Suddenly want to see a movie , I analyzed the cat's eye movie , But I don't know which movie is good , Just casually flipped , It doesn't feel very accurate , Then I analyzed the data in batches , However, the result is not so ideal , The specific implementation process is as follows , If you are interested, you can try
1、 Enter the cat's eye movie site , Select movie category , Select detailed classification as shown in the figure below 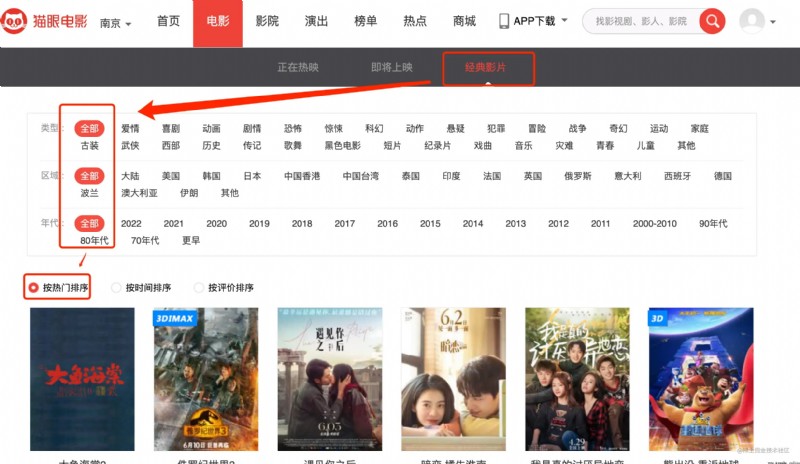
2、 Analyze web content : Open console , Select a movie tab , You can see the corresponding... On the console html style 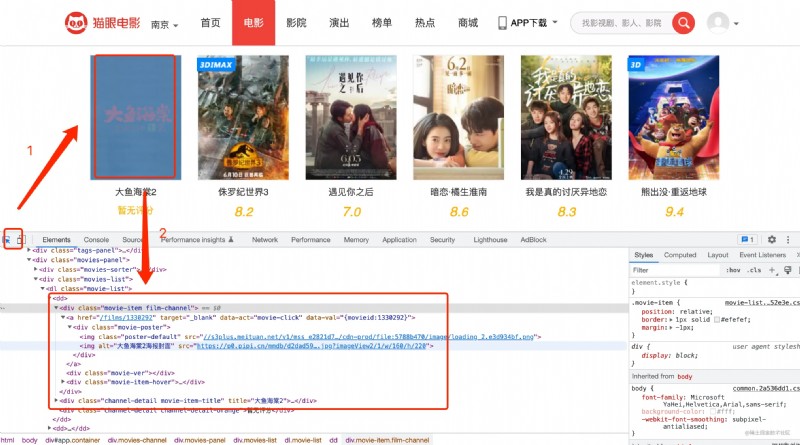
def get_html(url):
print(" Access to web pages : %s" % url)
# agent
proxies = [
{
'http': 'http://202.55.5.209:8090'},
{
'http': 'http://183.247.199.114:30001'},
{
'http': 'http://122.9.101.6:8888'},
{
'http': 'http://202.55.5.209:8090'},
]
# Request header camouflage
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
"Cookie": "uuid_n_v=v1; uuid=965711E0E8C611EC8A445B788061A84C64DB045EA13840149498F0104B8AF19A; _csrf=231cfce2d54abbd1bf2609ca76cd22ec894318c8223a9e698eb9b798bc2adbd8; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1654870020; _lx_utm=utm_source=google&utm_medium=organic; _lxsdk_cuid=1814df090c8c8-02bcc6fa43763b-1d525635-13c680-1814df090c8c8; _lxsdk=965711E0E8C611EC8A445B788061A84C64DB045EA13840149498F0104B8AF19A; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1654870030; __mta=142572173.1654870021186.1654870021186.1654870030627.2; _dd_s=logs=1&id=aa00cee7-93d3-4b37-aa97-0eb2f74923bf&created=1654870020029&expire=1654871326477; _lxsdk_s=1814df090c9-86d-7ca-093||6"
}
resp = requests.get(url, headers=headers, proxies=random.choice(proxies))
if resp.status_code == 200:
return resp.text
return ""
def extract_html(html):
print(" Data parsing start ")
soup = BS4(html, "lxml")
hover_list = soup.find_all("div", class_="movie-item-hover")
for hover in hover_list:
i_list = []
name = hover.find("span", class_="name").text
score = hover.find("span", class_="score")
if score is None:
score = " No score "
else:
score = score.text
info_list = hover.find_all("div", class_="movie-hover-title")
i_list.append(name)
i_list.append(score)
num = 0
for info in info_list:
num = num + 1
if num == 1:
continue
i_list.append(str.strip(info.find("span", class_="hover-tag").next_sibling))
with open("data.txt", "a+") as d:
d.writelines(str(i_list) + "\n")
def main():
print(" The task begins ")
for i in range(20, 40):
print(" Start the first %d page " % i)
url = "https://www.maoyan.com/films?showType=3&offset=%d" % (i * 30)
html = get_html(url)
extract_html(html)
print(" Completion of %d page " % i)
sleep_time = random.randint(1, 3)
print(" Sleep %d page " % sleep_time)
time.sleep(sleep_time)
print(" Task to complete ")
def analysis():
name_list = []
score_list = []
words = ""
with open("data.txt", "r") as f:
num = 0
while 1:
data = f.readline()
if data == "" or num > 1000:
break
data = data.replace("]", "")
data = data.replace("[", "")
data = data.strip("\n")
data = data.replace("'", "")
data = data.replace(" ", "")
data_list = data.split(",")
# name_list.append(data_list[0])
name_list.append(str(num))
score_list.append(float(data_list[1]) if data_list[1] != " No score " else 0)
num = num + 1
print(data_list[0] + ":" + data_list[2])
words = words + data_list[2] + ","
words = words.replace("/", ",")
# Handle the problem of Chinese garbled code in charts
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.figure(figsize=(10, 10.5))
plt.scatter(name_list, score_list, c="red")
plt.xlabel(" The movie ")
plt.ylabel(" fraction ")
plt.title(" Movie ratings ")
plt.show()
w = wordcloud.WordCloud(width=1000, height=700, background_color='white', font_path='11.ttf', collocations=False,
scale=1.5)
w.generate(words)
w.to_file('res.png')
1、 Scatter plot 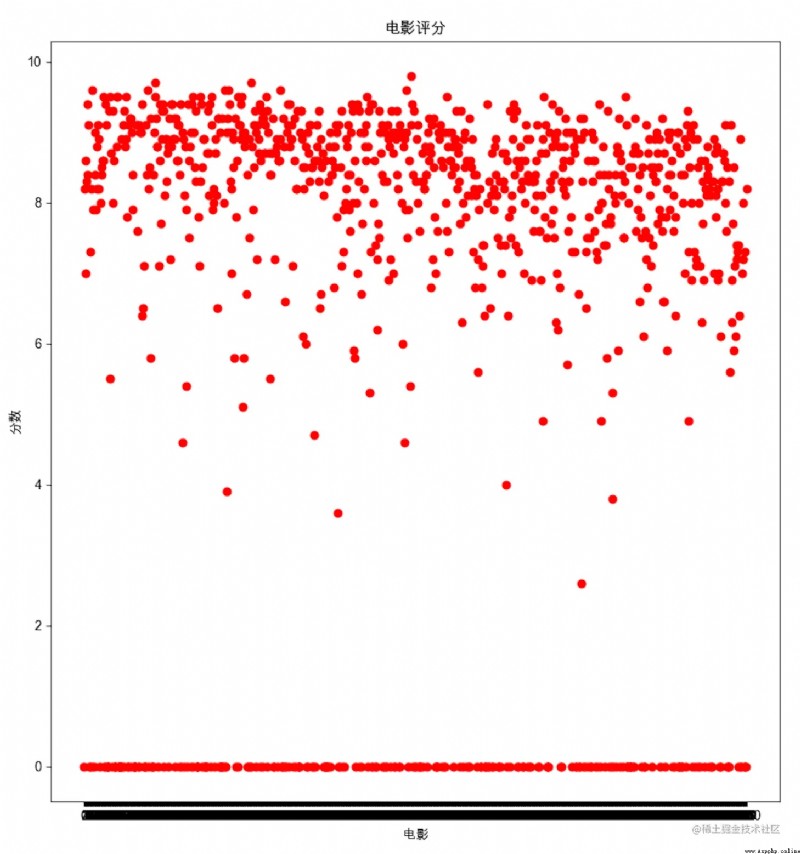
2、 The word cloud 
The score of commercial film websites is not very accurate , A bit disappointed , Which platform do you think is more accurate , We can discuss ?