When I found out how to Python When performing text to speech conversion in , I want to know how to apply it to a useful research case . then , I remember I often visit Wikipedia page , These pages cover topics that interest me , But it contains a lot of text that I don't want to read completely . I would rather listen to the content of those pages while doing other things .
therefore , I decided to use Python take Wikipedia Convert pages to audio files .
Let's start by importing useful packages for this task . The library I'm going to use is for fetching parts bs4 and requests , For regular expressions re , And for text to speech pyttsx3 .
from bs4 import BeautifulSoup
import requests
import re
import pyttsx3 as tts
For grab section , We just need to define one URL And retrieve the text from the corresponding web page .
url = "https://en.wikipedia.org/wiki/Wikipedia" #the web page you want to scrape
# Collecting data from the web page
r = requests.get(url)
data = r.text
soup = BeautifulSoup(data, "lxml")
We want to keep only the text . therefore , We only look for paragraph elements .
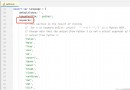
paragraphs = soup.findAll("p")
If you print variable paragraphs , You will see a list , This includes the use of variable URL All paragraph elements in the visited web page .
When we convert text to speech