When we learn about machine learning , Generally, we do not need to crawl the data by ourselves , Because a lot of algorithm learning is very friendly to help us pack the relevant data , But this does not mean that we do not need to learn and understand the relevant knowledge . Here we learn about three kinds of data crawling : flower / Crawling of star images 、 Crawling of Chinese artist images 、 Crawling of stock data . Learn and use three kinds of reptiles .
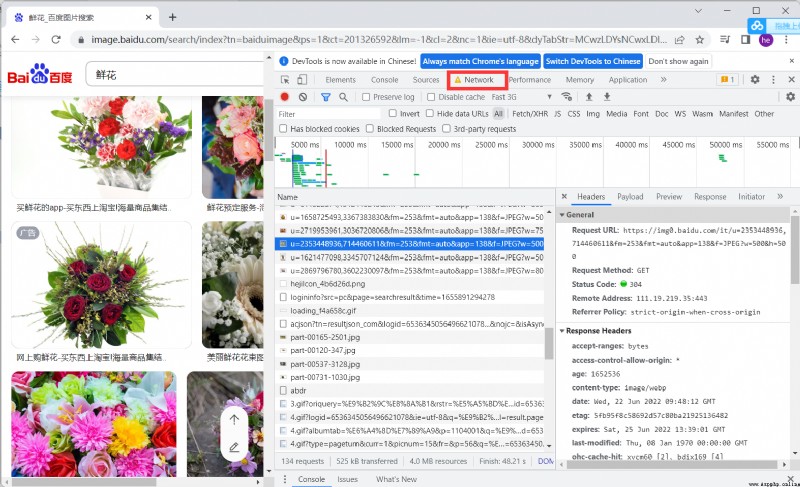
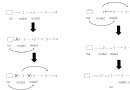
Find the packet for analysis , Analyze important parameters 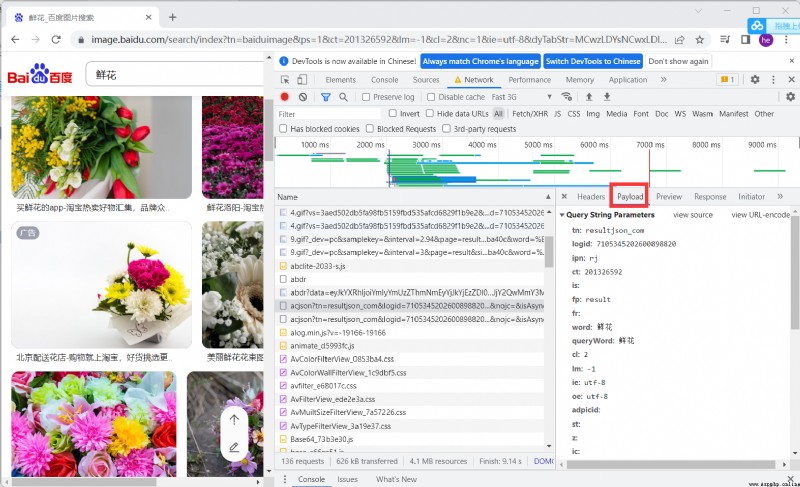
View the return value for analysis , You can see the picture system in ThumbURL in 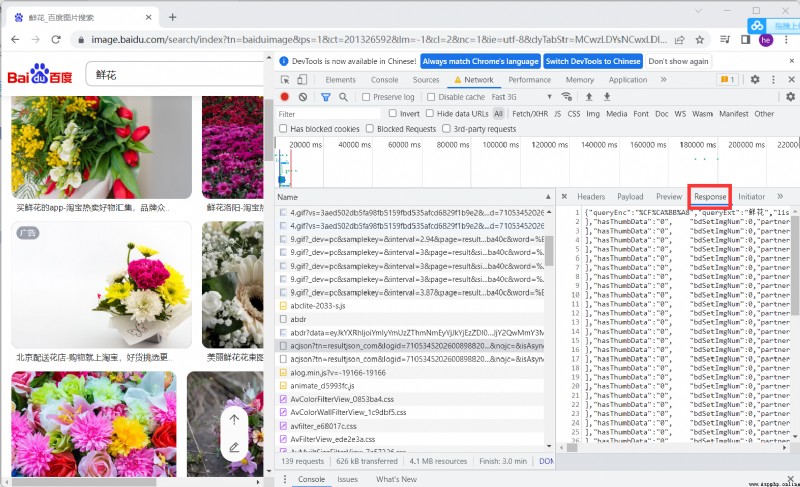
http://image.baidu.com/search/acjson? Baidu picture address
Splicing tn Visit to get the... Of each picture URL, In the return data of thumbURL in
https://image.baidu.com/search/acjson?+tn
To separate pictures URL Then visit download
import requests
import os
import urllib
class GetImage():
def __init__(self,keyword=' flower ',paginator=1):
self.url = 'http://image.baidu.com/search/acjson?'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
self.keyword = keyword
self.paginator = paginator
def get_param(self):
keyword = urllib.parse.quote(self.keyword)
params = []
for i in range(1,self.paginator+1):
params.append(
'tn=resultjson_com&logid=10338332981203604364&ipn=rj&ct=201326592&is=&fp=result&fr=&word={}&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&expermode=&nojc=&isAsync=&pn={}&rn=30&gsm=78&1650241802208='.format(keyword,keyword,30*i)
)
return params
def get_urls(self,params):
urls = []
for param in params:
urls.append(self.url+param)
return urls
def get_image_url(self,urls):
image_url = []
for url in urls:
json_data = requests.get(url,headers = self.headers).json()
json_data = json_data.get('data')
for i in json_data:
if i:
image_url.append(i.get('thumbURL'))
return image_url
def get_image(self,image_url):
## According to the picture url, Save picture
file_name = os.path.join("", self.keyword)
#print(file_name)
if not os.path.exists(file_name):
os.makedirs(file_name)
for index,url in enumerate(image_url,start=1):
with open(file_name+'/{}.jpg'.format(index),'wb') as f:
f.write(requests.get(url,headers=self.headers).content)
if index != 0 and index%30 == 0:
print(" The first {} Page download complete ".format(index/30))
def __call__(self, *args, **kwargs):
params = self.get_param()
urls = self.get_urls(params)
image_url = self.get_image_url(urls)
self.get_image(image_url=image_url)
if __name__ == '__main__':
spider = GetImage(' flower ',3)
spider()
if __name__ == '__main__':
spider = GetImage(' star ',3)
spider()
if __name__ == '__main__':
spider = GetImage(' Comic ',3)
spider()
import requests
import json
import os
import urllib
def getPicinfo(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0',
}
response = requests.get(url,headers)
if response.status_code == 200:
return response.text
return None
Download_dir = 'picture'
if os.path.exists(Download_dir) == False:
os.mkdir(Download_dir)
pn_num = 1
rn_num = 10
for k in range(pn_num):
url = "https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28266&from_mid=500&format=json&ie=utf-8&oe=utf-8&query=%E4%B8%AD%E5%9B%BD%E8%89%BA%E4%BA%BA&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn="+str(pn_num)+"&rn="+str(rn_num)+"&_=1580457480665"
res = getPicinfo(url)
json_str = json.loads(res)
figs = json_str['data'][0]['result']
for i in figs:
name = i['ename']
img_url = i['pic_4n_78']
img_res = requests.get(img_url)
if img_res.status_code == 200:
ext_str_splits = img_res.headers['Content-Type'].split('/')
ext = ext_str_splits[-1]
fname = name+'.'+ext
open(os.path.join(Download_dir,fname),'wb').write(img_res.content)
print(name,img_url,'saved')
We are right. http://quote.eastmoney.com/center/gridlist.html Crawling through stock data in , And store the data
# http://quote.eastmoney.com/center/gridlist.html
import requests
from fake_useragent import UserAgent
import json
import csv
import urllib.request as r
import threading
def getHtml(url):
r = requests.get(url, headers={
'User-Agent': UserAgent().random,
})
r.encoding = r.apparent_encoding
return r.text
# How much to climb
num = 20
stockUrl = 'http://52.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409623798991171317_1654957180928&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1654957180938'
if __name__ == '__main__':
responseText = getHtml(stockUrl)
jsonText = responseText.split("(")[1].split(")")[0];
resJson = json.loads(jsonText)
datas = resJson['data']['diff']
dataList = []
for data in datas:
row = [data['f12'],data['f14']]
dataList.append(row)
print(dataList)
f = open('stock.csv', 'w+', encoding='utf-8', newline="")
writer = csv.writer(f)
writer.writerow((" Code "," name "))
for data in dataList:
writer.writerow((data[0]+"\t",data[1]+"\t"))
f.close()
def getStockList():
stockList = []
f = open('stock.csv', 'r', encoding='utf-8')
f.seek(0)
reader = csv.reader(f)
for item in reader:
stockList.append(item)
f.close()
return stockList
def downloadFile(url,filepath):
try:
r.urlretrieve(url,filepath)
except Exception as e:
print(e)
print(filepath,"is downLoaded")
pass
sem = threading.Semaphore(1)
def dowmloadFileSem(url,filepath):
with sem:
downloadFile(url,filepath)
urlStart = 'http://quotes.money.163.com/service/chddata.html?code='
urlEnd = '&end=20210221&fields=TCLOSW;HIGH;TOPEN;LCLOSE;CHG;PCHG;VOTURNOVER;VATURNOVER'
if __name__ == '__main__':
stockList = getStockList()
stockList.pop(0)
print(stockList)
for s in stockList:
scode = str(s[0].split("\t")[0])
url = urlStart+("0" if scode.startswith('6') else '1')+ scode + urlEnd
print(url)
filepath = (str(s[1].split("\t")[0])+"_"+scode)+".csv"
threading.Thread(target=dowmloadFileSem,args=(url,filepath)).start()
It is possible that the data crawled at that time is dirty data , Running the following code may not run through , Do you need to process the data yourself or other methods
## Mainly used matplotlib Do image rendering
import pandas as pd
import matplotlib.pyplot as plt
import csv
import Stock data crawling as gp
plt.rcParams['font.sans-serif'] = ['simhei'] # Specified font
plt.rcParams['axes.unicode_minus'] = False # Show - Number
plt.rcParams['figure.dpi'] = 100 # Dots per inch
files = []
def read_file(file_name):
data = pd.read_csv(file_name,encoding='gbk')
col_name = data.columns.values
return data,col_name
def get_file_path():
stock_list = gp.getStockList()
paths = []
for stock in stock_list[1:]:
p = stock[1].strip()+"_"+stock[0].strip()+".csv"
print(p)
data,_=read_file(p)
if len(data)>1:
files.append(p)
print(p)
get_file_path()
print(files)
def get_diff(file_name):
data,col_name = read_file(file_name)
index = len(data[' date '])-1
sep = index//15
plt.figure(figsize=(15,17))
x = data[' date '].values.tolist()
x.reverse()
xticks = list(range(0,len(x),sep))
xlabels = [x[i] for i in xticks]
xticks.append(len(x))
y1 = [float(c) if c!='None' else 0 for c in data[' Up and down '].values.tolist()]
y2 = [float(c) if c != 'None' else 0 for c in data[' applies '].values.tolist()]
y1.reverse()
y2.reverse()
ax1 = plt.subplot(211)
plt.plot(range(1,len(x)+1),y1,c='r')
plt.title('{}- Up and down / applies '.format(file_name.split('_')[0]),fontsize = 20)
ax1.set_xticks(xticks)
ax1.set_xticklabels(xlabels,rotation = 40)
plt.ylabel(' Up and down ')
ax2 = plt.subplot(212)
plt.plot(range(1, len(x) + 1), y1, c='g')
#plt.title('{}- Up and down / applies '.format(file_name.splir('_')[0]), fontsize=20)
ax2.set_xticks(xticks)
ax2.set_xticklabels(xlabels, rotation=40)
plt.xlabel(' date ')
plt.ylabel(' Up and down ')
plt.show()
print(len(files))
for file in files:
get_diff(file)
The above describes three cases of data crawling , Different data crawls require us to perform different tasks URL To get , Input different parameters ,URL How to combine 、 How to get 、 This is the difficulty of data crawling , It needs some experience and foundation .
Spider-01- Introduction to reptiles Python Reptiles don't have a lot of knowledge , But you need to deal with the web all the time , Every page is different , So there are some requirements for strain capacity Reptile preparation Reference material Master Python The crawler frame Scrap ...
Since many people want to learn Python Reptiles , There is no easy tutorial , I will be in CSDN Share with you Python Crawler's study notes , Irregular update Basic requirements Python Basic knowledge of Python Basic knowledge of , You can go to the rookie tutorial ...
Python Crawler programming solutions to common problems : 1. Common solutions : [ Hold down Ctrl The key is not loose ], Click with the mouse at the same time [ Method name ], To view the document 2.TypeError: POST data should be bytes ...
1. First attach the effect picture ( I was lazy and only climbed 4 page ) 2. Jingdong's website https://www.jd.com/ 3. I don't load pictures here , Speed up the climb , It can also be used. Headless No pop-up mode options = webdri ...
My new book ,< Based on the stock big data analysis Python Introduction of actual combat >, It is expected that 2019 Published in Tsinghua Press at the end of the year . If you are interested in big data analysis , I want to learn Python, This book is a good choice . In terms of knowledge system , ...
More highlights , Welcome to the official account : Quantity technology house , You can also add a technical home personal micro signal :sljsz01, Communicate with me . The importance of real-time stock data For the four tradable assets : Stocks . futures . option . For digital money , futures . option . Digital currency , Can be handed in from ...
Getting data is an essential part of data analysis , Web crawler is one of the important channels to get data . In view of this , I picked up Python This sharp weapon , Opened the way of web crawler . The version used in this article is python3.5, The purpose is to capture the securities on the star of the day ...
This article will begin with Python principle , Please refer to :Python Learning Guide Why do you want to be a reptile A famous revolutionary . thinker . Politician . Strategist . Ma Yun, the main leader of social reform, once worked in 2015 It was mentioned in IT go to DT, What is meant by DT,DT ...
An important step of crawler is page parsing and data extraction . Please refer to :Python Learning Guide Page parsing and data extraction Actually, there are four main steps for reptiles : set ( Know where you're going to search... Or where you're going to search ) climb ( All the content of the website is ...
The main purpose of a crawler is to filter out useless information in a web page . Grab useful information from web pages The general crawler architecture is : stay python The crawler must have a certain understanding of the structure of the web page before . Such as the tag of the web page , Web page language and other knowledge , Recommend to W3School: W3s ...
Environmental Science :RHEL6.5 + Oracle 11.2.0.4 RAC In the installation RAC when , Missing package when checking cvuqdisk-1.0.9-1,oracle Provide script repair installation . But when it comes to execution, it's wrong : [[email protected] ...
var box = document.getElementById("box"); var btn = document.getElementById("btn" ...
Swoole:PHP The asynchrony of language . parallel . High performance network communication framework , Use pure C Language writing , Provides PHP Asynchronous multithreaded server of language , asynchronous TCP/UDP Network client , asynchronous MySQL, Database connection pool ,AsyncTask, Message queue ...
Used to draw pictures , This method will be in intiWithRect Time call . The impact of this approach is that there are touch event After the time , It will be redrawn , Many of these buttons will affect the efficiency . The following will be called 1. If in UIView initialization ...
Recently doing cppunit test Related work , use gcov and lcov Tool to see the coverage per line of code , Personal feeling lcov That's great , It looks very comfortable , It's great to light !~~ Here's the chat , As the title : I'm using lcov Of --remov ...
PHP Basic interview questions 1. The difference between double quotation marks and single quotation marks Double quotation marks explain variables , Single quotes do not interpret variables Insert single quotation marks in double quotation marks , If there is a variable in single quotation marks , Variable interpretation Double quotation marks must be followed by a non numeric variable name . Letter . Special characters for underscores , ...
http://www.techug.com/post/comparing-virtual-machines-vs-docker-containers.html Translator press : Various virtual machine technologies have opened the era of cloud computing ...
One . preparation 1. First you need to download cropper, Regular use npm, After entering the project path, execute the following command : npm install cropper 2. cropper be based on jquery, Don't forget to introduce jq, meanwhile ...
Tips “ One or more types required to compile dynamic expressions were not found . Whether there is a lack of right Microsoft.CSharp.dll and System.Core.dll References to ? ” error resolvent : Will introduce COM object (misc ...
\(dijkstra\) Heap optimization of algorithm , The time complexity is \(O(n+m)\log n\) Add an array \(id[]\) Record the position of a node in the heap , You can reduce the constant by avoiding repeated heap loading This method relies on handwriting heap #incl ...