正則表達式 (RegEx) 是一個特殊的字符序列,它使用搜索模式來查找一個字符串或一組字符串。它可以通過將文本與特定模式進行匹配來檢測文本的存在與否,還可以將模式拆分為一個或多個子模式。Python提供了一個re模塊,支持在Python中使用正則表達式。它的主要功能是提供搜索,其中它采用正則表達式和字符串。在這裡,它要麼返回第一個匹配項,要麼不返回任何匹配項。
例子:
import re
s = 'GeeksforGeeks: A computer science portal for geeks'
match = re.search(r'portal', s)
print('Start 索引位置:', match.start())
print('End 索引位置:', match.end())
輸出
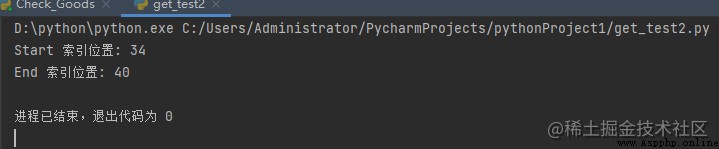
上面的代碼給出了字符串門戶的起始索引和結束索引。
注意: 這裡的r字符(r’portal’)代表原始,而不是正則表達式。原始字符串與常規字符串略有不同,它不會將 \ 字符解釋為轉義字符。這是因為正則表達式引擎使用 \ 字符來實現其自身的轉義目的。
在開始使用Python正則表達式模塊之前,讓我們看看如何使用元字符或特殊序列實際編寫正則表達式。
正則表達式是由普通字符(例如字符 a 到 z)以及特殊字符(稱為"元字符")組成的文字模式。模式描述在搜索文本時要匹配的一個或多個字符串。正則表達式作為一個模板,將某個字符模式與所搜索的字符串進行匹配。
普通字符包括沒有顯式指定為元字符的所有可打印和不可打印字符。這包括所有大寫和小寫字母、所有數字、所有標點符號和一些其他符號。
為了理解RE方法,元字符是非常有用的,重要的,並將用於模塊re的功能。以下是元字符列表。
讓我們詳細討論這些元字符中的每一個
反斜槓 \ 確保不會以特殊方式處理字符。這可以被認為是一種轉義元字符的方法。例如,如果要在字符串中搜索 dot(.),那麼您會發現 dot(.) 將被視為一個特殊字符,就像元字符之一一樣(如上表所示)。因此,對於這種情況,我們將在 dot(.) 之前使用反斜槓(\),以便它將失去其特性。請參閱下面的示例以更好地理解。
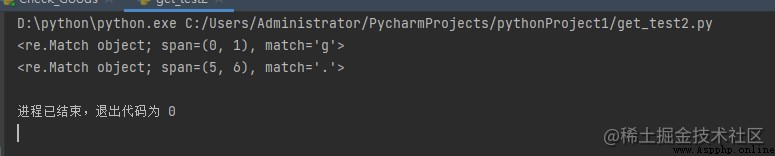
例:
import re
s = 'geeks.forgeeks'
# without using \
match = re.search(r'.', s)
print(match)
# using \
match = re.search(r'.', s)
print(match)
輸出:
[] 方括號方括號 [] 表示由我們希望匹配的一組字符組成的字符類。例如,字符類 [abc] 將匹配任何單個 a、b 或 c。
我們還可以使用方括號內的 – 指定字符范圍。例如
[0, 3] 為樣品作為[a-c] 與 [abc] 相同我們還可以使用插入符號 ^ 反轉字符類。例如
[^0-3] 表示除 0、1、2 或 3 以外的任何數字[^a-c]表示除 a、b 或 c 以外的任何字符插入記號^符號與字符串的開頭匹配,即檢查字符串是否以給定字符開頭。例如——
^g 將檢查字符串是否以 g 開頭,例如geeks, globe, girl, getc等。^ge 將檢查字符串是否以 ge 開頭,例如 geeks、geeksforgeeks 等。Dollar$ 符號與字符串的末尾匹配,即檢查字符串是否以給定字符結尾。例如——
s$ 將檢查以 geeks、ends、s 等結尾的字符串。ks$將檢查以 ks 結尾的字符串,例如 geeks、geeksforgeeks、ks 等。點. 符號僅匹配除換行符 \n 之外的單個字符。例如——
a.b將檢查在點的位置包含任何字符的字符串,例如acb,acbd,abbb等..將檢查字符串是否包含至少2個字符| 符號用作 or 運算符,這意味著它檢查字符串中是否存在 or 符號之前或之後的模式。例如——
a|b 將匹配任何包含 a 或 b 的字符串,如 acd、bcd、abcd 等。問號?檢查正則表達式中問號前面的字符串是否至少出現一次或根本不出現。例如——
ab?c 將匹配字符串 ac、acb、dabc,但不會匹配 abbc,因為有兩個 b。同樣,它不會與 abdc 匹配,因為 b 後面沒有 c。星號 * 符號匹配 * 符號前面的正則表達式的零個或多個匹配項。例如——
ab*c 將匹配字符串 ac、abc、abbbc、dabc 等,但不會匹配 abdc,因為 b 後面沒有 c。加號 + 匹配 + 符號前面的正則表達式的一個或多個匹配項。例如——
ab+c 將匹配字符串 abc、abbc、dabc,但不會匹配 ac,abdc 因為 ac 中沒有 b,而 abdc 後面沒有 c。{}匹配正則表達式之前的任何重復,從 m 到 n(包括 m 和 n)。例如——
a{2, 4} 將匹配字符串 aaab、baaaac、gaad,但不會匹配 abc、bc 等字符串,因為在這兩種情況下只有一個 a 或沒有 a。組符號用於對子模式進行分組。例如——
(a|b)cd 將匹配 acd、abcd、gacd 等字符串。特殊序列與字符串中的實際字符不匹配,而是告訴搜索字符串中必須發生匹配的特定位置。它使編寫常用模式變得更加容易。
Python有一個名為re的模塊,用於Python中的正則表達式。我們可以使用 import 語句導入此模塊。
例: 在 Python 中導入 re 模塊
importre
讓我們看看這個模塊提供的各種函數,以便在Python中使用正則表達式。
將字符串中模式的所有非重疊匹配項作為字符串列表返回。從左到右掃描字符串,並按找到的順序返回匹配項。
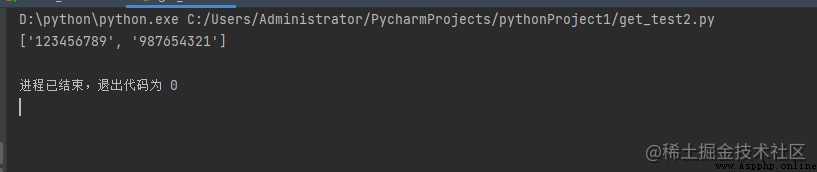
例: 查找模式的所有匹配項
# findall()
import re
# 示例文本字符串,其中正則表達式
# 已搜索。
string = """Hello my Number is 123456789 and my friend's number is 987654321"""
# 用於查找數字的示例正則表達式。
regex = '\d+'
match = re.findall(regex, string)
print(match)
輸出
正則表達式被編譯成模式對象,這些對象具有用於各種操作的方法,例如搜索模式匹配或執行字符串替換。
示例 1:
import re
# compile()創建正則表達式
# 字符類【a-e】,
# 這相當於[abcde]。
# 類[abcde]將與字符串匹配
# 'a', 'b', 'c', 'd', 'e'.
p = re.compile('[a-e]')
# findall()搜索正則表達式
# 並在找到後返回列表
print(p.findall("Aye, said Mr. Gibenson Stark"))
輸出:
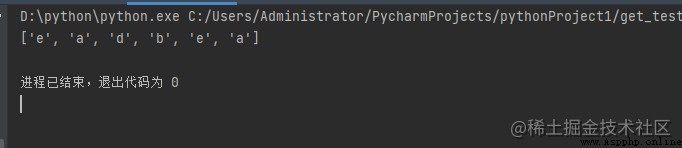
了解輸出:
按字符或模式的出現次數拆分字符串,找到該模式後,字符串中的其余字符將作為結果列表的一部分返回。
語法:
re.split(pattern, string, maxsplit=0, flags=0)
第一個參數,pattern表示正則表達式,string是給定的字符串,其中將搜索模式並進行拆分,如果未提供maxsplit,則認為maxsplit為零“0”,如果提供了任何非零值,則最多發生許多拆分。如果 maxsplit = 1,則字符串將僅拆分一次,從而生成長度為 2 的列表。標志非常有用,可以幫助縮短代碼,它們不是必需的參數,例如:flags = re。IGNORECASE,在此拆分中,大小寫,即小寫或大寫將被忽略。
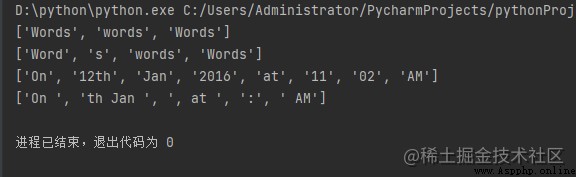
示例 1:
from re import split
# '\W+' 表示非字母數字字符
# 或查找時的字符組 ','
# 或空白' ', split(), 拆分從該點開始的字符串
print(split('\W+', 'Words, words , Words'))
print(split('\W+', "Word's words Words"))
# 這裡 ':', ' ' ,',' 因此不是字母數字,
# 發生拆分的點
print(split('\W+', 'On 12th Jan 2016, at 11:02 AM'))
# '\d+' 表示數字字符或一組
# 字符拆分發生在“12”, '2016',
# '11', '02' only
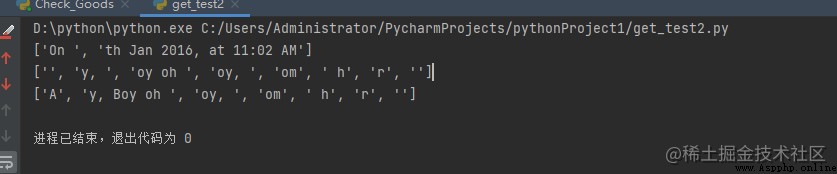
print(split('\d+', 'On 12th Jan 2016, at 11:02 AM'))
輸出:
示例 2:
import re
# 拆分只會在“12”處發生一次,返回的列表長度為2
#
print(re.split('\d+', 'On 12th Jan 2016, at 11:02 AM', 1))
# 'Boy' and 'boy' 當 flags = re.IGNORECASE 時,將被視為相同。忽略案例
print(re.split('[a-f]+', 'Aey, Boy oh boy, come here', flags=re.IGNORECASE))
print(re.split('[a-f]+', 'Aey, Boy oh boy, come here'))
輸出:
函數中的“sub”代表SubString,在給定的字符串(第3個參數)中搜索某個正則表達式模式,並在發現子字符串模式被repl(第2個參數)替換後,計數檢查並保持這種情況發生的次數。
語法:
re.sub(pattern, repl, string, count=0, flags=0)
示例 1:
import re
# 正則表達式模式“ub”匹配“Subject”和“Uber”處的字符串。視情況而定
# 已忽略,使用標記“ub”應在匹配時與字符串匹配兩次,
# “Subject”中的“ub”替換為“~*”,而“Uber”中的“ub”替換為“ub”。
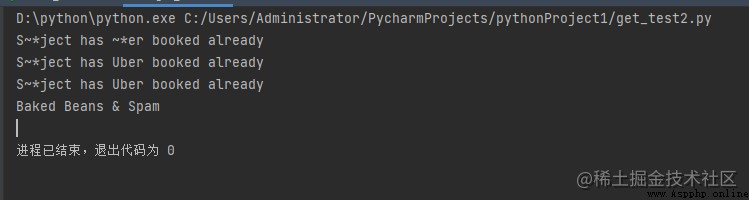
print(re.sub('ub', '~*', 'Subject has Uber booked already', flags=re.IGNORECASE))
# 考慮到區分大小寫,“Uber”中的“Ub”將不會被替換。
print(re.sub('ub', '~*', 'Subject has Uber booked already'))
# 由於count的值為1,因此發生替換的最大次數為1
print(re.sub('ub', '~*', 'Subject has Uber booked already',
count=1, flags=re.IGNORECASE))
# 模式前的“r”表示RE,\s表示字符串的開始和結束。
print(re.sub(r'\sAND\s', ' & ', 'Baked Beans And Spam',
flags=re.IGNORECASE))
輸出
subn() 在所有方面都與 sub() 相似,除了提供輸出的方式。它返回一個元組,其中包含替換和新字符串的總數,而不僅僅是字符串。
語法:
re.subn(pattern, repl, string, count=0, flags=0)
例:
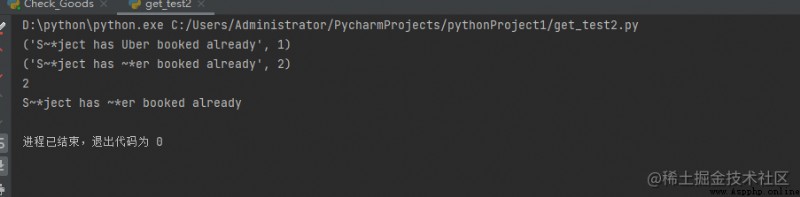
import re
print(re.subn('ub', '~*', 'Subject has Uber booked already'))
t = re.subn('ub', '~*', 'Subject has Uber booked already',
flags=re.IGNORECASE)
print(t)
print(len(t))
# 這將提供與sub()相同的輸出
print(t[0])
輸出
返回所有非字母數字反斜槓的字符串,如果要匹配可能包含正則表達式元字符的任意文本字符串,這將非常有用。
語法:
re.escape(string)
例:
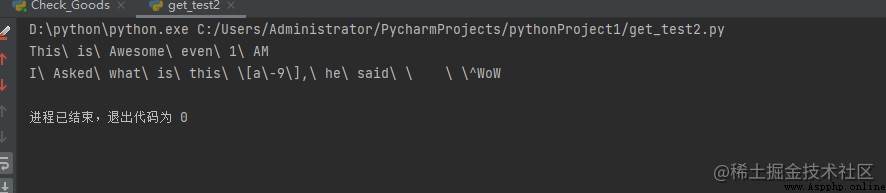
import re
# escape()返回在每個非字母數字字符之前帶有反斜槓“\”的字符串
# 僅在第一種情況下為“”,在第二種情況下為非字母數字“”,插入符號“^”、“-”、“[]”、“\”
# 不是字母數字
print(re.escape("This is Awesome even 1 AM"))
print(re.escape("I Asked what is this [a-9], he said \t ^WoW"))
輸出
此方法返回 None(如果模式不匹配),或返回 re。匹配對象包含有關字符串的匹配部分的信息。此方法在第一次匹配後停止,因此這最適合測試正則表達式而不是提取數據。
例: 搜索模式的出現次數
import re
# 讓我們使用正則表達式匹配日期字符串,格式為月份名稱後跟天數
regex = r"([a-zA-Z]+) (\d+)"
match = re.search(regex, "I was born on June 24")
if match != None:
# 當表達式“([a-zA-Z]+)(\d+)與日期字符串匹配時,我們到達這裡。
# 這將打印[14,21],因為它在索引14處匹配,在21處結束。
print("Match at index %s, %s" % (match.start(), match.end()))
# 我們使用group()方法獲取所有匹配項
# 捕獲的組。這些組包含匹配的值。
# 特別是:
# 匹配。group(0)始終返回完全匹配的字符串
# 匹配。group(1)匹配。group(2)。。。返回捕獲
# 在輸入字符串中按從左到右的順序分組
# 匹配。group()等效於match。組(0)
# 所以這將打印“6月24日”
print("Full match: %s" % (match.group(0)))
# 所以這將打印“June”
print("Month: %s" % (match.group(1)))
# 所以這將打印 "24"
print("Day: %s" % (match.group(2)))
else:
print("The regex pattern does not match.")
輸出
Match 對象包含有關搜索和結果的所有信息,如果未找到匹配項,則將返回 None。讓我們看一下 match 對象的一些常用方法和屬性。
match.re 屬性返回傳遞的正則表達式,match.string 屬性返回傳遞的字符串。
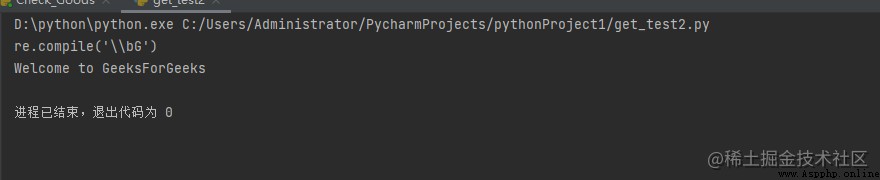
例: 獲取匹配對象的字符串和正則表達式
import re
s = "Welcome to GeeksForGeeks"
# 這裡x是匹配對象
res = re.search(r"\bG", s)
print(res.re)
print(res.string)
輸出
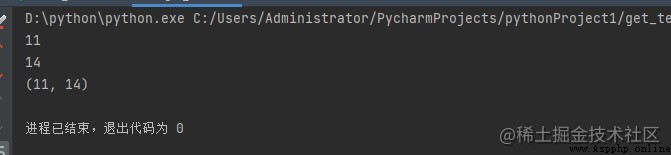
例: 獲取匹配對象的索引
import re
s = "Welcome to GeeksForGeeks"
# 這裡x是匹配對象
res = re.search(r"\bGee", s)
print(res.start())
print(res.end())
print(res.span())
輸出
group() 方法返回模式匹配的字符串部分。請參閱下面的示例以更好地理解。
例: 獲取匹配的子字符串
import re
s = "Welcome to GeeksForGeeks"
# 這裡x是匹配對象
res = re.search(r"\D{2} t", s)
print(res.group())
輸出

https://docs.python.org/2/library/re.html