我們在學習機器學習相關內容時,一般是不需要我們自己去爬取數據的,因為很多的算法學習很友好的幫助我們打包好了相關數據,但是這並不代表我們不需要進行學習和了解相關知識。在這裡我們了解三種數據的爬取:鮮花/明星圖像的爬取、中國藝人圖像的爬取、股票數據的爬取。分別對著三種爬蟲進行學習和使用。
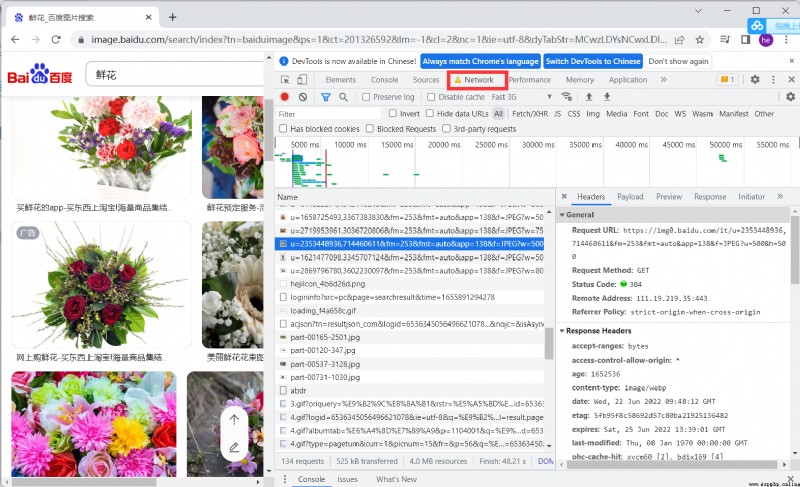
找到數據包進行分析,分析重要參數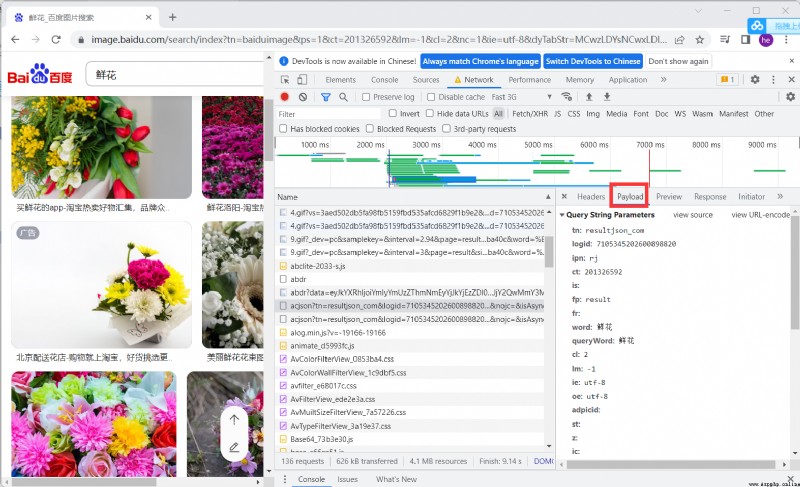
查看返回值進行分析,可以看到圖片體制在ThumbURL中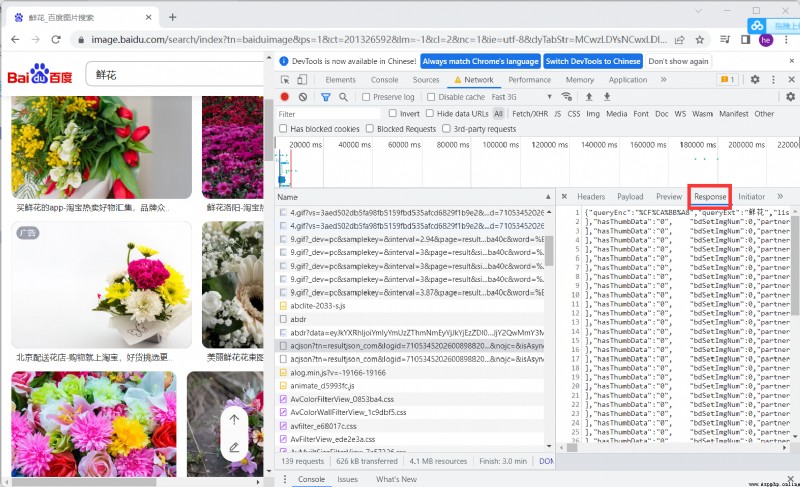
http://image.baidu.com/search/acjson? 百度圖片地址
拼接tn 進行訪問可以得到每個圖片的URL,在返回數據的thumbURL中
https://image.baidu.com/search/acjson?+tn
進行分離圖片的URL然後訪問下載
import requests
import os
import urllib
class GetImage():
def __init__(self,keyword='鮮花',paginator=1):
self.url = 'http://image.baidu.com/search/acjson?'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
self.keyword = keyword
self.paginator = paginator
def get_param(self):
keyword = urllib.parse.quote(self.keyword)
params = []
for i in range(1,self.paginator+1):
params.append(
'tn=resultjson_com&logid=10338332981203604364&ipn=rj&ct=201326592&is=&fp=result&fr=&word={}&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&expermode=&nojc=&isAsync=&pn={}&rn=30&gsm=78&1650241802208='.format(keyword,keyword,30*i)
)
return params
def get_urls(self,params):
urls = []
for param in params:
urls.append(self.url+param)
return urls
def get_image_url(self,urls):
image_url = []
for url in urls:
json_data = requests.get(url,headers = self.headers).json()
json_data = json_data.get('data')
for i in json_data:
if i:
image_url.append(i.get('thumbURL'))
return image_url
def get_image(self,image_url):
##根據圖片url,存入圖片
file_name = os.path.join("", self.keyword)
#print(file_name)
if not os.path.exists(file_name):
os.makedirs(file_name)
for index,url in enumerate(image_url,start=1):
with open(file_name+'/{}.jpg'.format(index),'wb') as f:
f.write(requests.get(url,headers=self.headers).content)
if index != 0 and index%30 == 0:
print("第{}頁下載完成".format(index/30))
def __call__(self, *args, **kwargs):
params = self.get_param()
urls = self.get_urls(params)
image_url = self.get_image_url(urls)
self.get_image(image_url=image_url)
if __name__ == '__main__':
spider = GetImage('鮮花',3)
spider()
if __name__ == '__main__':
spider = GetImage('明星',3)
spider()
if __name__ == '__main__':
spider = GetImage('動漫',3)
spider()
import requests
import json
import os
import urllib
def getPicinfo(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0',
}
response = requests.get(url,headers)
if response.status_code == 200:
return response.text
return None
Download_dir = 'picture'
if os.path.exists(Download_dir) == False:
os.mkdir(Download_dir)
pn_num = 1
rn_num = 10
for k in range(pn_num):
url = "https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28266&from_mid=500&format=json&ie=utf-8&oe=utf-8&query=%E4%B8%AD%E5%9B%BD%E8%89%BA%E4%BA%BA&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn="+str(pn_num)+"&rn="+str(rn_num)+"&_=1580457480665"
res = getPicinfo(url)
json_str = json.loads(res)
figs = json_str['data'][0]['result']
for i in figs:
name = i['ename']
img_url = i['pic_4n_78']
img_res = requests.get(img_url)
if img_res.status_code == 200:
ext_str_splits = img_res.headers['Content-Type'].split('/')
ext = ext_str_splits[-1]
fname = name+'.'+ext
open(os.path.join(Download_dir,fname),'wb').write(img_res.content)
print(name,img_url,'saved')
我們對http://quote.eastmoney.com/center/gridlist.html 內的股票數據進行爬取,並且把數據儲存下來
# http://quote.eastmoney.com/center/gridlist.html
import requests
from fake_useragent import UserAgent
import json
import csv
import urllib.request as r
import threading
def getHtml(url):
r = requests.get(url, headers={
'User-Agent': UserAgent().random,
})
r.encoding = r.apparent_encoding
return r.text
# 爬取多少
num = 20
stockUrl = 'http://52.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409623798991171317_1654957180928&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1654957180938'
if __name__ == '__main__':
responseText = getHtml(stockUrl)
jsonText = responseText.split("(")[1].split(")")[0];
resJson = json.loads(jsonText)
datas = resJson['data']['diff']
dataList = []
for data in datas:
row = [data['f12'],data['f14']]
dataList.append(row)
print(dataList)
f = open('stock.csv', 'w+', encoding='utf-8', newline="")
writer = csv.writer(f)
writer.writerow(("代碼","名稱"))
for data in dataList:
writer.writerow((data[0]+"\t",data[1]+"\t"))
f.close()
def getStockList():
stockList = []
f = open('stock.csv', 'r', encoding='utf-8')
f.seek(0)
reader = csv.reader(f)
for item in reader:
stockList.append(item)
f.close()
return stockList
def downloadFile(url,filepath):
try:
r.urlretrieve(url,filepath)
except Exception as e:
print(e)
print(filepath,"is downLoaded")
pass
sem = threading.Semaphore(1)
def dowmloadFileSem(url,filepath):
with sem:
downloadFile(url,filepath)
urlStart = 'http://quotes.money.163.com/service/chddata.html?code='
urlEnd = '&end=20210221&fields=TCLOSW;HIGH;TOPEN;LCLOSE;CHG;PCHG;VOTURNOVER;VATURNOVER'
if __name__ == '__main__':
stockList = getStockList()
stockList.pop(0)
print(stockList)
for s in stockList:
scode = str(s[0].split("\t")[0])
url = urlStart+("0" if scode.startswith('6') else '1')+ scode + urlEnd
print(url)
filepath = (str(s[1].split("\t")[0])+"_"+scode)+".csv"
threading.Thread(target=dowmloadFileSem,args=(url,filepath)).start()
有可能當時爬取的數據是髒數據,運行下面代碼不一定能跑通,需要你自己處理數據還是其他方法
## 主要利用matplotlib進行圖像繪制
import pandas as pd
import matplotlib.pyplot as plt
import csv
import 股票數據爬取 as gp
plt.rcParams['font.sans-serif'] = ['simhei'] #指定字體
plt.rcParams['axes.unicode_minus'] = False #顯示-號
plt.rcParams['figure.dpi'] = 100 #每英寸點數
files = []
def read_file(file_name):
data = pd.read_csv(file_name,encoding='gbk')
col_name = data.columns.values
return data,col_name
def get_file_path():
stock_list = gp.getStockList()
paths = []
for stock in stock_list[1:]:
p = stock[1].strip()+"_"+stock[0].strip()+".csv"
print(p)
data,_=read_file(p)
if len(data)>1:
files.append(p)
print(p)
get_file_path()
print(files)
def get_diff(file_name):
data,col_name = read_file(file_name)
index = len(data['日期'])-1
sep = index//15
plt.figure(figsize=(15,17))
x = data['日期'].values.tolist()
x.reverse()
xticks = list(range(0,len(x),sep))
xlabels = [x[i] for i in xticks]
xticks.append(len(x))
y1 = [float(c) if c!='None' else 0 for c in data['漲跌額'].values.tolist()]
y2 = [float(c) if c != 'None' else 0 for c in data['漲跌幅'].values.tolist()]
y1.reverse()
y2.reverse()
ax1 = plt.subplot(211)
plt.plot(range(1,len(x)+1),y1,c='r')
plt.title('{}-漲跌額/漲跌幅'.format(file_name.split('_')[0]),fontsize = 20)
ax1.set_xticks(xticks)
ax1.set_xticklabels(xlabels,rotation = 40)
plt.ylabel('漲跌額')
ax2 = plt.subplot(212)
plt.plot(range(1, len(x) + 1), y1, c='g')
#plt.title('{}-漲跌額/漲跌幅'.format(file_name.splir('_')[0]), fontsize=20)
ax2.set_xticks(xticks)
ax2.set_xticklabels(xlabels, rotation=40)
plt.xlabel('日期')
plt.ylabel('漲跌額')
plt.show()
print(len(files))
for file in files:
get_diff(file)
上文描述了三個數據爬取的案例,不同的數據爬取需要我們對不同的URL進行獲取,不同參數進行輸入,URL如何組合、如何獲取、這是數據爬取的難點,需要有一定的經驗和基礎。
Spider-01-爬蟲介紹 Python 爬蟲的知識量不是特別大,但是需要不停和網頁打交道,每個網頁情況都有所差異,所以對應變能力有些要求 爬蟲准備工作 參考資料 精通Python爬蟲框架Scrap ...
鑒於好多人想學Python爬蟲,缺沒有簡單易學的教程,我將在CSDN和大家分享Python爬蟲的學習筆記,不定期更新 基礎要求 Python 基礎知識 Python 的基礎知識,大家可以去菜鳥教程進行 ...
Python爬蟲編程常見問題解決方法: 1.通用的解決方案: [按住Ctrl鍵不送松],同時用鼠標點擊[方法名],查看文檔 2.TypeError: POST data should be bytes ...
1.先附上效果圖(我偷懶只爬了4頁) 2.京東的網址https://www.jd.com/ 3.我這裡是不加載圖片,加快爬取速度,也可以用Headless無彈窗模式 options = webdri ...
我的新書,<基於股票大數據分析的Python入門實戰>,預計將於2019年底在清華出版社出版. 如果大家對大數據分析有興趣,又想學習Python,這本書是一本不錯的選擇.從知識體系上來看, ...
獲取數據是數據分析中必不可少的一部分,而網絡爬蟲是是獲取數據的一個重要渠道之一.鑒於此,我拾起了Python這把利器,開啟了網絡爬蟲之路. 本篇使用的版本為python3.5,意在抓取證券之星上當天所 ...
本篇將開始介紹Python原理,更多內容請參考:Python學習指南 為什麼要做爬蟲 著名的革命家.思想家.政治家.戰略家.社會改革的主要領導人物馬雲曾經在2015年提到由IT轉到DT,何謂DT,DT ...
爬蟲的一個重要步驟就是頁面解析與數據提取.更多內容請參考:Python學習指南 頁面解析與數據提取 實際上爬蟲一共就四個主要步驟: 定(要知道你准備在哪個范圍或者網站去搜索) 爬(將所有的網站的內容全 ...
爬蟲主要就是要過濾掉網頁中沒用的信息.抓取網頁中實用的信息 一般的爬蟲架構為: 在python爬蟲之前先要對網頁的結構知識有一定的了解.如網頁的標簽,網頁的語言等知識,推薦去W3School: W3s ...
環境:RHEL6.5 + Oracle 11.2.0.4 RAC 在安裝RAC時,檢查時缺少包 cvuqdisk-1.0.9-1,oracle提供腳本修復安裝. 但在執行時報錯: [[email protected] ...
var box = document.getElementById("box"); var btn = document.getElementById("btn" ...
Swoole:PHP語言的異步.並行.高性能網絡通信框架,使用純C語言編寫,提供了PHP語言的異步多線程服務器,異步TCP/UDP網絡客戶端,異步MySQL,數據庫連接池,AsyncTask,消息隊列 ...
用來畫圖,這個方法會在intiWithRect時候調用.這個方法的影響在於有touch event的時候之後,會重新繪制,很多這樣的按鈕的話就會比較影響效率.以下都會被調用1.如果在UIView初始化 ...
最近在做cppunit test相關工作,用gcov和lcov工具來查看每行代碼的覆蓋率,個人感覺lcov真棒,看起來很舒服,點起來也很爽!~~ 閒聊至此,如題: 我使用的是lcov的 --remov ...
PHP面試基礎題目 1.雙引號和單引號的區別 雙引號解釋變量,單引號不解釋變量 雙引號裡插入單引號,其中單引號裡如果有變量的話,變量解釋 雙引號的變量名後面必須要有一個非數字.字母.下劃線的特殊字符, ...
http://www.techug.com/post/comparing-virtual-machines-vs-docker-containers.html 譯者按: 各種虛擬機技術開啟了雲計算時代 ...
一 .准備工作 1.首先需要先下載cropper,常規使用npm,進入項目路徑後執行以下命令: npm install cropper 2. cropper基於jquery,在此不要忘記引入jq,同時 ...
提示“找不到編譯動態表達式所需的一種或多種類型.是否缺少對 Microsoft.CSharp.dll 和 System.Core.dll 的引用? ”錯誤 解決方法: 將引入的COM對象(misc ...
\(dijkstra\) 算法的堆優化,時間復雜度為\(O(n+m)\log n\) 添加數組\(id[]\)記錄某節點在堆中的位置,可以避免重復入堆從而減小常數 而這一方法需要依托手寫堆 #incl ...