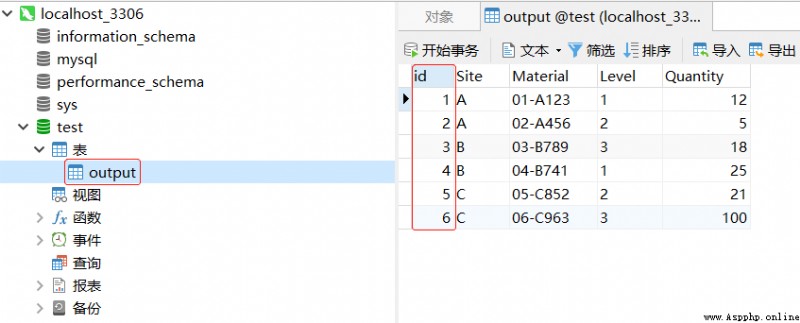
In recent development requirements , utilize Pandas Process the data and integrate the calculations to generate a Output Result sheet Store in database , Later, colleagues asked Output Add... To the table Primary key id, Think of yourself as Navicat Add the primary key manually id It's not the way , Because a new one is generated every week Output surface , Simply use Python Add a primary key to a table in the database id, Convenient, fast and worry free
DROP TABLE IF EXISTS `Output`;
CREATE TABLE `Output` (
`Site` varchar(255) DEFAULT NULL,
`Material` varchar(255) DEFAULT NULL,
`Level` varchar(255) DEFAULT NULL,
`Quantity` int(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `Output` VALUES ('A', '01-A123', '1', '12');
INSERT INTO `Output` VALUES ('A', '02-A456', '2', '5');
INSERT INTO `Output` VALUES ('B', '03-B789', '3', '18');
INSERT INTO `Output` VALUES ('B', '04-B741', '1', '25');
INSERT INTO `Output` VALUES ('C', '05-C852', '2', '21');
INSERT INTO `Output` VALUES ('C', '06-C963', '3', '100');Output surface ( Result output table )

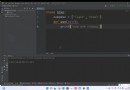
# Yes Output Table add primary key
import pymysql
# Set database connection information :ip Address 、 Port number 、 user name 、 password 、 Database name
db = pymysql.connect(host="127.0.0.1", port=3306, user="root", password="123456", database="test")
# Use cursor() Method to create a cursor object cur
cur = db.cursor()
# sql sentence
sql = '''ALTER TABLE `%s` add column `id` int(10) not null auto_increment primary key first ''' % ('Output')
try:
# Use execute() Method execution SQL sentence
cur.execute(sql)
# Commit to database execution
db.commit()
print('Add primary key successfully.')
except Exception as e:
# Roll back if an error occurs
db.rollback()
print(str(e))
finally:
# Close database connection
db.close()Result display :