Python標准庫中的列表(list)類似於C/C++中的數組。
Python擴展庫中的ndarray對象有許多操作和列表(list)的操作類似,比如切片操作、元素訪問呢,但它們是兩個東西,大家不要搞混了。關於ndarray對象的基本操作,可參考博文 https://blog.csdn.net/wenhao_ir/article/details/124416798
數組對於編程而言其重要性是不言而喻的,所以這篇博文匯總一下Python標准庫中的列表(list)的操作。
序列是 Python 中最基本的數據結構。
序列中的每個值都有對應的位置值,稱之為索引,第一個索引是 0,第二個索引是 1,依此類推。
序列都可以進行的操作包括索引,切片,加,乘,檢查成員。
此外,Python 已經內置確定序列的長度以及確定最大和最小的元素的方法。
Python 有 6 個序列的內置類型,但最常見的是列表和元組。
列表是最常用的 Python 數據類型,列表的數據項不需要具有相同的類型。
創建一個列表,只要把逗號分隔的不同的數據項使用方括號括起來即可。
list1 = ['Google', 'CSDN', 1997, 1999]
list2 = [1, 2, 3, 4, 5]
list3 = ['red', 'green', 'blue', 'yellow', 'white', 'black']
運行結果如下圖所示: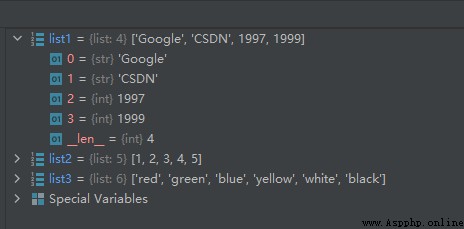
從上面的結果中我們可以看出,在Python中是用單詞list表示列表的。
列表本質上還是對象,所以可以用構造函數創建,代碼如下:
list1 = list()
list1.append('Google')
list1.append('CSDN')
list1.append('1997')
list1.append('1999')
運行結果如下: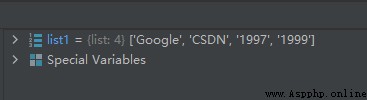
從上面來看,顯然第1種方法比第2種方法方便。但是當您要使用成員函數append()追加元素時,如果用第一種方法,Pycharm會不建議這麼操作,如下圖所示:
This list creation could be rewritten as a list literal。
這句話的意思是列表應該按本義創建。什麼叫本義創建?列表本質上是個對象,既然對象,那就用構造函數初始化創建呗。
下面的兩篇文章都說了這個問題的原因:
https://www.cnblogs.com/jiangxiaobo/p/11622730.html
https://zhuanlan.zhihu.com/p/222401764
示例代碼如下:
list1 = ['Google', 'CSDN', 1997, 1999]
print(list1[0])
print(list1[1])
print(list1[2])
運行結果如下: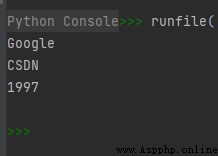
除了從左往右,也可從右往左,示例代碼如下:
list1 = ['Google', 'CSDN', 1997, 1999]
print(list1[-1])
print(list1[-2])
print(list1[-3])
運行結果如下: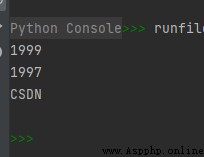
示例代碼如下:
list1 = ['Google', 'CSDN', 'tencent', 1997, 1999, 1998]
list2 = list1[0:4]
注意:切片的區間是左閉右開的,即[0:4]相當於[0,4)
運行結果如下: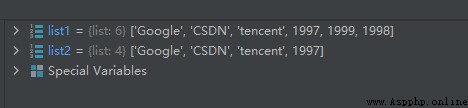
還可以正索引和負索引相結合:
list1 = ['Google', 'CSDN', 'tencent', 1997, 1999, 1998]
list2 = list1[0:-2]
上面的list1[0:-2]表示截取0到倒數第2個的片段,運行結果如下: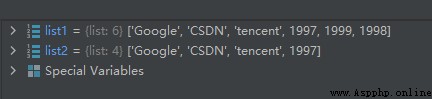
注意:在這種情況下我們對列表的創建要使用構造函數創建,而不要使用中括號創建列表,否則Pycharm會不建議這麼操作,如下圖所示:
This list creation could be rewritten as a list literal。
這句話的意思是列表應該按本義創建。什麼叫本義創建?列表本質上是個對象,既然對象,那就用構造函數初始化創建呗。
下面的兩篇文章都說了這個問題的原因:
https://www.cnblogs.com/jiangxiaobo/p/11622730.html
https://zhuanlan.zhihu.com/p/222401764
示例代碼如下:
list1 = list()
list1.append('Google')
list1.append('CSDN')
list1.append('1997')
list1.append('1999')
運行結果如下: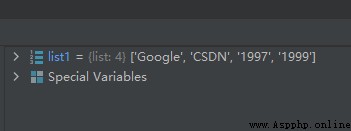
要特別注意的是:當使用方法append()添加的元素本身也是一個列表時,此時是淺拷貝操作,也就是說被拷貝的列表值改變,那麼列表中相應元素的值也會變,示例代碼如下:
list1 = list()
list1.append('Google')
list1.append('CSDN')
list1.append('1997')
list1.append('1999')
list2 = [2010]
list1.append(list2)
list2[0] = 4444
運行結果如下:
如果是深拷貝,那麼list1中的第4個元素值應該是[2010]才對。
如果想實現列表的深拷貝,可以像下面這樣操作:
import copy
list1 = list()
list1.append('Google')
list1.append('CSDN')
list1.append('1997')
list1.append('1999')
list2 = [2010]
list1.append(copy.deepcopy(list2))
list2[0] = 4444
運行結果如下: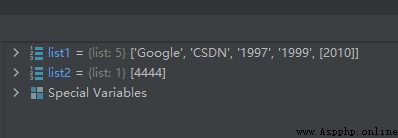
當然也可以用方法copy()實現,即代碼:
list1.append(copy.deepcopy(list2))
可以換成
list1.append(list2.copy())
對於一般的變量,效果就是深拷貝,代碼如下:
list1 = list()
list1.append('Google')
list1.append('CSDN')
list1.append('1997')
list1.append('1999')
value1 = 2030
list1.append(value1)
value1 = 4444
運行結果如下: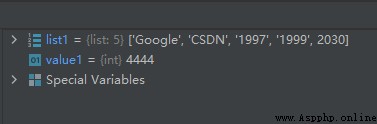
從上面的示例我們可以看出,方法append()是把被追加的列表作一個整體(即作為一個元素)添加到原列表中的,有時候我們希望在列表末尾一次性追加另一個序列中的多個值,這個時候就可以用方法extend()實現。
示例代碼如下:
list1 = ['Google', 'CSDN', 'Taobao']
list2 = [1997, 1999, 1998]
list1.extend(list2)
運行結果如下: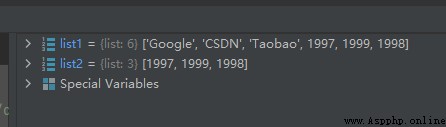
示例代碼如下:
list1 = ['Google', 'CSDN', 'Taobao', 1997, 1999, 1998, 1999]
list1.insert(3, 'Tecent')
運行結果如下: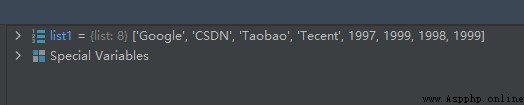
示例代碼如下:
list1 = ['Google', 'CSDN', 'tencent', 1997, 1999, 1998]
del list1[2]
運行結果如下: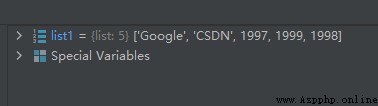
從上面的結果來看,第2個元素’tencent’被刪除了。
方法pop()語法如下:
list.pop([index=-1])
index – 可選參數,要移除列表元素的索引值,不能超過列表總長度,默認為 index=-1,刪除最後一個列表值。
示例代碼如下:
list1 = ['Google', 'CSDN', 'tencent', 1997, 1999, 1998]
list2 = ['Google', 'CSDN', 'tencent', 1997, 1999, 1998]
value1 = list1.pop()
value2 = list1.pop(1)
運行結果如下: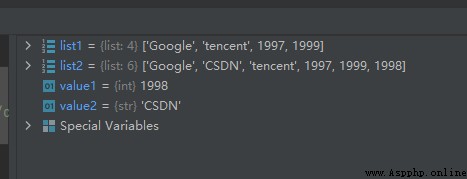
示例代碼如下:
list1 = ['Google', 'CSDN', 'tencent', 1997, 1999, 1998, 'CSDN']
list1.remove('CSDN')
運行結果如下: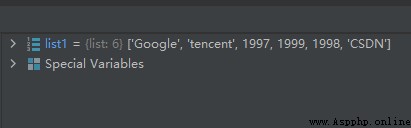
從上面的運行結果可知,方法remove()移除的是第一個匹配到的元素。上面的字符串元素’CSDN’有兩個,但只被刪了第一個。
示例代碼如下:
len1 = len([1, 2, 3])
list1 = ['Google', 'CSDN', 'tencent', 1997, 1999, 1998]
len2 = len(list1)
運行結果如下:
示例代碼如下:
list1 = [456, 700, 200]
max1 = max(list1)
運行結果如下: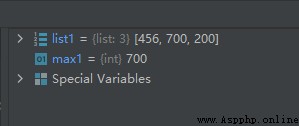
示例代碼如下:
list1 = [456, 700, 200]
min1 = min(list1)
運行結果如下: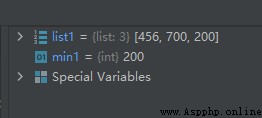
示例代碼如下:
list1 = ['Google', 'CSDN', 'tencent', 1997, 1999, 1998]
list2 = [4, 5, 6]
list3 = list1+list2
運行結果如下: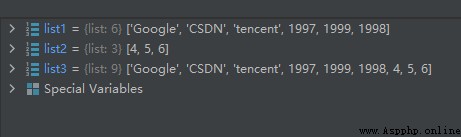
示例代碼如下:
list1 = ['Google', 'CSDN', 'tencent', 1997, 1999, 1998]
list2 = [4, 5, 6]
list3 = list1*2
list4 = list2*3
運行結果如下:
示例代碼如下:
list1 = ['Google', 'CSDN', 'tencent', 1997, 1999, 1998]
bool1 = 'CSDN' in list1
bool2 = 'zhihu' in list1
運行結果如下: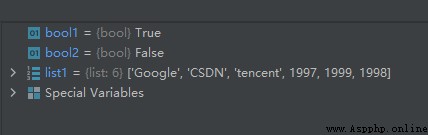
列表嵌套,本質上指列表也可以作為列表的元素。
示例代碼如下:
list1 = [['Google', 'CSDN', 'tencent'], [1997, 1999, 1998]]
a1 = list1[0][1]
b1 = list1[1][2]
運行結果如下: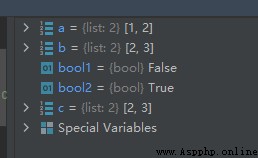
注意,對於語句:
a1 = list1[0][1]
b1 = list1[1][2]
不能像ndarray對象那樣寫成下面這樣:
a1 = list1[0, 1]
b1 = list1[1, 2]
此時會報錯: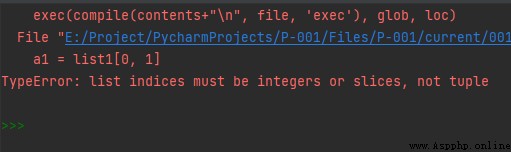
ndarray的多維矩陣元素訪問詳情見下面這篇博文:
https://blog.csdn.net/wenhao_ir/article/details/124419922
示例代碼如下:
import operator
a = [1, 2]
b = [2, 3]
c = [2, 3]
bool1 = operator.eq(a, b)
bool2 = operator.eq(c, b)
運行結果如下:
示例代碼如下:
list1 = [123, 'Google', 'CSDN', 'Taobao', 123]
count1 = list1.count(123)
count2 = list1.count('CSDN')
運行結果如下: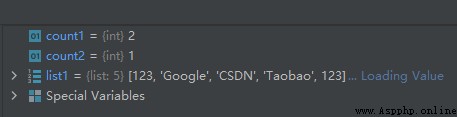
方法index()語法如下:
list.index(x[, start[, end]])
x-- 查找的對象。
start-- 可選,查找的起始位置。
end-- 可選,查找的結束位置。
示例代碼如下:
list1 = ['Google', 'CSDN', 'Taobao', 1997, 1999, 1998, 1999]
index1 = list1.index('CSDN')
index2 = list1.index(1999)
運行結果如下: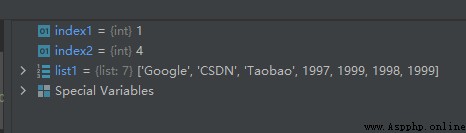
列表中1999有兩個,可見其返回的是第一個的索引。
示例代碼如下:
list1 = [1, 2, 3, 4, 5, 6, 7]
list1.reverse()
運行結果如下: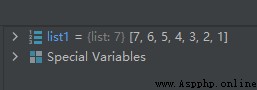
方法sort()的語法如下:
list.sort( key=None, reverse=False)
key – 用來進行比較的數值,可選參數。
reverse – 排序規則,reverse = True 降序, reverse = False 升序(默認)。
示例代碼如下:
list1 = [1, 5, 3, 9, 7, 4, 2, 8, 6]
list1.sort()
list2 = [1, 5, 3, 9, 7, 4, 2, 8, 6]
list2.sort(reverse=True)
運行結果如下: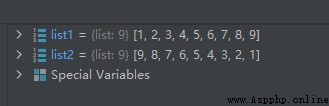
關於方法sort()的第一個參數key的用法,就說來話長了,具體情況大家可以參見我的另一篇博文:
https://blog.csdn.net/wenhao_ir/article/details/125406092
示例代碼如下:
list1 = ['Google', 'CSDN', 'Taobao', 1997, 1999, 1998, 1999]
list1.clear()
運行結果如下: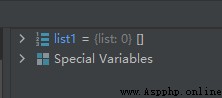
方法copy()的使用示例如下:
list1 = ['Google', 'CSDN', 'Taobao', 1997, 1999, 1998, 1999]
list2 = list1.copy()
list1[0] = 'Facebook'
運行結果如下:
從上面的代碼和運行結果我們可以看出,方法copy()作的是深拷貝。
方法copy.append()的使用示例如下:
import copy
list1 = ['Google', 'CSDN', 'Taobao', 1997, 1999, 1998, 1999]
list2 = copy.deepcopy(list1)
list1[0] = 'Facebook'
運行結果如下: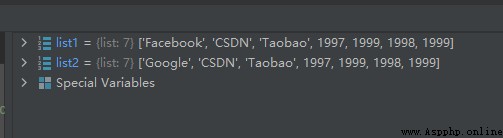
從上面的代碼和運行結果我們可以看出,方法copy.append()也是作的是深拷貝。
示例代碼如下:
list1 = ['Google', 'Taobao', 'CSDN', 'Baidu']
tuple1 = tuple(list1)
運行結果如下: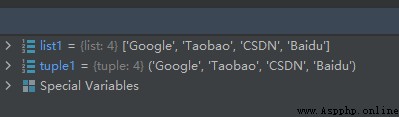
關於元組的詳細操作,大家可以參看我的另一篇博文,鏈接如下:
https://blog.csdn.net/wenhao_ir/article/details/125407815
參考資料:
https://blog.csdn.net/wenhao_ir/article/details/125100220