Consider using the following procedure to understand this concept :
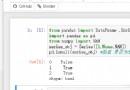
import multiprocessing
# Empty list with global scope
result = []
def square_list(mylist):
""" Function to square a given list """
global result
# take mylist The block of is attached to the global list result
for num in mylist:
result.append(num * num)
# Print global list results
print("Result(in process p1): {}".format(result))
if __name__ == "__main__":
# Input list
mylist = [1, 2, 3, 4]
# Create a new process
p1 = multiprocessing.Process(target=square_list, args=(mylist,))
# Start the process
p1.start()
# Wait for the process to complete
p1.join()
# Print the global results list
print("Result(in main program): {}".format(result))
Here is the output
Result(in process p1): [1, 4, 9, 16]
Result(in main program): []
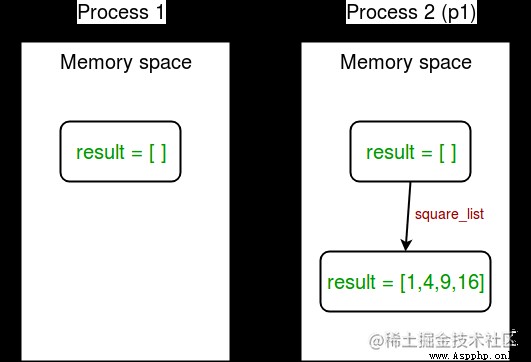
In the example above , We try to print the global list in two places result The content of :
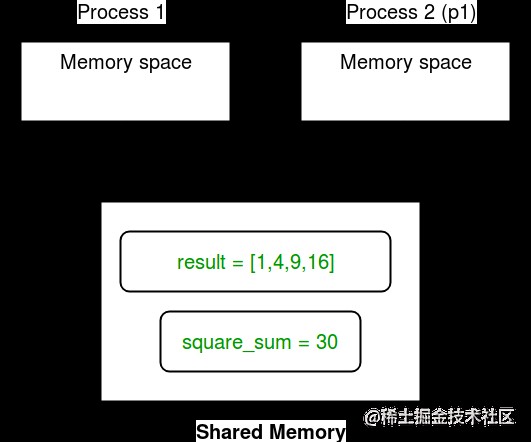
The following figure shows this concept :
Shared memory : Multi process Module supply Array and value Object to share data between processes .
Here is a simple example , Shows the use of Array and Value Sharing data between processes .
import multiprocessing
def square_list(mylist, result, square_sum):
""" Function to square a given list """
# take mylist To the result array
for idx, num in enumerate(mylist):
result[idx] = num * num
# Sum of squares
square_sum.value = sum(result)
# Print result array
print("Result(in process p1): {}".format(result[:]))
# Print square_sum value
print("Sum of squares(in process p1): {}".format(square_sum.value))
if __name__ == "__main__":
# Input list
mylist = [1, 2, 3, 4]
# establish int An array of data types , Among them is 4 An integer space
result = multiprocessing.Array('i', 4)
# establish int Value of data type
square_sum = multiprocessing.Value('i')
# Create a new process
p1 = multiprocessing.Process(target=square_list, args=(mylist, result, square_sum))
# Starting process
p1.start()
# Wait for the process to complete
p1.join()
# Print result array
print("Result(in main program): {}".format(result[:]))
# Print square_sum value
print("Sum of squares(in main program): {}".format(square_sum.value))
Running results :
Result(in process p1): [1, 4, 9, 16]
Sum of squares(in process p1): 30
Result(in main program): [1, 4, 9, 16]
Sum of squares(in main program): 30
Let's try to understand the above code line by line :
First , Let's create an array result , As shown below :
result = multiprocessing.Array('i', 4)
Again , We create a value square_sum As shown below :
square_sum = multiprocessing.Value('i')
ad locum , We just need to specify the data type . This value can give an initial value ( for example 10), As shown below :
square_sum = multiprocessing.Value('i', 10)
secondly , We're creating Process Object will be result and square_sum Pass as a parameter .
p1 = multiprocessing.Process(target=square_list, args=(mylist, result, square_sum))
By specifying the index of the array element , by result The array element specifies a value .
for idx, num in enumerate(mylist):
result[idx] = num * num
square_sum By using it value Attribute to assign value :
square_sum.value = sum(result)
For printing result Array elements , We use result[:] To print the complete array .
print("Result(in process p1): {}".format(result[:]))
square_sum Values are simply printed as :
print("Sum of squares(in process p1): {}".format(square_sum.value))
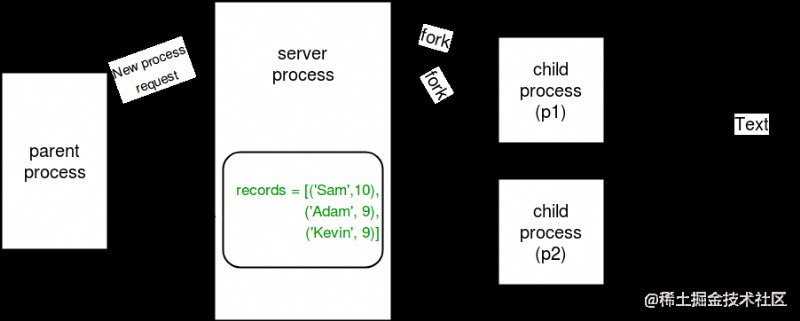
The following figure describes how processes share Array and value object :
Server process : whenever python Program startup , Server process It will also start . From then on , Whenever a new process is needed , The parent process will then connect to the server and ask it to fork over the new process .
Server process It can be saved Python object , And allow other processes to manipulate them using proxies .
Deal with more modular Provides a Manager class , Used to control server processes . therefore , Managers provide a way to create data that can be shared between different processes .
The server process manager uses Shared memory Objects are more flexible , Because they can support any object type , As listing 、 Dictionaries 、 queue 、 value 、 Array etc. . Besides , A single manager can be shared by processes on different computers on the network . however , They are slower than using shared memory .
Consider the example given below :
import multiprocessing
def print_records(records):
""" For printing records ( list ) Records in ( Tuples ) Function of """
for record in records:
print("Name: {0}\nScore: {1}\n".format(record[0], record[1]))
def insert_record(record, records):
""" To record ( list ) Add new record function """
records.append(record)
print(" New record added !\n")
if __name__ == '__main__':
with multiprocessing.Manager() as manager:
# Create a list in the server process memory
records = manager.list([('Sam', 10), ('Adam', 9), ('Kevin', 9)])
# New record to insert into the record
new_record = ('Jeff', 8)
# Create a new process
p1 = multiprocessing.Process(target=insert_record, args=(new_record, records))
p2 = multiprocessing.Process(target=print_records, args=(records,))
# Run the process p1 To insert a new record
p1.start()
p1.join()
# Run the process p2 To print records
p2.start()
p2.join()
Run output :
New record added !
Name: Sam
Score: 10
Name: Adam
Score: 9
Name: Kevin
Score: 9
Name: Jeff
Score: 8
Process ended , The exit code is 0
Let's try to understand the above code snippet :
First , We use the following command to create a Manager object :
with multiprocessing.Manager() as manager:
with Sentence block All lines under are in manager Object .
then , We use the following command in Server process Create a list in memory Record :
records = manager.list([('Sam', 10), ('Adam', 9), ('Kevin',9)])
Again , You can create a dictionary as manager.dict Method .
Server process The concept of is shown in the figure below :
Effective use of multiple processes often requires some communication between them , So that you can divide the work and aggregate the results .
Deal with more Support two types of communication channels between processes :
queue : A simple way to communicate between a process and multiprocessing is to use queues to pass messages back and forth . whatever Python Objects can be queued .
Be careful : Deal with more . queue Class is an approximate clone of a queue . queue .
Refer to the example program given below :
import multiprocessing
def square_list(mylist, q):
""" Function to square a given list """
# take mylist The block of is attached to the queue
for num in mylist:
q.put(num * num)
def print_queue(q):
""" Functions that print queue elements """
print(" Queue element :")
while not q.empty():
print(q.get())
print(" The queue is now empty !")
if __name__ == "__main__":
# Input list
mylist = [1, 2, 3, 4]
# Create a multi process queue
q = multiprocessing.Queue()
# Create a new process
p1 = multiprocessing.Process(target=square_list, args=(mylist, q))
p2 = multiprocessing.Process(target=print_queue, args=(q,))
# Process p1 Run to list
p1.start()
p1.join()
# Run the process p2 To get the queue elements
p2.start()
p2.join()
Running results :
Let's try to understand the above code step by step :
First , We use the following command to create a Multiprocessing queue :
q = multiprocessing.Queue()
then , We pass the process p1 Empty the queue q Pass to square_list function . Use put Method to insert an element into the queue .
q.put(num * num)
To print queue elements , We use get Method , Until the queue is not empty .
while not q.empty():
print(q.get())
Here is a simple chart , Describes the operations on the queue :
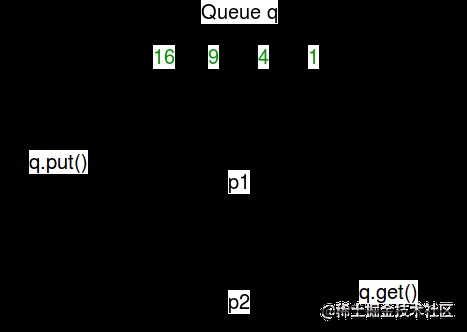
The Conduit : A pipe can only have two endpoints . therefore , When only two-way communication is required , It takes precedence over queues .
Deal with more Module supply Pipe() function , This function returns a pair of connection objects connected by a pipe .Pipe() The two connection objects returned represent both ends of the pipe . Each connection object has one send() and recv() Method ( And other methods ).
Consider the procedure given below :
import multiprocessing
def sender(conn, msgs):
""" A function used to send a message to the other end of the pipeline """
for msg in msgs:
conn.send(msg)
print(" Message sent : {}".format(msg))
conn.close()
def receiver(conn):
""" A function for printing messages received from the other end of the pipeline """
while 1:
msg = conn.recv()
if msg == "END":
break
print(" Received a message : {}".format(msg))
if __name__ == "__main__":
# Message to send
msgs = ["hello", "hey", "hru?", "END"]
# Create pipes
parent_conn, child_conn = multiprocessing.Pipe()
# Create a new process
p1 = multiprocessing.Process(target=sender, args=(parent_conn, msgs))
p2 = multiprocessing.Process(target=receiver, args=(child_conn,))
# Running process
p1.start()
p2.start()
# Wait for the process to complete
p1.join()
p2.join()
Running results :
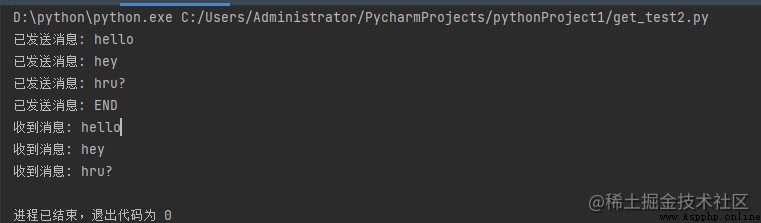
Let's try to understand the code above :
Pipes are created using the following methods :
parent_conn, child_conn = multiprocessing.Pipe()
This function returns two connection objects for both ends of the pipe .
message send Method is sent from one end of the pipe to another End .
conn.send(msg)
To receive any message at one end of the pipeline , We use recv Method .
msg = conn.recv()
In the above procedure , We send the message list from one end to the other . On the other end , We read the news , Until receipt “END” news .
Consider the image below , It shows the relationship between black and white pipes and processes :
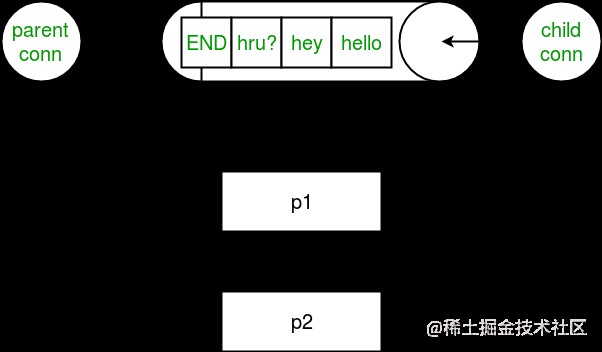
Be careful : If two processes ( Or thread ) Try to read or write to the same end of the pipe at the same time , The data in the pipeline may be corrupted . Of course , There is no risk of damage to processes that use different ends of the pipeline at the same time . Attention, please. , Queues perform appropriate synchronization between processes , But the price is added complexity . therefore , Queues are considered thread and process safe !