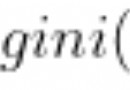The origin of coding : Computers can only calculate and recognize binary , The computer must recognize words , To interact with computers , We can also communicate with each other through computers . thus , With ASCII The birth of coding , It starts with 50 Late S , stay 1967 The final decision of , It was the original American national standard , For different computers to communicate with each other as a common compliance of the western character coding standards .
ASCII code : The maximum range of decimal digits that an eight bit binary can represent is ,0000 0000 ~ 1111 1111 = 0 ~ 255 , altogether 256 There are two different numbers .ASCII Coding is to use common English characters and symbols , And 256 A corresponding table formed by corresponding numbers one by one . Because computers are invented by Americans , therefore , At the very beginning 127 One letter is encoded into the computer , That is to say, the English letters in upper and lower case 、 Numbers and symbols , This code table is called ASCII code ; Then it expanded 128 individual , Called extension ASCII code . for example : Decimal system 33 Corresponding exclamation point !,65 Corresponding to upper case A,83 Corresponding to upper case S,97 Corresponding lowercase a, So we enter the characters , The computer converts to decimal , Then convert to binary , It can be calculated or transmitted by computer .
byte : Both Chinese and English need punctuation to clarify the meaning , Binary is the same . A string of binary numbers , There is no beginning or end , Is unable to accurately identify the conversion to decimal , So as to find the corresponding character corresponding to the code .
Evolution of coding set :
Because computers are invented by Americans , therefore , At the very beginning 127 Characters are encoded into the computer , That is to say, the English letters in upper and lower case 、 Numbers and symbols , This code table is called ASCII code , Like capital letters A The code of is 65, Lowercase letters z The code of is 122. But to deal with Chinese, obviously one byte is not enough , At least two bytes required , And not with ASCII Encoding conflict , therefore , China made GB2312 code , It's used to compile Chinese . What you can think of is , There are hundreds of languages all over the world , Japan compiles Japanese into Shift_ _JIS in , South Korea compiles Korean into Euc-kr in , Every country has its own standards , There will inevitably be conflicts , The result is , In a mixed language text , There's going to be a mess . therefore ,Unicode emerge as the times require .Unicode Unify all languages into - Nested code , So there won't be any more confusion .Unicode Standards are evolving , But the most common is to use two bytes to represent a character ( If you want to use very remote characters , Need 4 Bytes ). Modern operating systems and most programming languages directly support Unicode.
Change Chinese characters into Unicode code
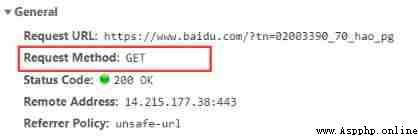
eg: Search Baidu for the seal of Yiguan , its url The address is https://www.baidu.com/s?wd=%E6%98%93%E7%83%8A%E5%8D%83%E7%8E%BA, And the parameter Yiyang Qianxi Unicode The encoding is %E6%98%93%E7%83%8A%E5%8D%83%E7%8E%BA. If you crawl the source code of the web page in Chinese , An error will be reported as shown in the figure below :
and urllib.parse.quote() The method is designed to solve this problem .
The grammar is as follows :
urllib.parse.quote(string, safe=’/’, encoding=None, errors=None)
example :
import urllib.request
import urllib.parse
# https://www.baidu.com/s?wd=%E6%98%93%E7%83%8A%E5%8D%83%E7%8E%BA
url = 'https://www.baidu.com/s?wd='
name = urllib.parse.quote(' Jackson Yi ')
print(name)
Running results :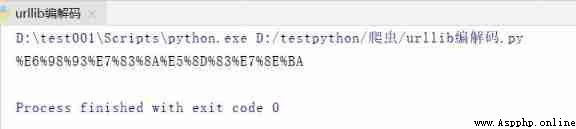
It can be seen here that Chinese characters have been transformed into Unicode Coding format !
Let's take an example ( Get the web source code of Baidu search Yiyang Qianxi ):
import urllib.request
import urllib.parse
# https://www.baidu.com/s?wd=%E6%98%93%E7%83%8A%E5%8D%83%E7%8E%BA
url = 'https://www.baidu.com/s?wd='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3880.400 QQBrowser/10.8.4554.400'
} # obtain ua identification
# Change Yiyang Qianxi into Unicode Coding form .
name = urllib.parse.quote(' Jackson Yi ')
# Merge url
url = url + name
# Custom request object
request = urllib.request.Request(url = url , headers = headers)
# Simulate the browser to send a request to the server
response = urllib.request.urlopen(request)
# Get response content
content = response.read().decode('utf-8')
# Print data
print(content)
Running results :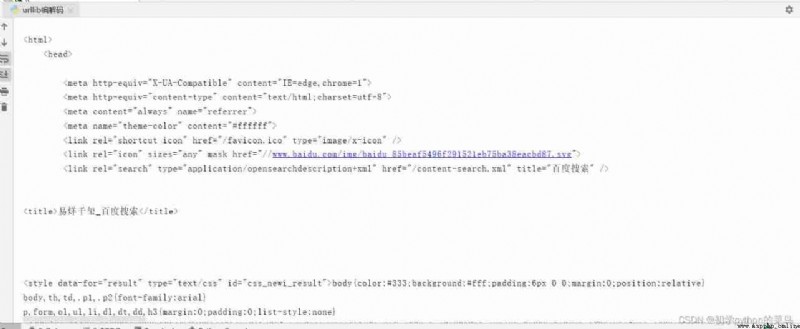
In order to solve the problem more conveniently and quickly url The problem of multiple parameters in .urllib.parse.urlencode() You can combine the data in the dictionary with the connector of , And convert to Unicode Coding format .
for example :
import urllib.parse
# https://www.baidu.com/s?wd=%E6%98%93%E7%83%8A%E5%8D%83%E7%8E%BA&sex=%E7%94%B7
url = 'https://www.baidu.com/s?wd= Jackson Yi &sex= male '
data = {
'wd':' Jackson Yi ',
'sex':' male '
}
a = urllib.parse.urlencode(data)
print(a)
Running results :
Let's look at an example ( Crawl to Baidu to search Yiyang Qianxi (wd=“ Jackson Yi ”&sex=“ male ”)):
import urllib.request
import urllib.parse
# https://www.baidu.com/s?wd=%E6%98%93%E7%83%8A%E5%8D%83%E7%8E%BA&sex=%E7%94%B7
url = 'https://www.baidu.com/s?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3880.400 QQBrowser/10.8.4554.400'
}
data = {
'wd':' Jackson Yi ',
'sex':' male '
}
a = urllib.parse.urlencode(data)
url = url + a
# Custom request object
request = urllib.request.Request(url = url , headers = headers)
# Simulate the browser to send a request to the server
response = urllib.request.urlopen(request)
# Get response data
content = response.read().decode('utf8')
# Print data
print(content)
Running results :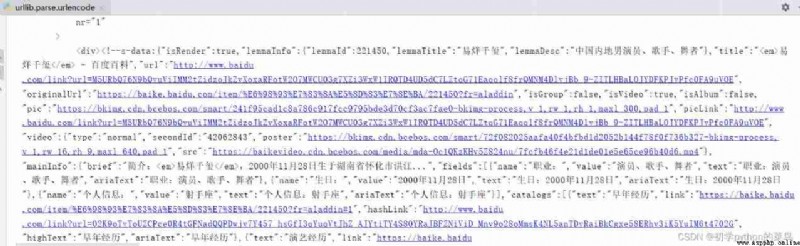
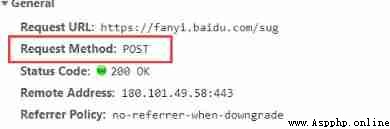
matters needing attention :
post The request requires a byte type , Be sure to code .
After encoding, you must call encode Method
Parameters are placed in the method customized by the request object
# post The requested parameters must be encoded
data = urllib.parse.urlencode(data).encode('utf8')
example 1( Baidu translation ):
import urllib.request
import urllib.parse
import json
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3880.400 QQBrowser/10.8.4554.400'
}
data = {
'kw':'spider'
}
# post The requested parameters must be encoded
data = urllib.parse.urlencode(data).encode('utf-8')
# post The request parameters of are not spliced in url hinder , Instead, it is placed in the parameters of the request object
request = urllib.request.Request(url = url ,data = data ,headers = headers)
# Simulate the browser to send a request to the server
response = urllib.request.urlopen(request)
content = response.read().decode('utf8')
# Convert the string to json type
obj = json.loads(content)
print(obj)
Running results :

example 2( Detailed translation of Baidu translation ):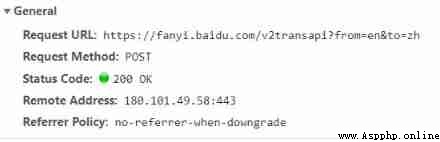
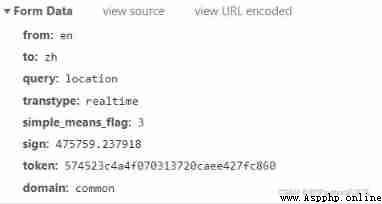
Here we can see the case 1 And cases 2 The gap between the two , Here we will learn The second anti - Crawler strategy .(Cookie Anti creeping )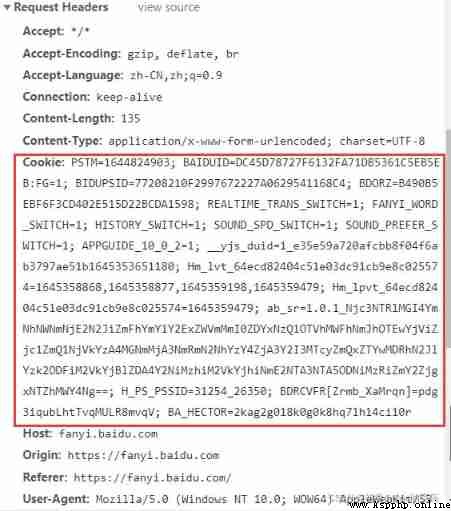
The code is as follows :
import urllib.request
import urllib.parse
import json
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
headers = {
'Cookie': 'PSTM=1644824903; BAIDUID=DC45D78727F6132FA71DB5361C5EB5EB:FG=1; BIDUPSID=77208210F2997672227A0629541168C4; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; APPGUIDE_10_0_2=1; __yjs_duid=1_e35e59a720afcbb8f04f6ab3797ae51b1645353651180; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1645358868,1645358877,1645359198,1645359479; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1645359479; ab_sr=1.0.1_Njc3NTRlMGI4YmNhNWNmNjE2N2JiZmFhYmY1Y2ExZWVmMmI0ZDYxNzQ1OTVhMWFhNmJhOTEwYjViZjc1ZmQ1NjVkYzA4MGNmMjA3NmRmN2NhYzY4ZjA3Y2I3MTcyZmQxZTYwMDRhN2JlYzk2ODFiM2VkYjBlZDA4Y2NiMzhiM2VkYjhiNmE2NTA3NTA5ODNiMzRiZmY2ZjgxNTZhMWY4Ng==; H_PS_PSSID=31254_26350; BDRCVFR[Zrmb_XaMrqn]=pdg3iqubLhtTvqMULR8mvqV; BA_HECTOR=2kag2g018k0g0k8hq71h14ci10r'
}
data = {
'from': 'en',
'to': 'zh',
'query': 'location',
'transtype': 'realtime',
'simple_means_flag': '3',
'sign': '475759.237918',
'token': '574523c4a4f070313720caee427fc860',
'domain': 'common'
}
data = urllib.parse.urlencode(data).encode('utf-8')
# Custom request object
request = urllib.request.Request(url = url ,data = data ,headers = headers)
# Simulate the browser to send a request to the server
response = urllib.request.urlopen(request)
# Return response data
content = response.read().decode('utf-8')
# Convert the string type to json type
obj = json.loads(content)
print(obj)
Running results :
That's all get Request and post The entire content of the request . There are any deficiencies that can be mentioned in the comments section , I hope you can pay more attention to me , Looking forward to the follow-up !!