️可迭代的
一、for循環針對的數據類型特點
二、可迭代的與可迭代協議
1、迭代的概念
2、認識dir內置函數和雙下方法
3、 如何證明一個數據類型是可迭代的
4、可迭代協議
5、拓展點:內置enumerate函數的用法
6、總結可迭代的知識點
️迭代器
一、迭代器協議
二、迭代器秘密方法的使用
三、迭代器協議的驗證
四、驗證range()是可迭代對象還是迭代器
五、迭代器的好處
六、迭代器總結
假如給了你一個列表 lis = [1,2,3,4],叫你讀取列表中的數據,那要如何做?
首先我們想到的是可能是索引讀法,比如要讀列表中的第二個元素可以用 lis[1]來讀到,
其次那就是可以用最最常用的for循環來讀取數據了,其中for循環的取值方式想必大家都應該也必須知道了,那就是———按順序依次取值,既不關心取到的每一個值的位置,也不會跳過某一個值去取其他位置上的值。那此時想必你心中會有一個疑問那就是for循環為什麼會這樣取值,在for循環的內部究竟有哪一股神秘的代碼驅使它這樣工作呢?看完下面內容想必就有了答案!
帶著這個疑問我們就來接觸一下迭代器吧
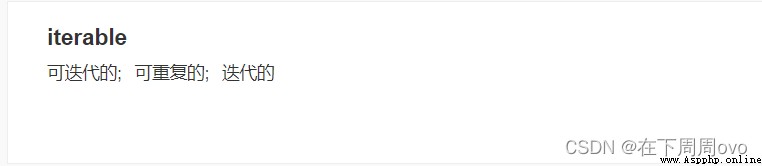
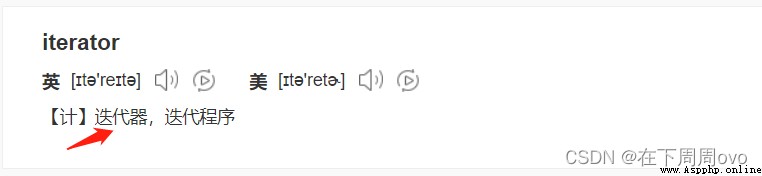
在開始前我們先了解兩個英語單詞
其次我們再看下面這兩段代碼
第一段:我們先將一個列表進行for循環,得到以下結果
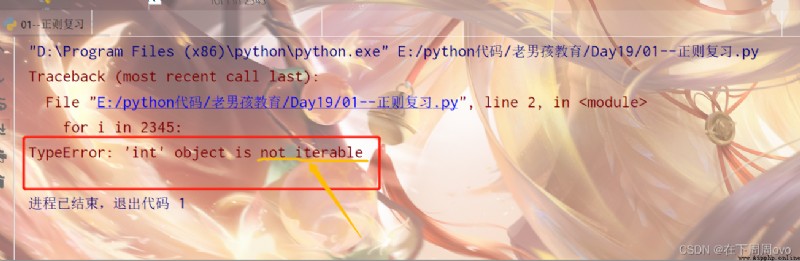
for i in [2,3,4,5] print(i) 輸出結果: 2 3 4 5第二段:換個思路我們將列表替換為數字2345那麼結果會是什麼呢?
for i in 2345: print(i)輸出結果:
結果竟然是報錯:那我們再看報錯內容的翻譯:
它說int對象是不可迭代的,那麼我們現在應該了解到了能夠使用for循環的數據類型應該要是可迭代的,那麼究竟哪些數據類型時可迭代的呢,我們應該如何區分呢?
將一個數據集中所有的數據按照順序“一個接著一個一次取出”這個過程就叫做迭代
- dir內置函數:
python中的dir()函數dir() 函數不帶參數時,返回當前范圍內的變量、方法和定義的類型列表;帶參數時,返回參數的屬性、方法列表。如果參數包含方法__dir__(),該方法將被調用。如果參數不包含__dir__(),該方法將最大限度地收集參數信息。簡而言之dir可以告訴我們所傳入的數據類型(參數)所包含的所有內置使用方法
print(dir(list)) #告訴我列表擁有的所有方法 print(dir([1,2])) #告訴我列表擁有的所有方法 #上面的兩種方法雖然實參不同但函數返回值相同輸出結果:
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort'] ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
- 雙下方法:
概念:像'__add__', '__class__', '__contains__'等含有雙下劃線的方法叫做雙下方法
首先我們知道讓兩個列表相加的方法是:
print([1]+[2]) 輸出結果 [1,2]其實還可以這樣寫:
print([1].__add__([2])) 輸出結果: [1,2]這兩者的聯系是:其實在函數運行時並不認識"+,- ,* , /"號,因為程序只認識代碼,所以你使用"+"時號程序內部會自動幫你調用"__add__"這個函數方法。
要證明一個數據類型是否是可迭代的我們要用到collections.abc模塊
其中可迭代的數據類型是:list、dic、str、set、range()、f = open()、enumerat
from collections.abc import Iterable a = 135 c = {} print(isinstance(a,Iterable)) print(isinstance(c,Iterable)) print(isinstance([],Iterable)) print(isinstance((1,2),Iterable)) print(isinstance({1,2,3},Iterable)) print(isinstance(list,Iterable)) 輸出結果: False True True True True False找出這些數據類型的公共內置使用方法發現都有'__iter__',可得出結論:含有'__iter__'內置方法的數據是可迭代的(iterable)。
下面就是用集合的去重性找出這些數據類型的公共內置使用方法:
ret = set(dir([]))&set(dir({}))&set(dir(''))&set(dir(range)) print(ret)
Python 迭代協議由__iter__方法與__next__方法構成,若對象具有__iter__方法,稱該對象為“可迭代對象(iterable object)”也就是可跌代的。若對象具有__next__方法,稱該對象為“迭代器(iterator)”。__iter__方法必須返回一個迭代器對象,__next__方法不斷的返回下一元素,或者拋出StopIteration。__next__方法是 Python 迭代協議的核心,__iter__方法是迭代協議的輔助——將可迭代對象轉換成迭代器。
在大多數情況下,可迭代對象會自動轉換成迭代器,迭代操作本質是由“迭代器”負責——每次迭代輸出一個元素,當無元素時,會拋出StopIteration。這種自動轉換機制是造成“可迭代對象”與“迭代器“概念模糊的主要原因。 另一造成混淆的原因就是,對象即是可迭代對象,也是迭代器——當對象具有__iter__方法與__next__方法,並且__iter__方法返回自身,一個典型對象就是“文件對象”。
我們可以用上面的dir方法判斷數據類型內部是否含有__iter__方法,代碼如下:
print(1,'__iter__' in dir(int)) print(2,'__iter__' in dir(bool)) print(3,'__iter__' in dir(list)) print(4,'__iter__' in dir(dict)) print(5,'__iter__' in dir(str)) print(6,'__iter__' in dir(tuple)) print(7,'__iter__' in dir(range(1))) print(8,'__iter__' in dir(enumerate([]))) 輸出結果: 1 False 2 False 3 True 4 True 5 True 6 True 7 True 8 True
可能會疑問enumerate怎麼用使用方法如下:
enumerate()是python的內置函數 enumerate在字典上是枚舉、列舉的意思 對於一個可迭代的(iterable)/可遍歷的對象(如列表、字符串),enumerate將其組成一個索引序列,利用它可以同時獲得索引和值 enumerate多用於在for循環中得到計數 例如對於一個seq,得到: (0, seq[0]), (1, seq[1]), (2, seq[2])
enumerate()返回的是一個enumerate對象
使用方法如下:
for i,k in enumerate( ['as','d','hh']): print(i,k) print(enumerate( ['as','d','hh']))輸出結果:
總結一下我們現在所知道的:可以被for循環的都是可迭代的,要想可迭代,內部必須有一個__iter__方法。
那麼內部的__iter__方法做了什麼事情呢?
print([].__iter__()) 輸出結果: <list_iterator object at 0x000002A79C69F640>執行了list([ ])的__iter__方法,我們好像得到了一個list_iterator,翻譯後就是列表迭代器。
這下就明白了一個可迭代對象通過調用內部的__iter__方法就會變成一個迭代器
迭代器協議:
迭代器協議---內部含有__next__和__iter__方法的就是迭代器
從上面我們知道了一個可迭代對象通過調用內部的__iter__方法就會變成一個迭代器
[].__iter__()就是一個列表迭代器
我們來看看這個列表的迭代器比起列表來說實現了哪些新方法,這樣就能揭開迭代器的神秘面紗了吧?
''' dir([1,2].__iter__())是列表迭代器中實現的所有方法,dir([1,2])是列表中實現的所有方法,都是以列表的形式返回給我們的,為了看的更清楚,我們分別把他們轉換成集合,然後取差集。 ''' #print(dir([1,2].__iter__())) #print(dir([1,2])) print(set(dir([1,2].__iter__()))-set(dir([1,2]))) 輸出結果: {'__length_hint__', '__next__', '__setstate__'}由上面我們知道,迭代器比原類型多出來了{'__setstate__', '__length_hint__', '__next__'}方法,這就是迭代器的秘密
上面我們知道迭代器比原類型多出來了{'__setstate__', '__length_hint__', '__next__'}方法
那麼這些方法有什麼用呢?
#__length_hint__()打印出的是元素個數 print([5,2,0,'swx'].__iter__().__length_hint__()) 輸出結果: 4 #__setstate__:可以指定開始取值的位置 #__next__取關鍵性的作用 l = [1,2,3] iterator = l.__iter__() print(iterator.__next__()) print(iterator.__next__()) print(iterator.__next__()) 輸出結果: 1 2 3這三個方法中,能讓我們一個一個取值的神奇方法是誰?沒錯!就是__next__
在for循環中,就是在內部調用了__next__方法才能取到一個一個的值。
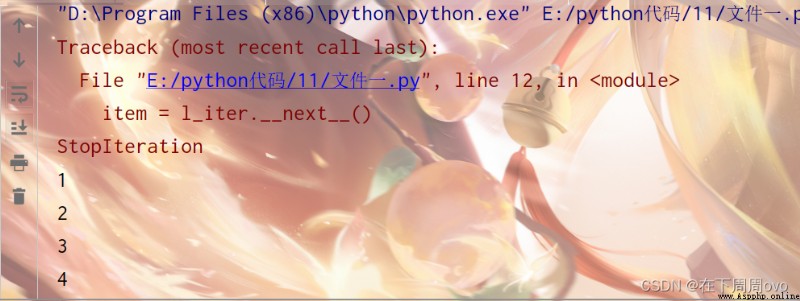
那接下來我們就用迭代器的next方法來寫一個不依賴for的遍歷。
l = [1,2,3,4] l_iter = l.__iter__() item = l_iter.__next__() print(item) item = l_iter.__next__() print(item) item = l_iter.__next__() print(item) item = l_iter.__next__() print(item) item = l_iter.__next__() print(item)輸出結果:
為什麼會報錯呢?
如果我們一直取next取到迭代器裡已經沒有元素了,就會拋出一個異常StopIteration,告訴我們,列表中已經沒有有效的元素了。
這個時候,我們就要使用異常處理機制來把這個異常處理掉。
l = [1,2,3,4] l_iter = l.__iter__() while True: try: item = l_iter.__next__() print(item) except StopIteration: break
上面說迭代器協議---內部含有__next__和__iter__方法的就是迭代器
用以下代碼驗證
class A: def __iter__(self):pass #def __next__(self):pass from collections.abc import Iterable from collections.abc import Iterator print(isinstance(A(),Iterator)) print(isinstance(A(),Iterable)) 輸出結果: False True class A: def __iter__(self):pass def __next__(self):pass from collections.abc import Iterable from collections.abc import Iterator print(isinstance(A(),Iterator)) print(isinstance(A(),Iterable)) 輸出結果: True True
from collections.abc import Iterator print('__next__' in dir(range(12))) #查看'__next__'是不是在range()方法執行之後內部是否有__next__ print('__iter__' in dir(range(12))) #查看'__next__'是不是在range()方法執行之後內部是否有__iter__ print(isinstance(range(100000000),Iterator)) #驗證range執行之後得到的結果不是一個迭代器 輸出結果 False True False
迭代器的好處:
- 從容器類型中一個一個取值,會把所有的值都取到。
- 節省內存空間
迭代器並不會在內存中在占用一大塊內存 而是隨著循環每次生成一個
每一次next每次給我一個
迭代器的概念
迭代器協議---內部含有__next__和__iter__方法的就是迭代器
迭代器協議和可迭代協議
可以被for循環的都是可迭代的
可迭代的內部都有__iter__方法
只要是迭代器 一定可迭代
可迭代的.__iter__()方法就可以的到一個迭代器
迭代器中的.__next__()方法可以一個一個的獲取值
for循環實際上就是在使用迭代器
iterator 可迭代對象
直接給你內存地址
#直接給你內存地址 print([].__iter__()) 輸出結果: <list_iterator object at 0x00000148A66DF0D0> #不給你判斷是否可迭代 #猜測它為一個可迭代對象用於判斷一個數據類型是否是可迭代的,然後判斷是否能夠使用for循環 print(range(10)) 輸出結果: range(0, 10)可迭代對象是與for循環掛鉤,而迭代器是與next()函數掛鉤的
for i in l: pass ''' 執行for循環拿到的每一個值其實都是在for循環內部執行了 : 迭代器就是:iterator = l.__iter__() 然後再執行:iterator.__next__() 直到報錯的時候就自動停止了循環 '''
1、雙下方法:__iter__,__next__很少直接調用的方,一般情況下是通過其他語法觸發(for) 2、可以被for循環的都是可迭代的 3、可迭代的內部都有__iter__方法 4、只要是迭代器 一定可迭代 5、可迭代的.__iter__()方法就可以的到一個迭代器 6、迭代器中的.__next__()方法可以一個一個的獲取值 7、for循環實際上就是在使用迭代器 迭代器的特點: 1、很方便使用,且只能取所有的數據取一次 2、節省內存空間
最後感謝各位能夠看到這裡:
在魯迅一篇未發表的文章中說過:“代碼看懂了不是懂一定要自己實際操作哇這樣才能更好的理解和吸收。”
最後來一句:一個人可以在任何他懷有無限熱忱的事情上成功,讓我們一起進步吧