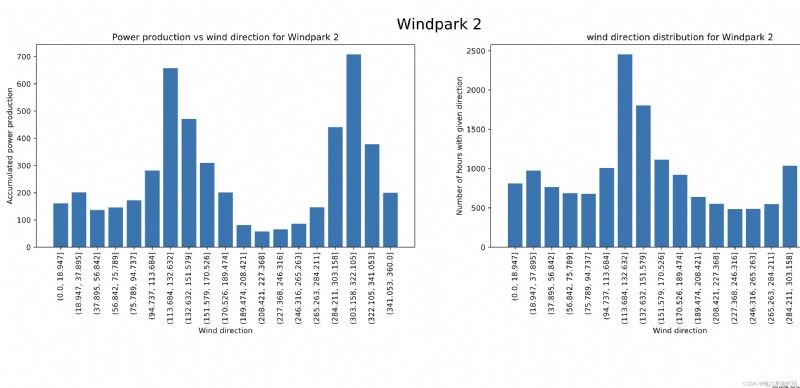
The development and utilization of renewable energy has always been one of the hottest hot spots in the world . Wind power generation due to its cleanliness and wide availability , It is rapidly developing into a large-scale industry , It has the characteristics of fluctuation and intermittent power . Accurate and reliable wind power forecasting method is very important for power quality 、 Reliability management and reducing the cost of rotating reserve power supply are very important .
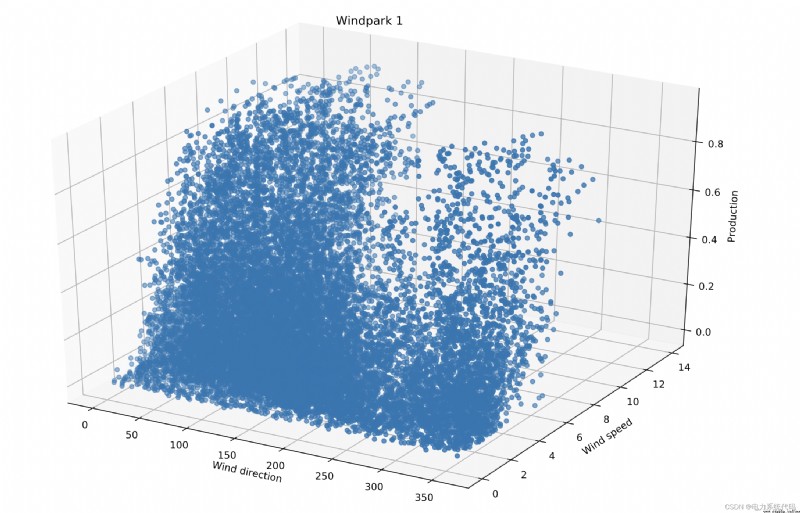
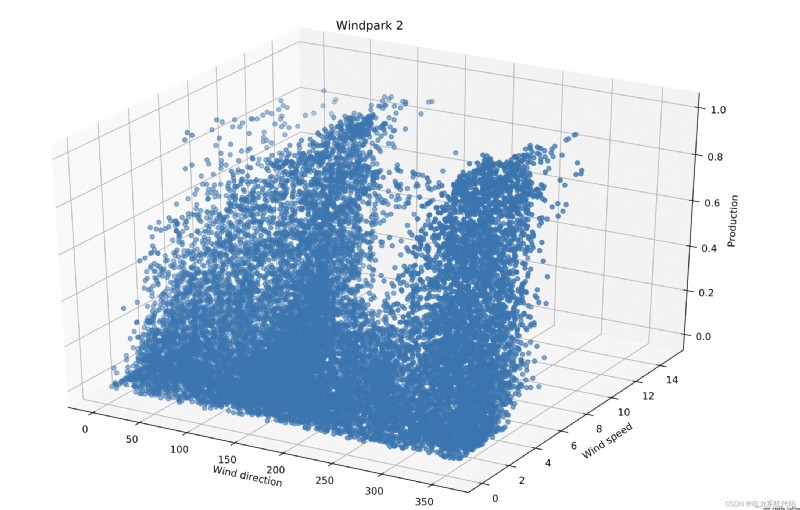
The wind energy forecast corresponds to an estimate of the expected production of one or more wind turbines in the near future . In the grid , There must be a balance between electricity consumption and electricity generation at all times —— Otherwise, power quality or supply interference may occur . Wind power generation is a direct function of wind speed , Compared with traditional power generation system , Wind power generation is not easy to dispatch . therefore , The fluctuation of wind power generation has received great attention .
A data mining method for wind power prediction , from K-means Clustering methods and bagging The neural network consists of . Cluster historical data according to meteorological conditions and historical power . Pearson correlation coefficient is used to calculate the distance between the predicted day and the cluster .
Wind power prediction (WPF) It is of great significance to effectively guide power grid dispatching and wind farm production planning . The intermittence and fluctuation of wind lead to the diversity of training samples, which has a significant impact on the prediction accuracy . Because the balance between consumption and power generation must be maintained , Therefore, the fluctuation of wind power generation is a very important research field .
In order to deal with the dynamics of training samples and improve the prediction accuracy , This paper presents a method for short-term WPF By MinMax normalization 、K-means Data mining method composed of clustering and deep neural network . Based on the similarity between historical days ,K-means Clustering is used to reduce the data set by taking the centroid of each cluster . Besides , When the normalized value of the parameter is given , This simplified data set is used to predict future power generation .
This article only shows part of the code , All code points : We are shipping your work details
import numpy as np
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
import pandas as pd
import datetime as dt
import matplotlib.dates as mdates
def str_to_datetime(date):
return dt.datetime.strptime(date, '%Y-%m-%d %H:%M:%S')
def main():
df = pd.read_csv('Processed_data/wp7.csv', names=['dates', 'ws-2', 'ws-1', 'ws', 'ws+1', 'wd-2',
'wd-1', 'wd', 'wd+1', 'hour_from_06', 'week', 'mounth',
'production'], sep=',', skiprows=1)
real_production = df.production[48:]
real_production.index = np.arange(len(real_production))
M = len(real_production)
predicted_production = df.production[:M]
df['dates'] = df['dates'].apply(str_to_datetime)
xDates = df.dates.iloc[0:M]
realFrame = pd.DataFrame({"Dates": xDates, "Real": real_production})
predFrame = pd.DataFrame({"Dates": xDates, "Prediction": predicted_production})
print("MSE: ", mean_squared_error(realFrame.Real, predFrame.Prediction))
fig, ax = plt.subplots()
ax.plot(realFrame["Dates"], realFrame["Real"])
ax.plot(predFrame["Dates"], predFrame["Prediction"])
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m.%Y'))
plt.show()
if __name__ == '__main__':
main()