博主研究了很多python的代碼,發現都是無法釋放顯存的,或者說是釋放顯存不徹底。為此實現了自定義dll庫,由python調用實現了釋放顯存。支持pytorch、tensorflow、onnxruntime等cuda運行環境,其運行效果與ai框架無關,由cuda C++ API決定。其中,自定義dll庫導出給python使用可以參考vs2019導出動態鏈接庫(dll)給其他vs項目及python代碼使用_萬裡鵬程轉瞬至的博客-CSDN博客通過vs可以導出動態鏈接庫(dll文件)給其他c++項目、c#項目、python項目使用。本案例實現將vs項目導出為動態鏈接庫,給c++項目與python項目使用。涉及全局變量、函數、自定義類的導出。項目創建完成後會得到以下結構, 可以將核心代碼寫在dllmain.cpp裡面(原先的內容可以不用管),頭文件信息寫入在pch.h裡面以下內容可以全部拷貝到pch.h中(博主的代碼涉及到了cuda,所以需要配置以下cuda,cuda的配置可以參考libtorch顯存管理示例_萬裡鵬程轉瞬至的博客-CSDN博客,各 https://hpg123.blog.csdn.net/article/details/125396626
https://hpg123.blog.csdn.net/article/details/125396626
下面代碼中所用到的dll文件可以在以下鏈接下載,也可以參考上述鏈接自行實現。
python釋放cuda緩存庫-深度學習文檔類資源-CSDN下載博主自行實現的動態鏈接庫,通過python導入後可以實現釋放顯存,與ai框架無關。支持pytorch更多下載資源、學習資料請訪問CSDN下載頻道.https://download.csdn.net/download/a486259/85725926
這些要調用cuda,因此電腦需配置好cuda環境。同時,注意按照自己的實際情況修改dll文件的路徑。此外,代碼用到了pynvml進行顯存查詢,如果電腦沒有安裝請用 pip install pynvml 進行安裝。
import ctypes
import os
import pynvml
pynvml.nvmlInit()
def get_cuda_msg(tag=""):
handle = pynvml.nvmlDeviceGetHandleByIndex(0)
meminfo = pynvml.nvmlDeviceGetMemoryInfo(handle)
print(tag, ", used:",meminfo.used / 1024**2,"Mib","free:",meminfo.free / 1024**2,"Mib")
#os.environ['Path']+=r'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin'
#python3.7版本以上使用下列代碼添加依賴項dll的路徑
os.add_dll_directory(r'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin')
lib = ctypes.cdll.LoadLibrary(os.getcwd()+ "/dll_export.dll")
#win32api.FreeLibrary(libc._handle) #發現程序運行結束時無法正常退出dll,需要顯式釋放dll
#lib.reset_cuda()這裡所搭建的模型只是一個demo,沒有任何的實際意義,各位可以使用自己的模型和框架。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(6, 256, kernel_size=3, stride=1, padding=0)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0)
self.conv3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0)
self.conv4 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=0)
self.conv5 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0)
self.conv61 = nn.Conv2d(512, 3, kernel_size=3, stride=1, padding=0)
self.conv62 = nn.Conv2d(512, 3, kernel_size=3, stride=1, padding=0)
self.global_pooling = nn.AdaptiveAvgPool2d(output_size=(1, 1))
#假設x1與x2的通道數均為3
def forward(self, x1, x2):
x = torch.cat([x1, x2], dim=1)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x1= self.conv61(x)
x2= self.conv62(x)
x1 = self.global_pooling(x1).view(-1)
x2 = self.global_pooling(x2).view(-1)
x1 = F.softmax(x1,dim=0)
x2 = F.softmax(x2,dim=0)
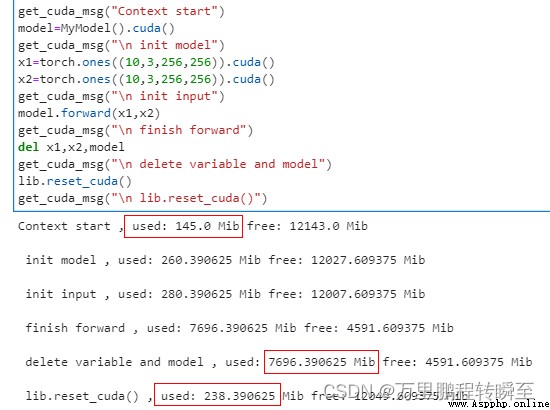
return x1,x2代碼及運行結果如下所示,包含模型初始化、變量初始化、forword後、del變化後、顯存釋放後(reset_cuda)5個狀態前後的顯存變化。可以看到調用lib.reset_cuda後顯存基本上已經恢復。
get_cuda_msg("Context start")
model=MyModel().cuda()
get_cuda_msg("\n init model")
x1=torch.ones((10,3,256,256)).cuda()
x2=torch.ones((10,3,256,256)).cuda()
get_cuda_msg("\n init input")
model.forward(x1,x2)
get_cuda_msg("\n finish forward")
del x1,x2,model
get_cuda_msg("\n delete variable and model")
lib.reset_cuda()
get_cuda_msg("\n lib.reset_cuda()")