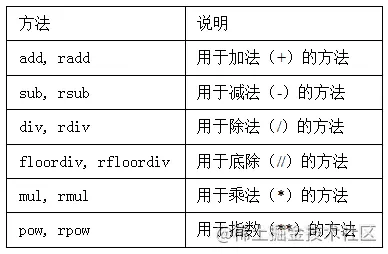
One 、 Realization effect ( Take Jinquan wallpaper as an example )
Two 、 Implementation process
3、 ... and 、 Source code
Four 、Python Regular expressions match date and time
One 、 Realization effect ( Take Jinquan wallpaper as an example )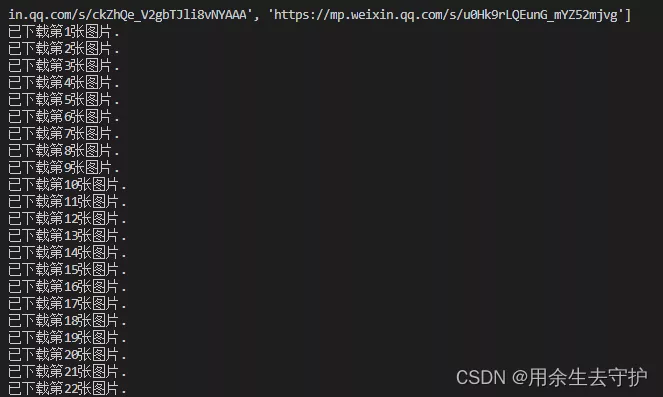

1. Create a new one link Text , Save the links of the articles to be downloaded in turn ;

2. Create a new one .py file , Copy the following source code ;
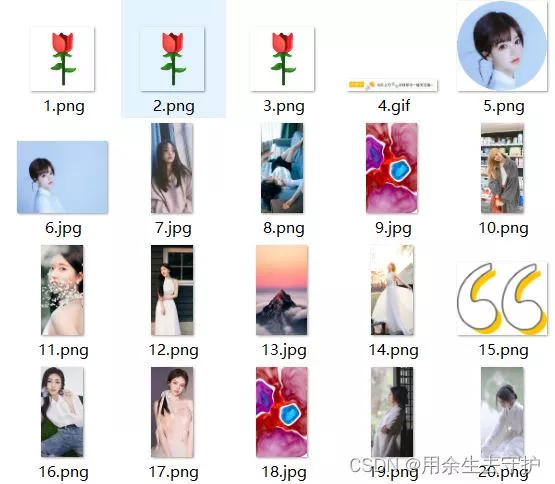
3. Create a new one pic Folder , To save pictures ;
4. Can run ;
3、 ... and 、 Source codesound code
The code is as follows ( Example ):
import requestsfrom re import findallfrom bs4 import BeautifulSoupimport timeimport osimport sysweixin_title=""weixin_time=""# Get the content of wechat official account , Save title and time def get_weixin_html(url): global weixin_time,weixin_title res=requests.get(url) soup=BeautifulSoup(res.text,"html.parser") # Get the title temp=soup.find('h1') weixin_title=temp.string.strip() # Use regular expressions to get the time # result=findall(r'[0-9]{4}-[0-9]{2}-[0-9]{2}.+:[0-9]{2}',res.text) result=findall(r"(\d{4}-\d{1,2}-\d{1,2})",res.text) weixin_time=result[0] # Get the text html And modify it content=soup.find(id='js_content') soup2=BeautifulSoup((str(content)),"html.parser") soup2.div['style']='visibility: visible;' html=str(soup2) pattern=r'http[s]?:\/\/[a-z.A-Z_0-9\/\?=-_-]+' result = findall(pattern, html) # take data-src It is amended as follows src for url in result: html=html.replace('data-src="'+url+'"','src="'+url+'"') return html# Upload pictures to the server def download_pic(content): pic_path= 'pic/' + str(path)+ '/' if not os.path.exists(pic_path): os.makedirs(pic_path) # Use regular expressions to find links to all images that need to be downloaded pattern=r'http[s]?:\/\/[a-z.A-Z_0-9\/\?=-_-]+' pic_list = findall(pattern, content) for index, item in enumerate(pic_list,1): count=1 flag=True pic_url=str(item) while flag and count<=10: try: data=requests.get(pic_url); if pic_url.find('png')>0: file_name = str(index)+'.png' elif pic_url.find('gif')>0: file_name=str(index)+'.gif' else: file_name=str(index)+'.jpg' with open( pic_path + file_name,"wb") as f: f.write(data.content) # Replace picture links with local links content = content.replace(pic_url, pic_path + file_name) flag = False print(' Downloaded page ' + str(index) +' A picture .') count += 1 time.sleep(1) except: count+=1 time.sleep(1) if count>10: print(" Download error :",pic_url) return contentdef get_link(dir): link = [] with open(dir,'r') as file_to_read: while True: line = file_to_read.readline() if not line: break line = line.strip('\n') link.append(line) return linkpath = 'link.txt'linklist = get_link(path)print(linklist)s = len(linklist)if __name__ == "__main__": # obtain html input_flag=True while input_flag:# for j in range(0,s):# pic = str(j) j = 1 for i in linklist: weixin_url = i path = j j += 1 #weixin_url=input() re=findall(r'http[s]?:\/\/mp.weixin.qq.com\/s\/[0-9a-zA-Z_]+',weixin_url) if len(re)<=0: print(" Wrong link , Please re-enter !") else: input_flag=False content=get_weixin_html(weixin_url) content=download_pic(content) # Save to local with open(weixin_title+'.txt','w+',encoding="utf-8") as f: f.write(content) with open(weixin_title+'.html','w+',encoding="utf-8") as f: f.write(content) print() print(" title :《"+weixin_title+"》") print(" Release time :"+weixin_time) Four 、Python Regular expressions match date and time import refrom datetime import datetimetest_date = ' What's Xiao Ming's birthday 2016-12-12 14:34, Xiao Zhang's birthday is 2016-12-21 11:34 .'test_datetime = ' What's Xiao Ming's birthday 2016-12-12 14:34,. Xiao Qing's birthday is 2016-12-21 11:34, How lovely .'# datemat = re.search(r"(\d{4}-\d{1,2}-\d{1,2})",test_date)print mat.groups()# ('2016-12-12',)print mat.group(0)# 2016-12-12date_all = re.findall(r"(\d{4}-\d{1,2}-\d{1,2})",test_date)for item in date_all: print item# 2016-12-12# 2016-12-21# datetimemat = re.search(r"(\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2})",test_datetime)print mat.groups()# ('2016-12-12 14:34',)print mat.group(0)# 2016-12-12 14:34date_all = re.findall(r"(\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2})",test_datetime)for item in date_all: print item# 2016-12-12 14:34# 2016-12-21 11:34## Valid time # Dates like this 2016-12-35 It can also be matched to . Test the following .test_err_date = ' Dates like this 2016-12-35 It can also be matched to . Test the following .'print re.search(r"(\d{4}-\d{1,2}-\d{1,2})",test_err_date).group(0)# 2016-12-35# You can add a judgment def validate(date_text): try: if date_text != datetime.strptime(date_text, "%Y-%m-%d").strftime('%Y-%m-%d'): raise ValueError return True except ValueError: # raise ValueError(" The error is date format or date , The format is year - month - Japan ") return Falseprint validate(re.search(r"(\d{4}-\d{1,2}-\d{1,2})",test_err_date).group(0))# false# Other formats match . Such as 2016-12-24 And 2016/12/24 Date format for .date_reg_exp = re.compile('\d{4}[-/]\d{2}[-/]\d{2}')test_str= """ Christmas Eve Christmas 2016-12-24 The date of last year 2015/12/24 It's different . """# Find all the dates according to the rule and return matches_list=date_reg_exp.findall(test_str)# List and print matching dates for match in matches_list: print match# 2016-12-24# 2015/12/24That's all Python Quickly save the details of the pictures in the wechat official account articles , More about Python Please pay attention to other related articles of software development network for the information of saving article pictures !
 Java+python+nodejs+vue postgraduate entrance examination information query system
Java+python+nodejs+vue postgraduate entrance examination information query system
The system is divided into stu
 Set up http file server (implemented by Python and nginx respectively)
Set up http file server (implemented by Python and nginx respectively)
Use Python3Windows and Linux A