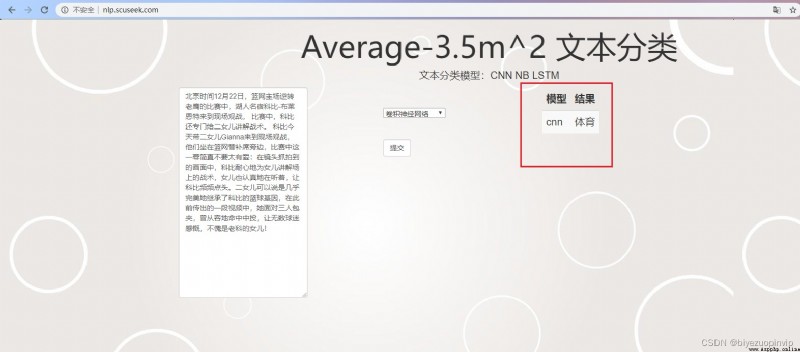
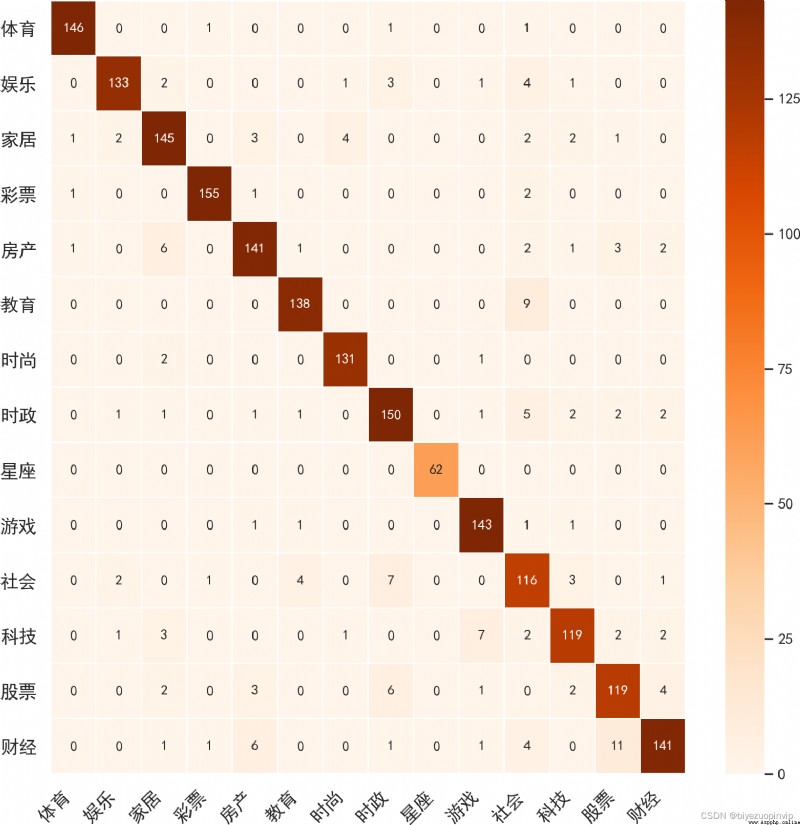
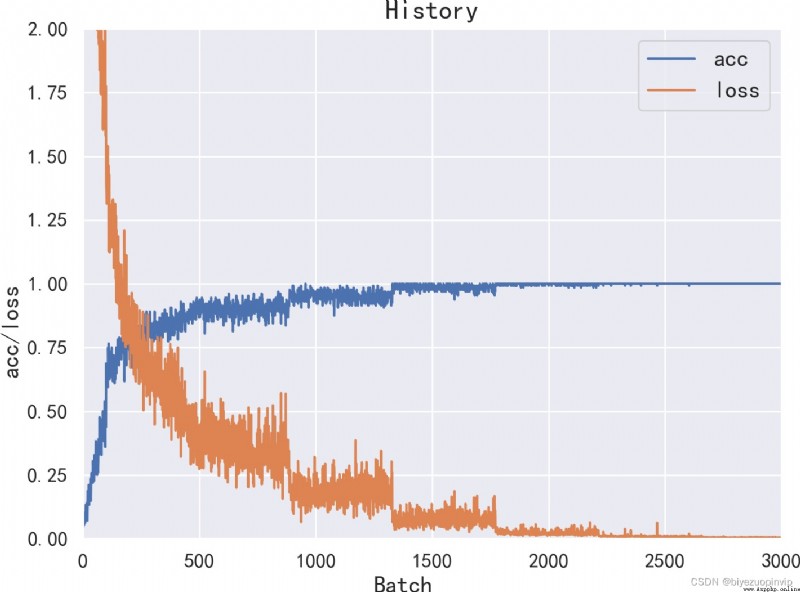
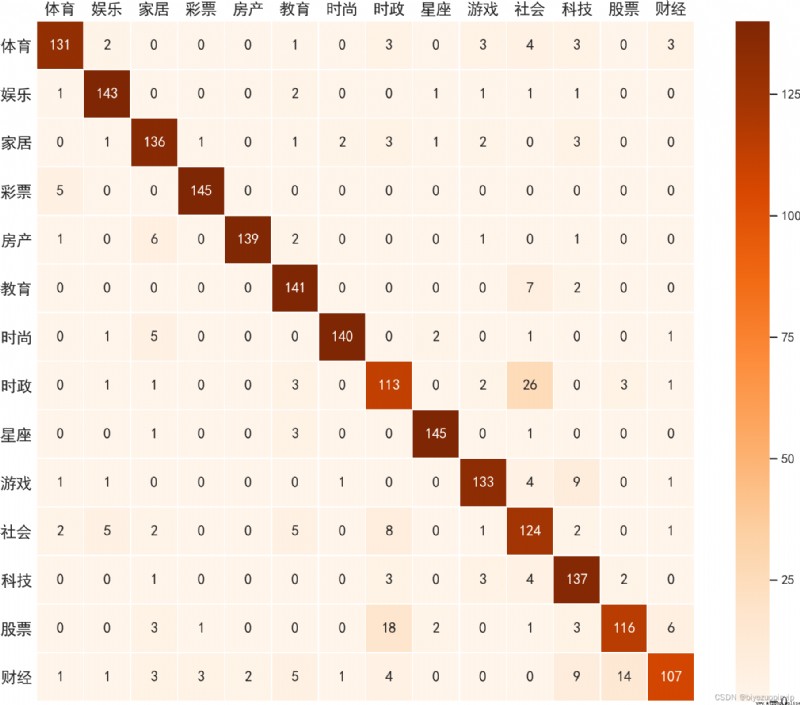
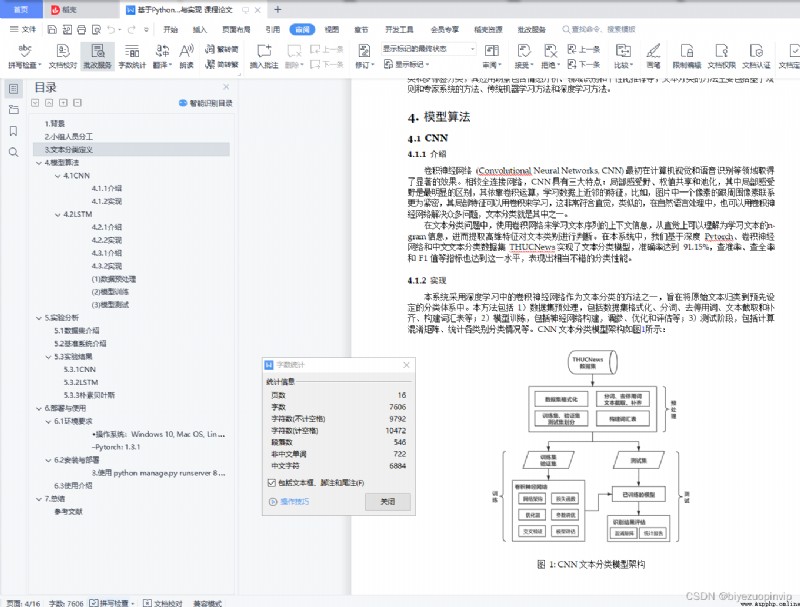
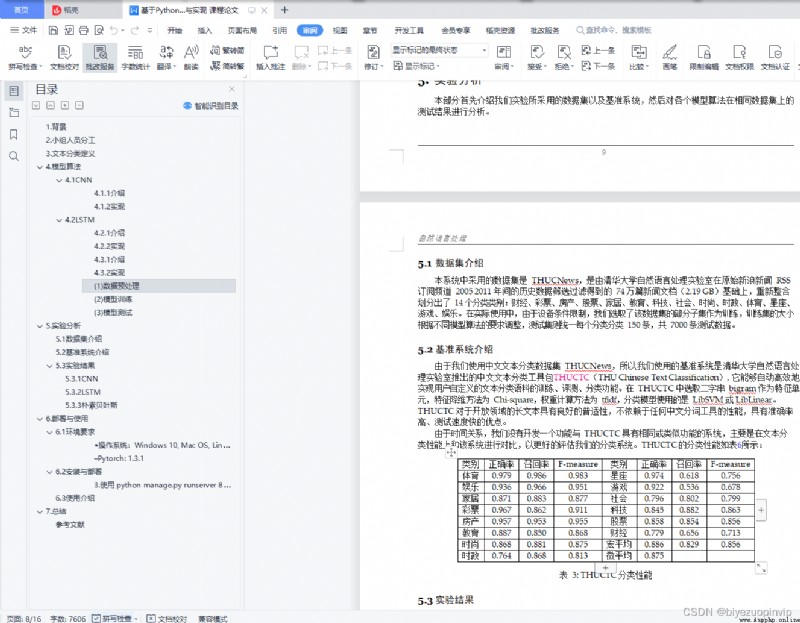
experimental analysis 9 5.1 Data set introduction 10 5.2 Introduction to the benchmark system 10 5.3 experimental result 10 5.3.1 CNN 10 5.3.2 LSTM 12 5.3.3 Naive Bayes 14
Deployment and use 15 6.1 Environmental requirements 15 6.2 Installation and deployment 16 6.3 Introduction 16
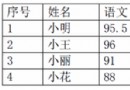
summary 17 reference 17 1. background With the development of the Internet , The data and information in the network are growing exponentially . Because there are more and more electronic documents on the network , How to organize and manage these information and data automatically and effectively is a huge challenge , Content based information retrieval and text count It is reported that mining has gradually become a field of concern for researchers . among , In recent years, text classification technology has been widely concerned and studied . Text classification is a basic task in natural language processing , The main task is to mark in a pre - given category (label) Set below , Determine its category according to the text content , The purpose is to sort out and classify text resources , At the same time, text classification is also the key link to solve the problem of text information overload . With the development of technology , Text classification has been applied in various fields , such as : Mail classification 、 Web page classification 、 Text index 、 Auto digest 、 Information retrieval 、 Information push 、 Digital library and learning system . This paper implements a text classification system , Through deep learning , Naive Bayes 、 Support vector machine and other models to achieve text classification , Experiments show that the method based on deep learning has the best effect . Last , adopt Web In the form of . The organizational structure of this paper is as follows : 1. The first 1 Chapter introduces the background of the project ; 2. The first 2 Chapter introduces the information of team members and the division of labor ; 3. The first 3 Chapter introduces the task definition of text classification ; 4. The first 4 Chapter introduces the system architecture of text classification system , Related models in the system 、 Design and implementation of the algorithm ; 5. The first 5 This chapter introduces the experiment of the model , Include datasets 、 Introduction to the benchmark system , The experimental results are compared and analyzed ; 6. The first 6 Chapter introduces the environmental requirements of text classification system 、 System deployment and methods used ; 7. The first 7 Chapter gives a general summary ; 2. Division of labor of team members The division of labor of the project team is shown in the table 1 Shown . The task assignment and management of the project are mainly in the charge of the team leader and classmates , Each team member is responsible for building and evaluating the text classification model , Include CNN Model ,LSTM Model , Naive Bayes, etc , See table for details 1, Students are responsible for the Web And the design of front-end display , also , Each part of the document is written by students , Finally, the students will integrate . Resource download address :https://download.csdn.net/download/sheziqiong/85731204 Resource download address :https://download.csdn.net/download/sheziqiong/85731204