Python列表(list)的方法sort()的語法如下:
list.sort( key=None, reverse=False)
兩個參數都是可選的,第二個參數不用講了,很簡單,就是控制是按升序還是降序排。
這篇文章主要講第一個參數key的作用。
那麼參數key的作用是什麼呢?
總的來說,我們可以利用它實現按我們想要的標准進行排序,即我們可以自定義排序的標准,或者稱為自定義排序的方式。
參數key是某個函數的返回值,這個函數的輸入參數只有一個,那就是我們要待排序的列表的每一個元素(相當於待排序列表中有多少個元素就執行多少次這個函數),這個函數的返回值作為我們對列表元素進行排序的依據。
上面這句話不太好理解,沒頭系,看幾個實例就知道。
先看對嵌套列表(二維列表)的默認排序。
list1 = [[1, 7], [1, 5], [2, 4], [1, 1]]
list1.sort()
運行結果如下: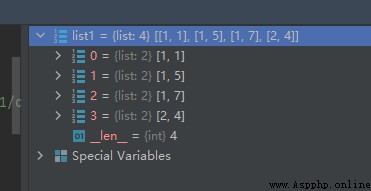
從運行結果我們可以看出,默認的排序方式是先按每個列表型元素的第0個元素進行排序,再按每個列表型元素的第1個元素進行排序的。
如果我們想讓排序方式按每一個列表型元素的第1個元素進行排序,怎麼辦呢?
按下面這樣寫就行了。
def sort_fun(x1):
return x1[1]
list1 = [[1, 7], [1, 5], [2, 4], [1, 1]]
list1.sort(key=sort_fun)
運行結果如下: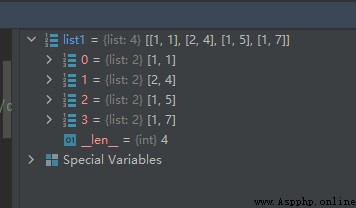
我們看到,上面的結果正是按每一個列表型元素的第1個元素進行排序的。
怎麼實現的呢?
sort()方法在執行後,會將list1中四個列表型元素[1, 7]、[1, 5]、 [2, 4]、[1, 1]依次作為函數sort_fun的輸入參數,並依次得到四個返回值,四個返回值為各自索引為1的元素值,即7、5、4、1這四個值,這四個值按升序排序後為1、4、5、7,所以四個列表型元素[1, 7]、[1, 5]、 [2, 4]、[1, 1]就被排序為了[1, 1]、[2, 4]、[1, 5]、 [1, 7]。
我們可以利用匿名函數lambda來簡化上面的寫法。
關於匿名函數lambda的介紹可以參見下面這篇文章:
https://zhuanlan.zhihu.com/p/58579207
利用匿名函數lambda來簡化上面的代碼:
list1 = [[1, 7], [1, 5], [2, 4], [1, 1]]
list1.sort(key=lambda x1: x1[1])
運行結果和上面的運行結果一樣: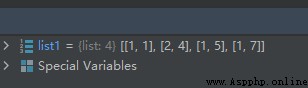
再舉一個例子,我們要對列表中的字符串按長度進行排序,那麼可以像下面這樣寫:
list1 = ['baidu', 'CSDN', 'QQ', 'Google', 'suwenhao']
list1.sort(key=lambda x1: len(x1))
運行結果如下: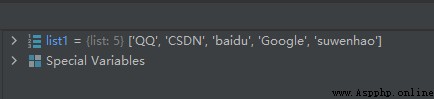
怎麼樣實現的呢?
sort()方法在執行後,會將五個字符串元素’baidu’, ‘CSDN’, ‘QQ’, ‘Google’, 'suwenhao’分別代入匿名函數中作為輸入參數,並依次求得它們的長度為5、4、2、6、8,按長度升序排的話就是2、4、5、6、8,這樣原序列就被排序為了:[‘QQ’, ‘CSDN’, ‘baidu’, ‘Google’, ‘suwenhao’]
從上面的示例我們可以看出,方法sort()的第一個參數key調用的函數輸入參數只有一個,即只能為待排序的列表的每一個元素,如果我們想有更多的參數實現更強的排序功能,怎麼辦呢?可以參考我的另一篇博文 https://blog.csdn.net/wenhao_ir/article/details/125407158