If you are little white , This set of information can help you become a big bull , If you have rich development experience , This set of information can help you break through the bottleneck
2022web Full set of video tutorial front-end architecture H5 vue node Applet video + Information + Code + Interview questions .
?? Today we are going to study python Part of the regular expression of , First, why do you want to learn this part , Of course, it's because regular expressions are so convenient to deal with text data . For later entry nlp Lay a foundation in the field !
First recommend a website : Used for regular expression validation .
It looks like this .
. Means to match any single character except the newline character
For example, match ‘’. company ‘’( Match three characters )
# Here's to show python How to use regular expressions
import re # Regular expression library
content='''
The apple is red
Bananas are yellow
The leaves are green
The sky is blue
'''
# Convert the expression to pattern object , You can call the following find Something like that
p=re.compile(r'. color ')
for i in p.findall(content):
print(i)
give the result as follows :
* Means to match the previous subexpression any number of times , Include 0 Time
for example : matching ,.* Represents a match , And all the following characters 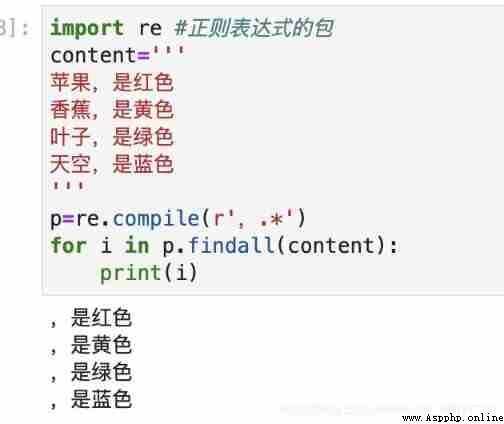
Of course _ It can be preceded by ordinary characters “ good _” matching “ Good good …”
+ Indicates that the previous subexpression is matched one or more times , barring 0 Time
The difference is that it does not include 0 Time .
+ The no. ( You can't 0 Time )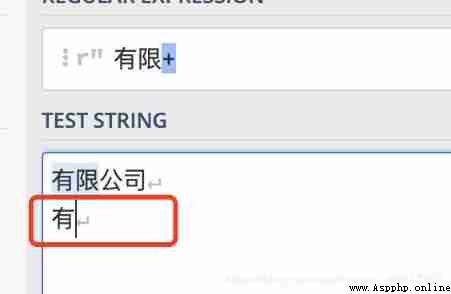
* The no. ( Sure 0 Time )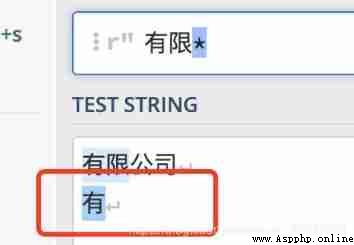
{ } Matches the number of times specified by the preceding character
for example : expression " oil {2,4}" Indicates that the matching oil word is the least 2 Most times 4 Time 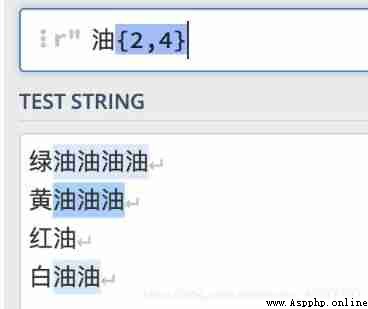
I wonder if you understand the following picture ?
We just want to match one by one
<head><title>
label , But did it help me? It all matched , This is because it only sees the first “< ” And the back left “>” The middle part is all regarded as arbitrary characters , This is the greedy model , It will match the characters as much as possible .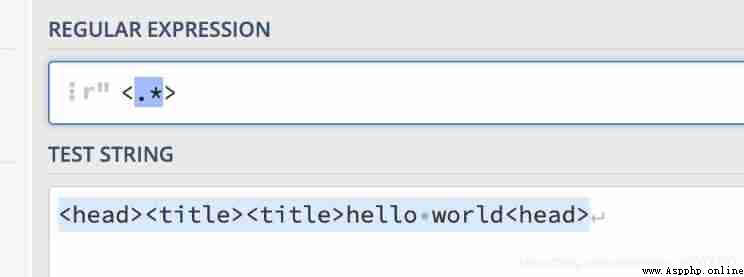
To become a non greedy model , Need to be in ‘+’,”*“ Add one at the end ‘?’ This is the match 4 Characters .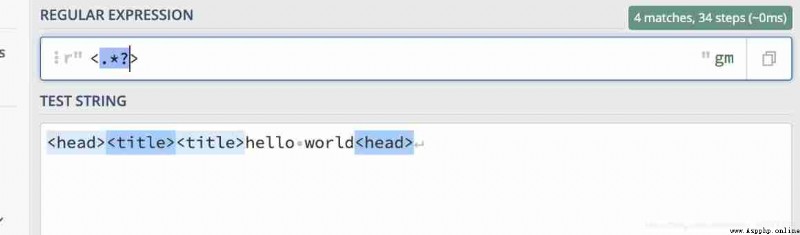
The backslash Multiple uses in regular expressions , Like escape
for example : We need to look for . All the elements before Need to use . / . .*/. ./. The slash is to tell the program that the next character represents an ordinary character . The meaning of 
Backslash can be combined with some characters to represent some special characters
Brackets can be used to indicate conditions or [0123] perhaps [0-3] This character can be 0,1,2,3
You can also store characters [ Yellow red green blue ]、[a-z] This kind of
for example : Matching inclusion ‘’ yes [ Yellow red green blue ] color ‘’ The characters of 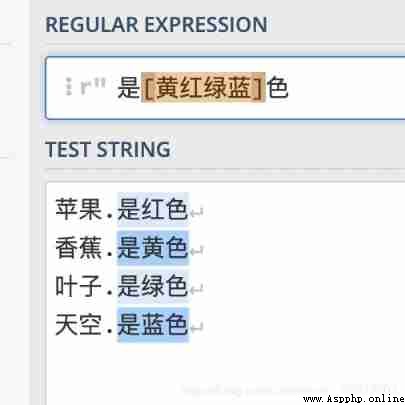
It should be noted that some metacharacters are in [] In life, you lose your meaning , Become ordinary characters
for example . + * There is no need to escape .‘
For example, find “. yes ” The characters of 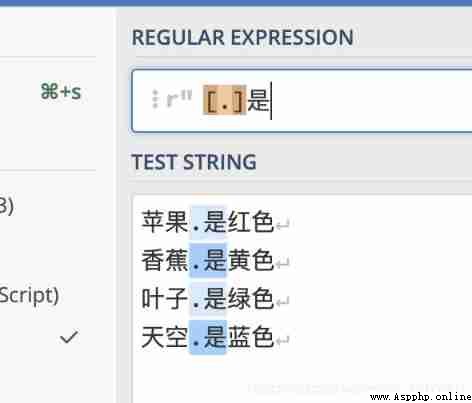
If in [] Use in ^ character , Represents the concept of non
for example : Match non numeric characters 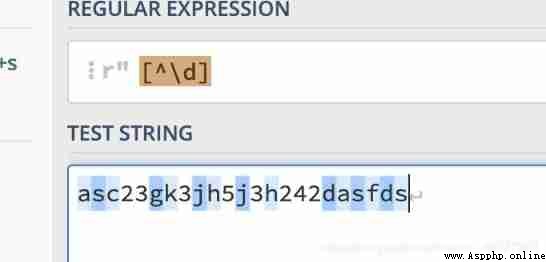
^ Indicates the starting position of the matching text, but the effect is different in different modes
Regular table expressions mainly include 2 Patterns : Single line mode and multi line mode
One way mode : It means that the whole text is regarded as a set of data , Match only the beginning of all data
Multi line mode : It refers to treating each row as a set of data , Match the beginning of each line
for example : We use single line pattern matching , Only match the first line 001
for example : We use multiline matching , It's a match 001、002、003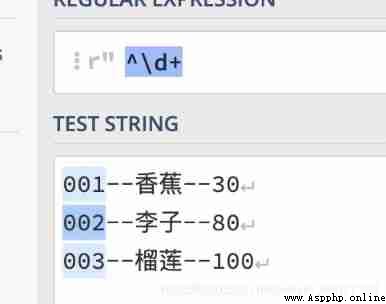
The problem is coming. , stay python How to decide whether to use single line mode or multi line mode in ?
stay compile Add parameters re.M perhaps re.MULTILINE Will do .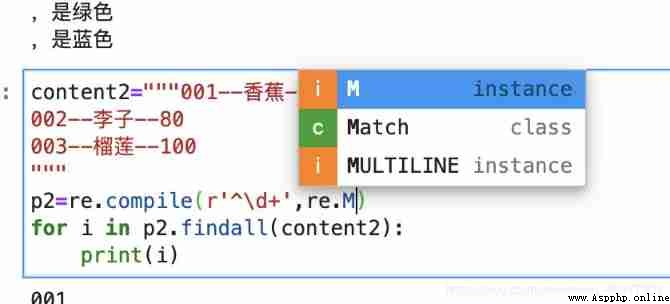
give the result as follows :
$ Indicates the end of the file , Usage and ^ similar , It is also divided into multi line mode and single line mode
One way mode

Multi line mode 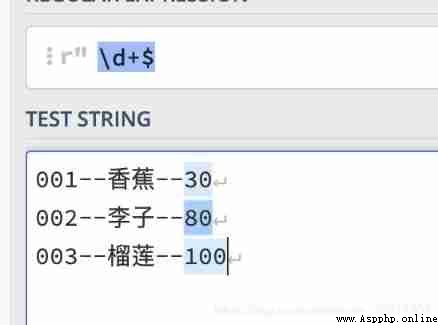
Group selection : It refers to selecting the characters we need from the regular expression matching results , for example : We need to match the characters before the comma , We might write “.*,” But the matched characters contain commas , But we don't want this comma , In this case, you need to use group selection .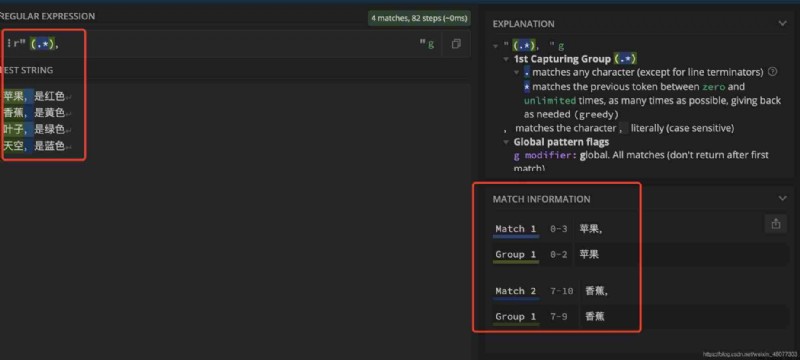
Have a look python Writing 
If you encounter multiple groups , Then each row of data becomes a tuple , You can extract the corresponding character by tuple subscript .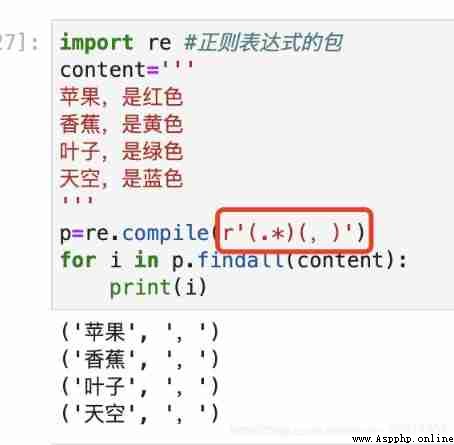
Let's have a little practice : Here's a set of data , Please choose a person's name and telephone number
Apple , Telephone 123131
Banana , Telephone 234241
leaf , Telephone 245363
sky , Telephone 124234
python The implementation is as follows :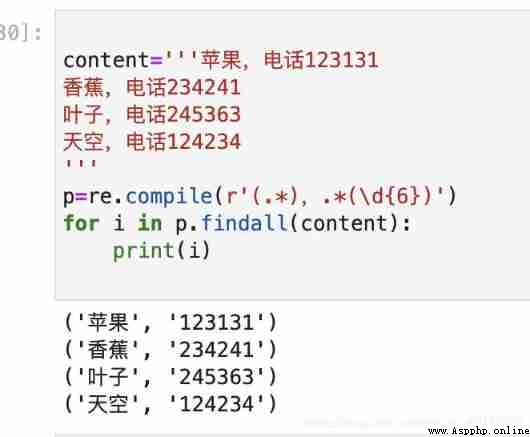
String object split() Method is only suitable for very simple string segmentation , When you need more flexibility to cut characters , You need to use regular expressions
for example :
# We have a set of data here
names=‘ Guan yu ; Zhang Fei , d , The professor , Li Yuanfang Judge dee ’
How should this be cut ?
We can use re.split Use the symbols of regular expressions to specify separators .
This chapter is mainly about the basic study of regular expressions , As a small introductory tutorial, it's still very good , I will continue to add... When I encounter complex usage in the future .