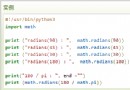
Hello everyone
Recently, I saw a group of friends discussing a wide table and variable length table , In fact, such requirements are also common in our daily data processing . Integrate the wisdom of the group , Let's have a look today excel And python How to realize this requirement !
Catalog :
excel To do the reverse perspective operation, you need Power Query.
First step : Select data , And then in menu bar - data - Click on From table / Area
Select data - From table
The second step : When creating a table , Select whether to include the title according to the actual situation ( This example does not include )
Create table
The third step : Click on Above confirm After the button appears Power Query Editor
Power Query Editor
Step four : according to control, Select all the columns to be operated ( perhaps shift Continuous column retrieval ), Until then transformation - Click on Inverse perspective column
Inverse perspective column
Step five : We can see the results we need
Inverse perspective results
Step six : Click on top left corner file , Choose Close and upload
Upload data
Step seven : We found that , In the original table surface 1 Tab of , It's exactly what we expect Inverse perspective results , Get it done !( Delete the irrelevant column attribute )
Final result data
What we need to do is reverse the operation of perspective , That is to say Inverse perspective ,pandas Nature also provides very convenient function methods , Let's have a look .
Grand recommendation melt Function method :
df.melt( id_vars=None, value_vars=None, var_name=None, value_name='value', col_level: 'Level | None' = None, ignore_index: 'bool' = True, ) -> 'DataFrame' Docstring: Unpivot a DataFrame from wide to long format, optionally leaving identifiers set.
id_vars:tuple,list or ndarray( Optional ), Columns used to identify variables
value_vars:tuple, A list or ndarray, Optional , Columns to be unperspected . If not specified , Is not set to id_vars All columns of
var_name:scalar, be used for “ Variable ” Column name . If None, Then use frame.columns.name or “variable”
value_name:scalar, The default is “ value”, be used for “ value” Column name
col_level:int or str, Optional , If the column is MultiIndex, Use this level to melt
No more examples , Take the case data directly !
import pandas as pd # Reading data df = pd.read_excel(r'0927 Test data .xlsx', header=None) df
Data preview
# Direct inverse perspective ( df.melt(id_vars=df.columns[:2], # Identify the column of the variable value_vars=df.columns[2:], # Note that the result is the same ignore_index=True, # Ignore the index ) .sort_values(by=[0,1]) # Sort .dropna() # Delete rows with null values )
result
Is it convenient , You can do it directly with one function , thank Group members 1px Ideas provided .
This solution , I have dealt with it for my friend before , But when I saw this problem, I actually used another more complex solution , It's so funny .
Let's also look at this more troublesome solution :
The core is explode Explosion column
data = df.iloc[:,:2].copy() data
initialization data
# The auxiliary column is used to store the store information list data[' Auxiliary column '] = list(df.loc[:,2:].values) data
The auxiliary column stores the store information list
# The explosion column fulfills the requirements data.explode(column=' Auxiliary column ').dropna()
The explosion column fulfills the requirements
The above is the whole content of this meeting , Around the wide table to the long table , That is to say Inverse perspective The operation of . Actually excel and pandas Both provide very simple and direct processing methods , After you are familiar with the operation, you will be familiar with the road , Solve problems efficiently .
however , We can also exercise our logical thinking ability through other ideas , Maybe it can strengthen your ability to deal with complex problems !
 [background development of Django project] data statistics - statistics of total users, statistics of daily increasing users and statistics of daily active users (3)
[background development of Django project] data statistics - statistics of total users, statistics of daily increasing users and statistics of daily active users (3)
One 、 Statistics of total user