Give you three solutions to deal with Chinese garbled code in the process of web crawler , I hope it will be helpful for your study .
It does look big , For beginners of reptiles , This random code is placed in front of yourself , Like a tiger in the way . But don't panic , Here are three methods for you , It is specially used for Chinese random code , I hope you will encounter the problem of Chinese garbled code again later , Here you can get inspiration !
In fact, the key to solving the problem is , Is to deal with the garbled part , The treatment scheme can be carried out mainly from two aspects . One is to encode the whole web page in advance , The second is to encode the part of Chinese garbled code . Here is an example 3 Methods , There must be other ways , You are also welcome to comment in the comment area .
In fact, there are many forms of Chinese garbled code , But the two common ones are as follows :
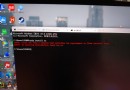
1、 When a web page appears, the code is gbk, The obtained content is printed on the console when the following situations are similar :
ÃÀÅ µçÄÔ×À ¼üÅÌ »ú·¿ ¿É° С½ã½ã4k±ÚÖ½
2、 When a web page appears, the code is gbk, The obtained content is printed on the console when the following situations are similar :
�װŮ�� ��Ů ˮ СϪ Ψ��
Although it seems that the console output is normal , No report error :
Process finished with exit code 0
But the output Chinese content , But not what ordinary people can understand .
In this case , It can be solved by using the three methods given in this paper , To test that !
## 3、 ... and 、 Concrete realization
1) Method 1 : take requests.get().text Change it to requests.get().content We can see through text() Method , Then print out , Indeed, there will be garbled code , As shown in the figure below .
At this point, consider changing the request to .content, What you get is normal .
2) Method 2 : Manual Specify page encoding ****
# Manually set the encoding format of response data response.encoding = response.apparent_encoding
This method is a little more complicated , But it's easier to understand , For beginners , It's better to accept . If you find the above method difficult to remember , Or you can try to specify directly gbk Coding can also be processed , As shown in the figure below :
The two methods described above are for the overall coding of web pages , Remarkable effect , The next third method is to use the general coding method to deal with the Chinese local garbled code .\
*3) Method 3 : Use a common coding method
img_name.encode('iso-8859-1').decode('gbk')Use a common coding method , Set the code where there is garbled code in Chinese . Or the current example , in the light of img_name Code setting , Specify encoding and decoding , As shown in the figure below .
In this way , The problem of Chinese garbled code is solved .
in the light of Python Chinese garbled code in the process of web crawler , given 3 A solution to garbled code , Although the article cites 3 Methods , But there must be other ways , You are also welcome to comment in the comment area .