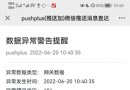
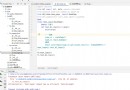
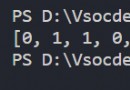
import mysql.connector
import pymysql
from pyspider.result import ResultWorker
class crawlerdb:
conn = None
cursor = None
def __init__(self):
self.conn = pymysql.connect("127.0.0.1", "root", "12345678", "crawler")
self.cursor = self.conn.cursor()
def insert(self, _result):
sql = "insert into info(title,body,editorial,ctime) VALUES('{}','{}','{}','{}')"
try:
sql = sql.format(pymysql.escape_string(_result.get('title')), pymysql.escape_string(_result.get('body')), _result.get('editorial'),_result.get('ctime'))
self.cursor.execute(sql)
self.conn.commit()
return True
except mysql.connector.Error:
print(' Insert the failure ')
return Falseimport re
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=5 * 60)
def on_start(self):
self.crawl('http://www.chinashina.com/rexinwen/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match(".*list_32_\d+\.html", each.attr.href, re.U):
self.crawl(each.attr.href, callback=self.list_page)
# Crawl the first page
self.crawl(" http://www.chinashina.com/rexinwen/list_32_1.html", callback=self.list_page)
@config(age=10 * 24 * 60 * 60)
def list_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match(".*plus/view.php\?aid=\d+", each.attr.href, re.U):
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
other = response.doc('html > body > .clearfix > .main_lt > div > .news_about > p').text()
source = other.split('\xa0\xa0\xa0\xa0\xa0')
ctime = source[2].replace(' Time :', '')
editorial = source[0].split(":")[-1].strip()
return {
"title": response.doc('.news_title').text(),
"ctime": ctime,
"editorial": editorial,
"body": response.doc('html > body > .clearfix > .main_lt > div > .news_txt').text()
}
def on_result(self,result):
if not result:
return
sql = crawlerdb()
sql.insert(result)